Adaptive Layer Selection for Layer-Wise Token Pruning in LLM Inference
作者: Rei Taniguchi, Yuyang Dong, Makoto Onizuka, Chuan Xiao
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-01-12
备注: Source code is available at https://github.com/TANIGUCHIREI/ASL
💡 一句话要点
提出ASL自适应选择LLM推理中逐层token剪枝的层,提升KV缓存效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 KV缓存 Token剪枝 自适应层选择 LLM推理
📋 核心要点
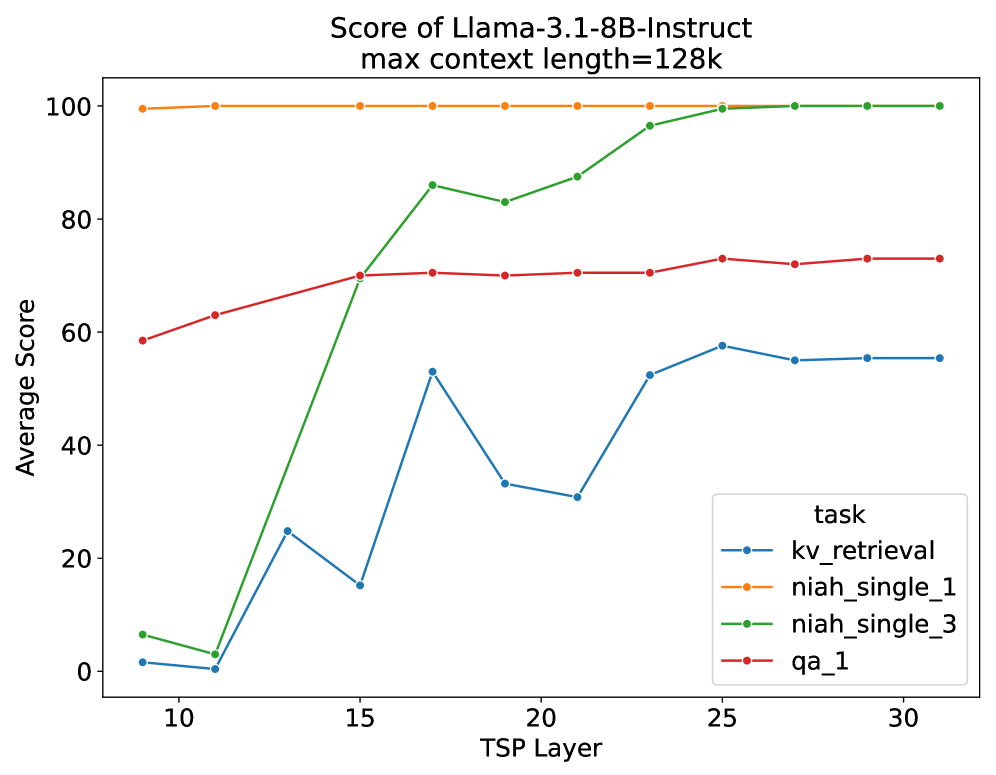
- 现有逐层token剪枝方法依赖预定义层,缺乏灵活性,导致任务间性能差异大,尤其在复杂任务中精度下降。
- ASL利用注意力分数的token排序方差,自适应选择剪枝层,无需训练,平衡不同任务性能并满足KV预算。
- 实验表明,ASL在精度上优于现有方法,同时保持了解码速度和KV缓存缩减,适用于多种基准测试。
📝 摘要(中文)
由于大型语言模型(LLM)的普及,LLM推理的关键-值(KV)缓存缩减受到了广泛关注。在近年来提出的众多方法中,逐层token剪枝方法是最受欢迎的方案之一,它选择特定层中的一部分token保留在KV缓存中,并剪除其他token。这些方法主要采用一组预定义的层进行token选择,这种设计不够灵活,因为精度在不同任务中差异很大,并且在KV检索等较难的任务中会下降。本文提出了ASL,一种无需训练的方法,它利用注意力分数排序的token等级的方差,自适应地选择用于KV缓存缩减的选择层。所提出的方法在满足用户指定的KV预算要求的同时,平衡了不同任务的性能。ASL在预填充阶段运行,并且可以与现有的KV缓存缩减方法(如SnapKV)联合使用,以优化解码阶段。通过在InfiniteBench、RULER和NIAH基准上的评估,我们表明,配备一次性token选择(即在一个层选择token并将其传播到更深层)的ASL在精度方面优于最先进的逐层token选择方法,同时保持了解码速度和KV缓存缩减。
🔬 方法详解
问题定义:论文旨在解决大型语言模型推理过程中,KV缓存占用过高的问题。现有的逐层token剪枝方法依赖于预先设定的层进行token选择,这种静态选择策略无法适应不同任务和不同层的token重要性差异,导致在某些任务上性能显著下降,尤其是在需要精确KV检索的任务中。
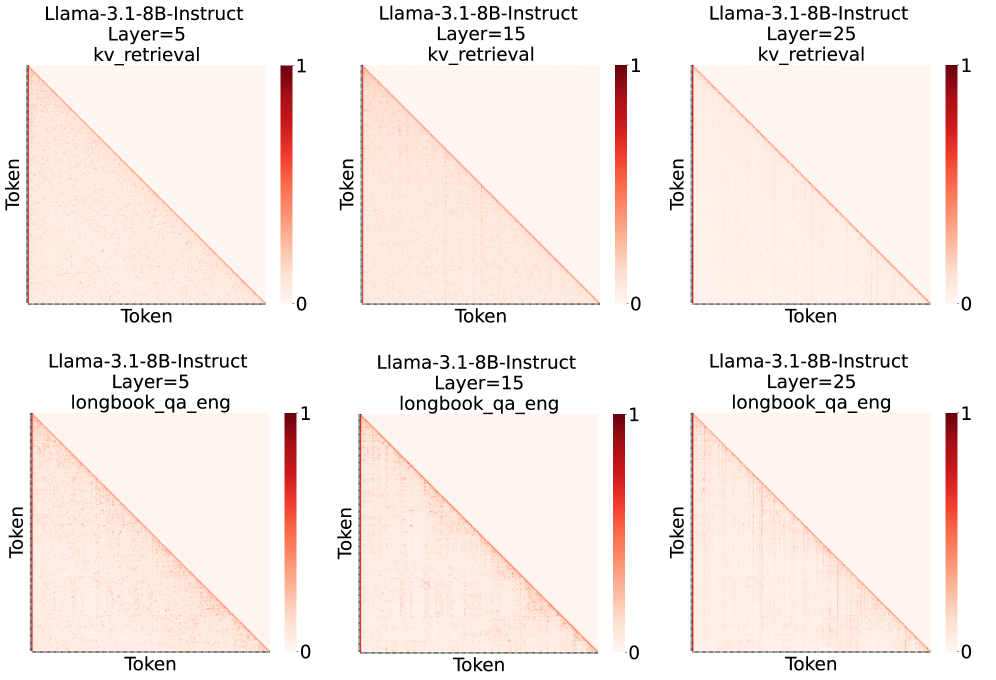
核心思路:ASL的核心思路是根据每一层token的重要性动态地选择进行token剪枝的层。它观察到不同层token的重要性分布存在差异,并利用注意力分数排序的token等级的方差来衡量这种差异。方差越大,说明该层token的重要性区分度越高,越适合进行token剪枝。
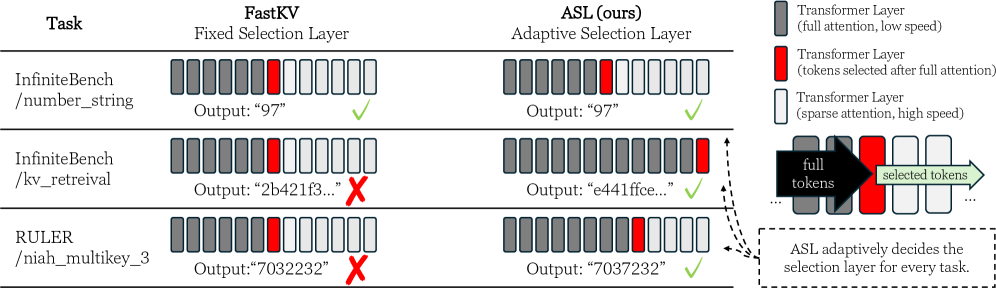
技术框架:ASL主要在LLM推理的预填充阶段运行。首先,计算每一层token的注意力分数,并根据分数对token进行排序。然后,计算每一层排序后token等级的方差。根据用户设定的KV缓存预算,选择方差最大的层作为进行token剪枝的层。最后,在选定的层进行一次性token选择,即选择一部分token保留,并将这些token的信息传递到更深的层。ASL可以与现有的KV缓存缩减方法(如SnapKV)结合使用,进一步优化解码阶段。
关键创新:ASL的关键创新在于提出了一种无需训练的自适应层选择方法,能够根据token的重要性动态地选择进行token剪枝的层。与现有方法相比,ASL不需要预先设定剪枝层,能够更好地适应不同任务和不同层的token重要性差异,从而提高整体性能。
