Is Agentic RAG worth it? An experimental comparison of RAG approaches
作者: Pietro Ferrazzi, Milica Cvjeticanin, Alessio Piraccini, Davide Giannuzzi
分类: cs.CL
发布日期: 2026-01-12
💡 一句话要点
对比增强型与Agentic RAG:探究不同RAG方法在实际应用中的权衡
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 RAG Agentic RAG 增强型RAG 大型语言模型 LLM 实验评估
📋 核心要点
- 传统RAG系统存在检索质量不高、处理范围外查询能力弱等问题,限制了其应用效果。
- 论文对比研究了增强型RAG和Agentic RAG,后者利用LLM的自我反思能力来编排整个流程。
- 通过实验评估,论文揭示了两种RAG范例在不同场景下的优劣,为实际应用提供选择依据。
📝 摘要(中文)
检索增强生成(RAG)系统通常由生成器和检索组件组成,后者从知识库中提取文本上下文以回答用户查询。然而,这种基本实现存在一些局限性,包括噪声或次优检索、对超出范围查询的检索误用、弱查询-文档匹配以及与生成器相关的可变性或成本。这些缺点促使了“增强型”RAG的开发,其中引入专用模块来解决工作流程中的特定弱点。最近,大型语言模型(LLM)日益增长的自我反思能力催生了一种新的范例,我们称之为“Agentic” RAG。在这种方法中,LLM协调整个过程——决定执行哪些操作、何时执行以及是否迭代——从而减少对固定、手动设计的模块的依赖。尽管这两种范例都被迅速采用,但在何种条件下哪种方法更可取仍不清楚。在这项工作中,我们对增强型和Agentic RAG在多种场景和维度上进行了广泛的、经验驱动的评估。我们的结果为这两种范例之间的权衡提供了实用的见解,为在考虑成本和性能的情况下,为实际应用选择最有效的RAG设计提供了指导。
🔬 方法详解
问题定义:现有RAG系统在处理复杂查询和噪声数据时表现不佳,需要人工干预进行优化。增强型RAG通过引入特定模块来解决这些问题,但仍然依赖于预定义的流程。Agentic RAG旨在利用LLM的自主决策能力,动态调整检索和生成过程,但其有效性尚未得到充分验证。
核心思路:论文的核心思路是通过实验对比增强型RAG和Agentic RAG,评估它们在不同场景下的性能和成本。通过分析实验结果,揭示两种方法的优缺点,为实际应用提供选择依据。Agentic RAG的核心在于利用LLM作为智能体,自主决定检索策略和生成方式,从而提高RAG系统的灵活性和适应性。
