Exploring the Meta-level Reasoning of Large Language Models via a Tool-based Multi-hop Tabular Question Answering Task
作者: Nick Ferguson, Alan Bundy, Kwabena Nuamah
分类: cs.CL
发布日期: 2026-01-12
💡 一句话要点
提出基于工具的多跳表格问答任务,探索大语言模型的元层次推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 元层次推理 表格问答 工具调用 多跳推理
📋 核心要点
- 现有大语言模型推理能力研究缺乏结构化方法,难以区分元层次和对象层次推理。
- 设计基于工具的多跳表格问答任务,通过分析工具选择评估LLM的元层次推理能力。
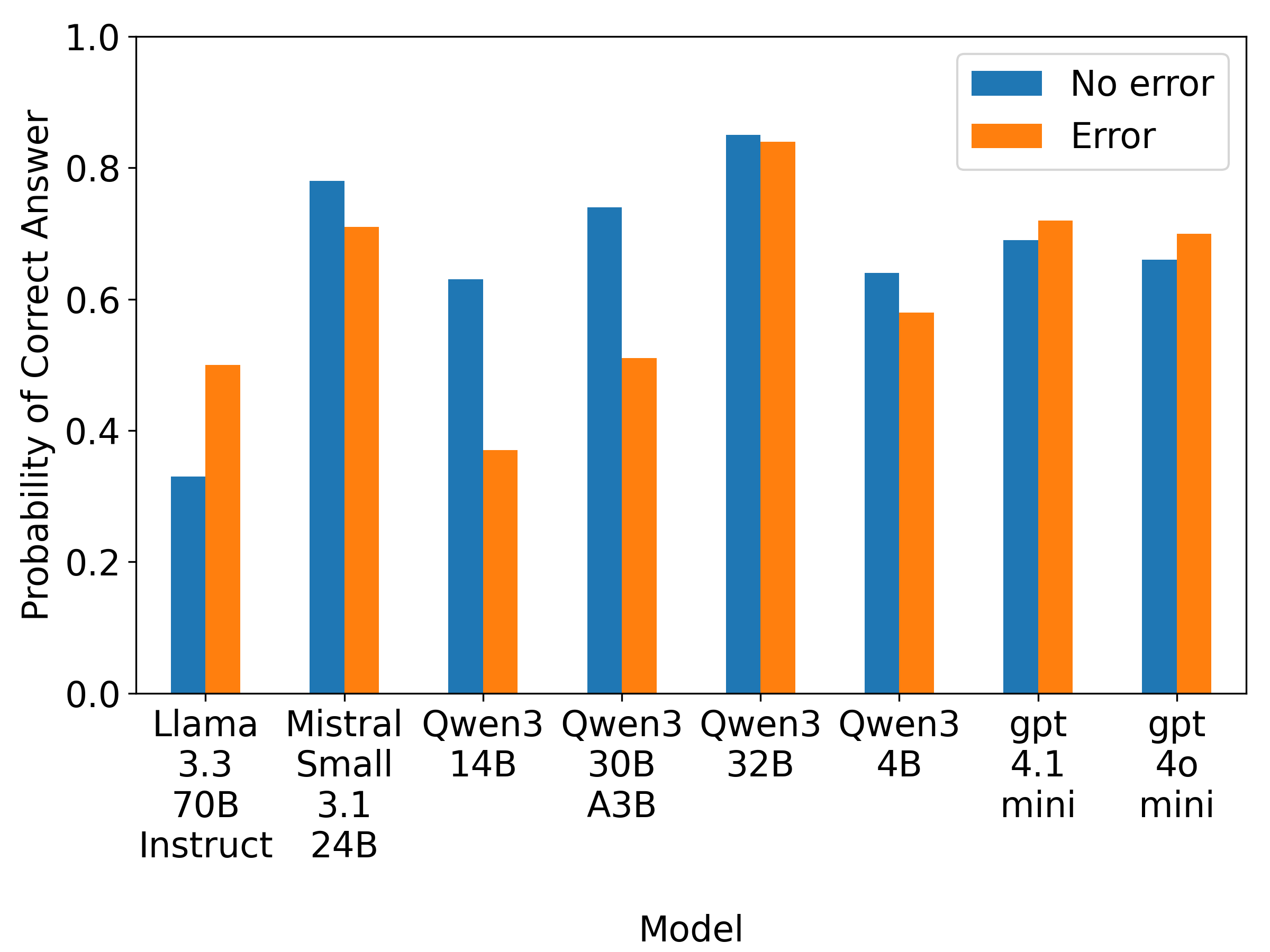
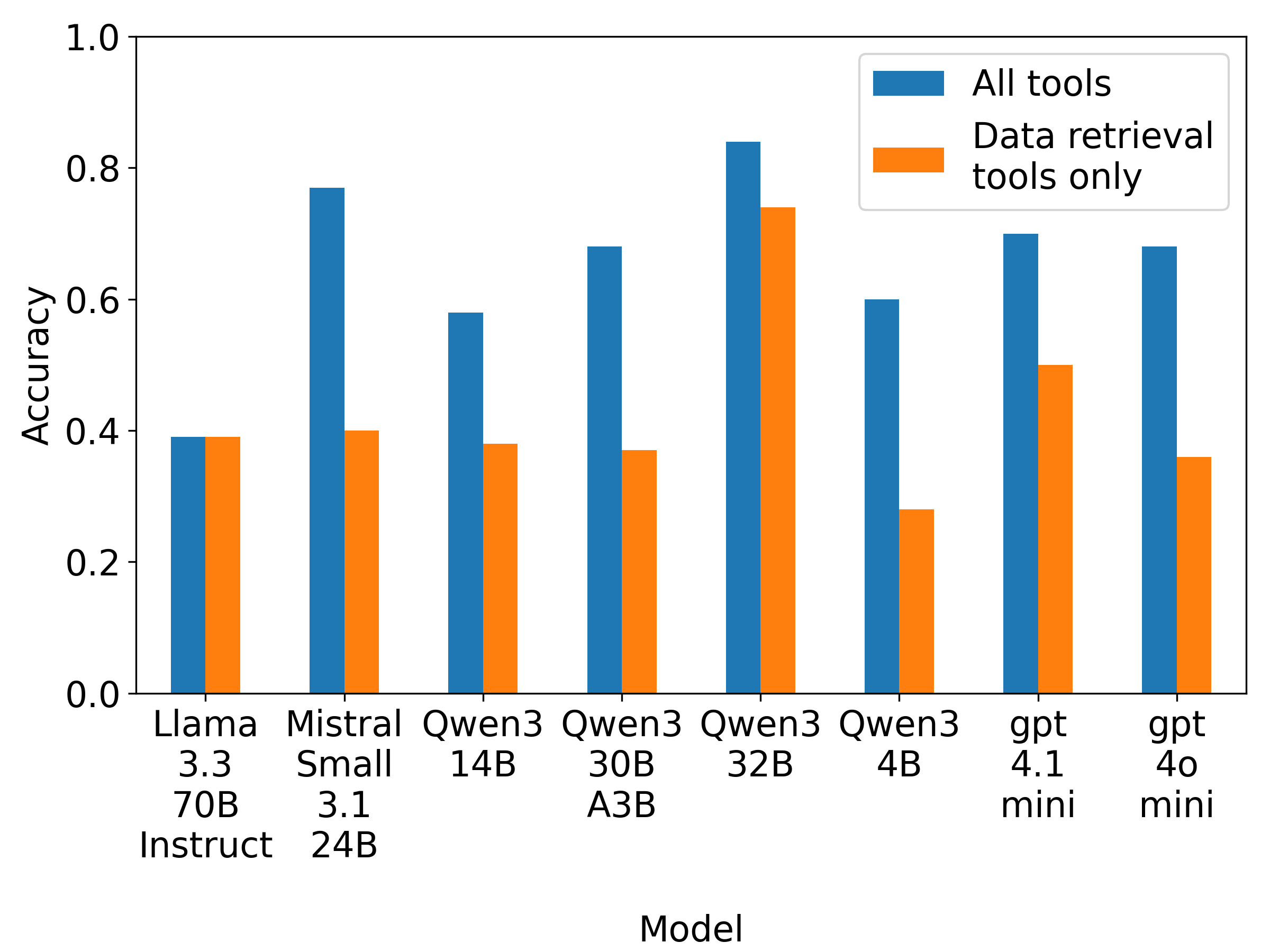
- 实验表明LLM在元层次推理方面表现良好,但在任务理解和计算能力方面存在不足。
📝 摘要(中文)
本文着重研究大语言模型(LLM)的“推理”能力,区分了元层次推理(解决任务所需的中间步骤的推理过程)和对象层次推理(上述步骤的低级执行)。设计了一个新的问答任务,该任务基于不同国家在不同年份的地缘政治指标值。问题需要分解为中间步骤、数据检索以及对数据的数学运算。通过检查LLM选择回答问题的适当工具来分析LLM的元层次推理能力。为了更深入地分析LLM,超越最终答案的准确性,我们的任务包含“必要操作”,我们可以将LLM的工具调用输出与之进行比较,以推断推理能力的强度。我们发现LLM在我们的任务中表现出良好的元层次推理,但在任务理解的某些方面存在缺陷。我们发现n-shot prompting对准确性几乎没有影响;遇到的错误消息通常不会降低性能;并为LLM较差的计算能力提供了额外的证据。最后,我们讨论了我们的发现对其他任务领域的推广和限制。