关键设计:ASL的关键设计包括:1) 使用注意力分数作为token重要性的度量;2) 使用token等级的方差来衡量token重要性的区分度;3) 采用一次性token选择策略,减少计算复杂度。ASL没有引入额外的可训练参数,因此无需训练,可以直接应用于现有的LLM模型。
🖼️ 关键图片
📊 实验亮点
在InfiniteBench、RULER和NIAH基准测试中,ASL在精度上优于最先进的逐层token选择方法。例如,在某些任务上,ASL的精度提升超过了5%,同时保持了解码速度和KV缓存缩减。这些结果表明,ASL能够有效地平衡不同任务的性能,并满足用户指定的KV缓存预算要求。
🎯 应用场景
ASL可广泛应用于各种需要降低LLM推理成本的场景,例如移动设备上的LLM部署、低功耗边缘计算设备上的LLM应用、以及大规模LLM服务的部署。通过自适应地选择剪枝层,ASL能够在保证性能的同时,显著降低KV缓存的需求,从而降低推理成本,加速LLM的普及。
📄 摘要(原文)
Due to the prevalence of large language models (LLMs), key-value (KV) cache reduction for LLM inference has received remarkable attention. Among numerous works that have been proposed in recent years, layer-wise token pruning approaches, which select a subset of tokens at particular layers to retain in KV cache and prune others, are one of the most popular schemes. They primarily adopt a set of pre-defined layers, at which tokens are selected. Such design is inflexible in the sense that the accuracy significantly varies across tasks and deteriorates in harder tasks such as KV retrieval. In this paper, we propose ASL, a training-free method that adaptively chooses the selection layer for KV cache reduction, exploiting the variance of token ranks ordered by attention score. The proposed method balances the performance across different tasks while meeting the user-specified KV budget requirement. ASL operates during the prefilling stage and can be jointly used with existing KV cache reduction methods such as SnapKV to optimize the decoding stage. By evaluations on the InfiniteBench, RULER, and NIAH benchmarks, we show that equipped with one-shot token selection, where tokens are selected at a layer and propagated to deeper layers, ASL outperforms state-of-the-art layer-wise token selection methods in accuracy while maintaining decoding speed and KV cache reduction.