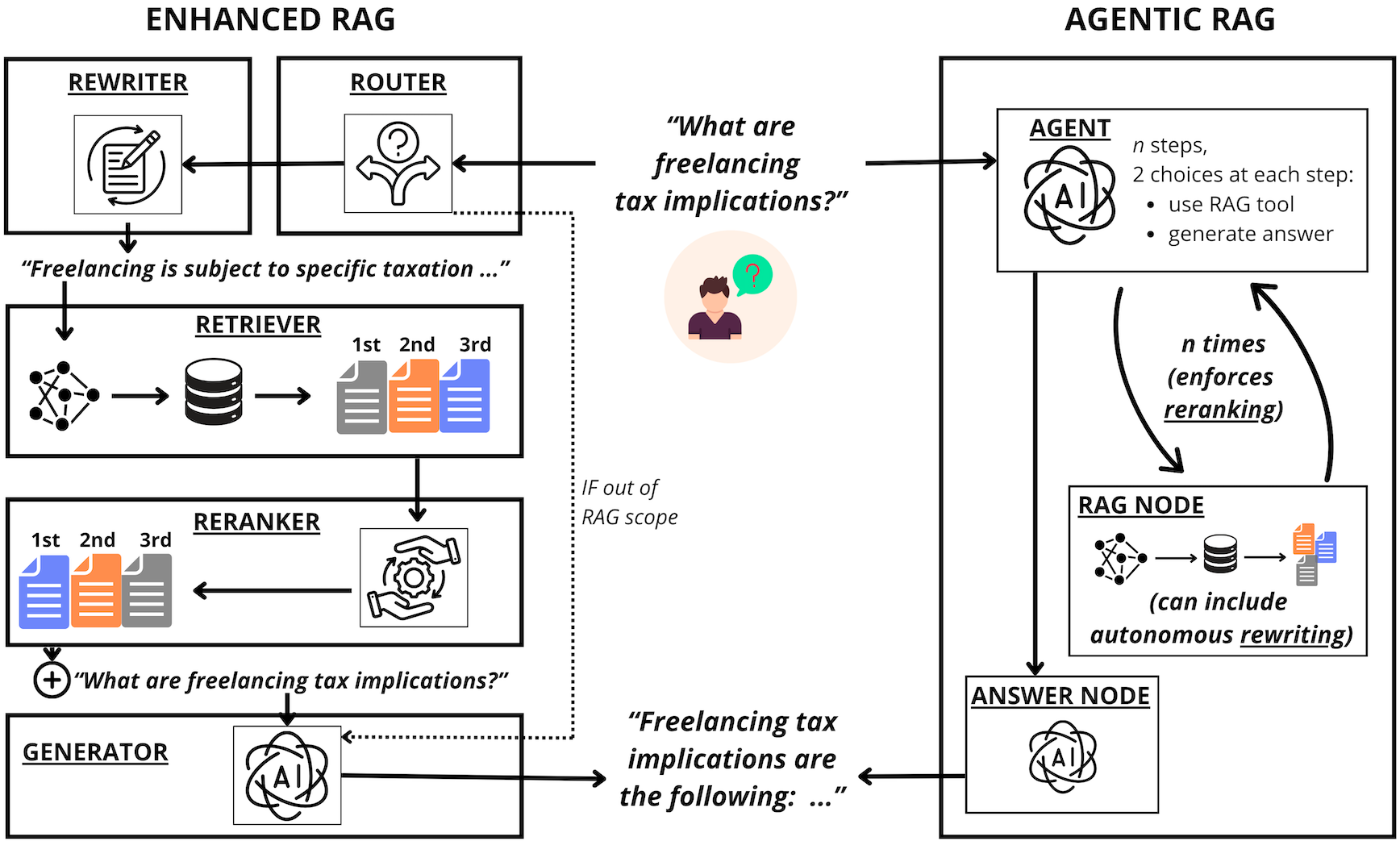
技术框架:论文构建了一个实验框架,用于评估增强型RAG和Agentic RAG。增强型RAG采用预定义的模块化流程,包括查询重写、文档检索、排序和生成等步骤。Agentic RAG则使用LLM作为控制器,根据用户查询和上下文信息,动态选择和执行不同的操作,例如检索、阅读、推理和生成。
关键创新:论文的关键创新在于对Agentic RAG进行了系统的实验评估,并将其与增强型RAG进行了对比。通过实验,论文揭示了Agentic RAG在处理复杂查询和噪声数据方面的优势,以及在成本和可控性方面的挑战。此外,论文还提出了选择不同RAG方法的指导原则,为实际应用提供了参考。
关键设计:实验中,论文使用了多个数据集和评估指标,包括准确率、召回率、F1值和生成质量等。对于Agentic RAG,论文探索了不同的LLM和提示工程策略,以优化其性能。同时,论文还考虑了成本因素,例如API调用次数和计算资源消耗。
🖼️ 关键图片

📊 实验亮点
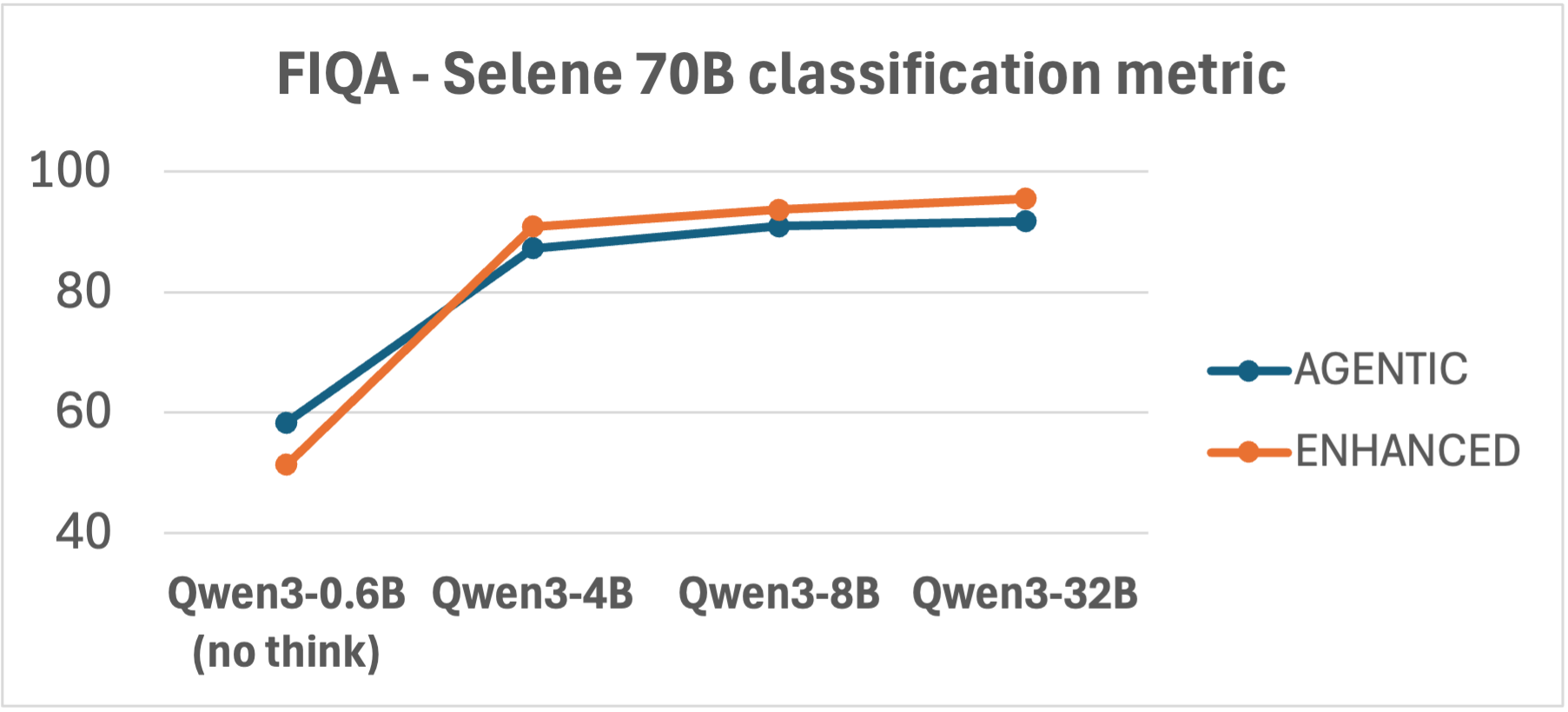
实验结果表明,Agentic RAG在处理复杂查询和噪声数据时,性能优于增强型RAG。但在简单场景下,增强型RAG的效率更高,成本更低。论文还发现,Agentic RAG的性能受到LLM的选择和提示工程的影响,需要仔细调整。
🎯 应用场景
该研究成果可应用于智能客服、知识问答、文档摘要等领域。通过选择合适的RAG方法,可以提高问答系统的准确性和效率,降低运营成本。未来,Agentic RAG有望在更复杂的任务中发挥作用,例如自动化报告生成、智能决策支持等。
📄 摘要(原文)
Retrieval-Augmented Generation (RAG) systems are usually defined by the combination of a generator and a retrieval component that extracts textual context from a knowledge base to answer user queries. However, such basic implementations exhibit several limitations, including noisy or suboptimal retrieval, misuse of retrieval for out-of-scope queries, weak query-document matching, and variability or cost associated with the generator. These shortcomings have motivated the development of "Enhanced" RAG, where dedicated modules are introduced to address specific weaknesses in the workflow. More recently, the growing self-reflective capabilities of Large Language Models (LLMs) have enabled a new paradigm, which we refer to as "Agentic" RAG. In this approach, the LLM orchestrates the entire process-deciding which actions to perform, when to perform them, and whether to iterate-thereby reducing reliance on fixed, manually engineered modules. Despite the rapid adoption of both paradigms, it remains unclear which approach is preferable under which conditions. In this work, we conduct an extensive, empirically driven evaluation of Enhanced and Agentic RAG across multiple scenarios and dimensions. Our results provide practical insights into the trade-offs between the two paradigms, offering guidance on selecting the most effective RAG design for real-world applications, considering both costs and performance.