🔬 方法详解
问题定义:论文旨在解决如何更有效地评估和理解大语言模型(LLM)的推理能力,特别是元层次推理能力的问题。现有方法通常关注最终答案的准确性,而忽略了中间推理步骤的质量。此外,缺乏能够区分元层次推理(关于推理步骤的推理)和对象层次推理(实际执行步骤)的任务和评估指标。现有方法难以深入分析LLM在复杂推理任务中的优势和不足。
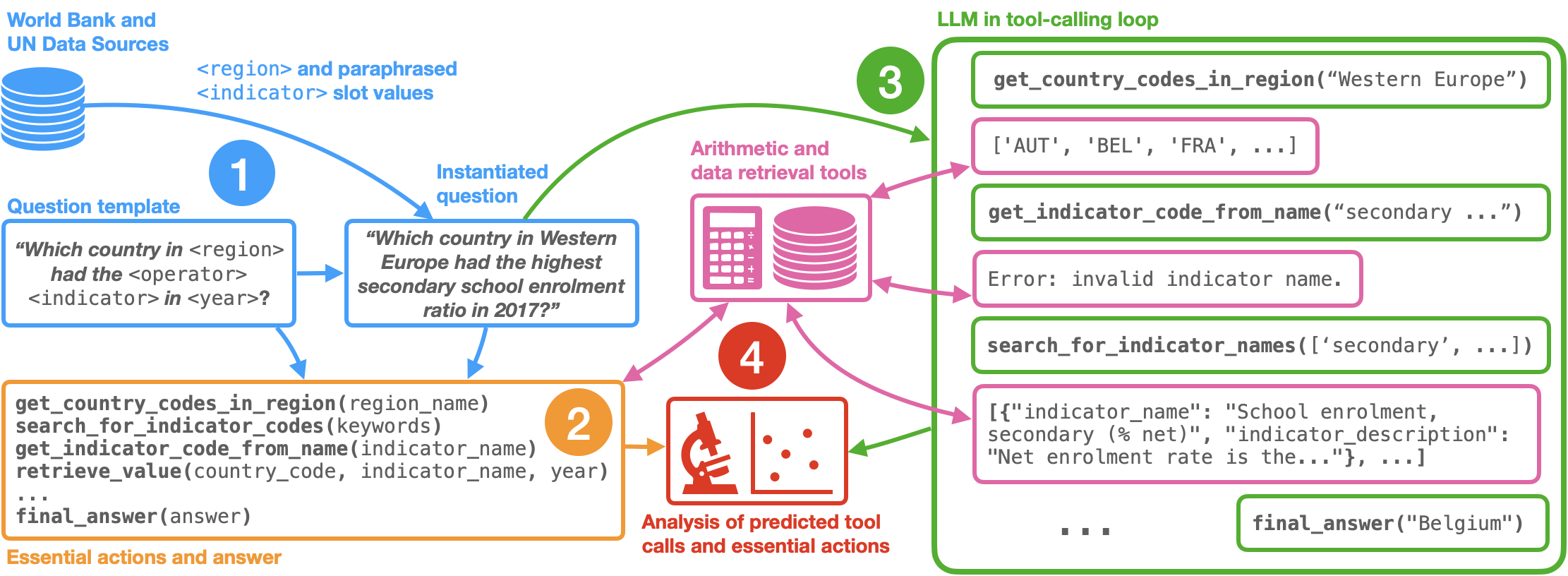
核心思路:论文的核心思路是通过设计一个需要多步推理和工具调用的表格问答任务,来显式地考察LLM的元层次推理能力。通过分析LLM选择的工具和执行的步骤,可以推断其对任务的理解程度和推理策略。这种方法不仅关注最终答案的正确性,更关注推理过程的合理性和效率。
技术框架:该研究的技术框架主要包含以下几个部分:1) 设计一个基于地缘政治指标的表格问答数据集,问题需要分解为多个中间步骤,包括数据检索和数学运算。2) 定义“必要操作”,即解决问题所需的关键工具调用序列。3) 使用LLM(例如,GPT-3)来回答问题,并记录其工具调用序列。4) 将LLM的工具调用序列与“必要操作”进行比较,评估其元层次推理能力。5) 分析LLM在不同类型的错误和prompting策略下的表现。
关键创新:该论文的关键创新在于:1) 提出了一个新颖的、基于工具的多跳表格问答任务,能够显式地考察LLM的元层次推理能力。2) 定义了“必要操作”的概念,为评估LLM的推理过程提供了一个客观的标准。3) 通过实验分析,揭示了LLM在元层次推理方面的优势和不足,例如,在工具选择方面表现良好,但在任务理解和计算能力方面存在缺陷。
关键设计:该研究的关键设计包括:1) 数据集的构建,需要确保问题具有一定的复杂性,并且需要多个中间步骤才能解决。2) “必要操作”的定义,需要仔细分析每个问题,确定最有效的工具调用序列。3) 实验设置,包括选择合适的LLM、prompting策略和评估指标。论文还研究了n-shot prompting对性能的影响,以及错误信息对LLM推理的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM在工具选择方面表现出良好的元层次推理能力,但任务理解和计算能力方面存在不足。N-shot prompting对准确率影响不大,错误信息通常不会降低性能。该研究为LLM的推理能力评估提供了新的视角和方法,并揭示了LLM在复杂推理任务中的潜在问题。
🎯 应用场景
该研究成果可应用于开发更可靠、可解释的人工智能系统,尤其是在需要复杂推理和决策的领域,如金融分析、医疗诊断和智能客服。通过提升LLM的元层次推理能力,可以使其更好地理解任务需求、选择合适的工具和策略,从而提高问题解决的效率和准确性。此外,该研究方法也可用于评估和改进其他类型的AI模型。
📄 摘要(原文)
Recent advancements in Large Language Models (LLMs) are increasingly focused on "reasoning" ability, a concept with many overlapping definitions in the LLM discourse. We take a more structured approach, distinguishing meta-level reasoning (denoting the process of reasoning about intermediate steps required to solve a task) from object-level reasoning (which concerns the low-level execution of the aforementioned steps.) We design a novel question answering task, which is based around the values of geopolitical indicators for various countries over various years. Questions require breaking down into intermediate steps, retrieval of data, and mathematical operations over that data. The meta-level reasoning ability of LLMs is analysed by examining the selection of appropriate tools for answering questions. To bring greater depth to the analysis of LLMs beyond final answer accuracy, our task contains 'essential actions' against which we can compare the tool call output of LLMs to infer the strength of reasoning ability. We find that LLMs demonstrate good meta-level reasoning on our task, yet are flawed in some aspects of task understanding. We find that n-shot prompting has little effect on accuracy; error messages encountered do not often deteriorate performance; and provide additional evidence for the poor numeracy of LLMs. Finally, we discuss the generalisation and limitation of our findings to other task domains.