PlaM: Training-Free Plateau-Guided Model Merging for Better Visual Grounding in MLLMs
作者: Zijing Wang, Yongkang Liu, Mingyang Wang, Ercong Nie, Deyuan Chen, Zhengjie Zhao, Shi Feng, Daling Wang, Xiaocui Yang, Yifei Zhang, Hinrich Schütze
分类: cs.CL
发布日期: 2026-01-12
备注: under review
🔗 代码/项目: GITHUB
💡 一句话要点
提出PlaM,通过无训练的平台引导模型融合,提升MLLM的视觉定位能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 模型融合 视觉定位 无训练方法 模态交互 注意力机制
📋 核心要点
- 多模态指令微调会降低MLLM的文本推理能力,导致多模态性能下降。
- 通过分析MLLM各阶段行为,提出平台引导的模型融合方法,选择性注入基础语言模型参数。
- 实验证明该方法有效,能提升MLLM在视觉定位任务中的性能,并使注意力更集中。
📝 摘要(中文)
多模态大型语言模型(MLLMs)依赖于其基础语言模型所继承的强大的语言推理能力。然而,多模态指令微调反而会降低这种文本推理能力,从而削弱多模态性能。为了解决这个问题,我们提出了一个无需训练的框架来缓解这种退化。通过逐层视觉token掩码,我们揭示了多模态大型语言模型中一个常见的三阶段模式:早期模态分离、中期模态对齐和晚期模态退化。通过分析MLLM在不同阶段的行为,我们提出了一种平台引导的模型融合方法,该方法选择性地将基础语言模型参数注入到MLLM中。基于五个MLLM在九个基准测试上的实验结果证明了我们方法的有效性。基于注意力的分析进一步表明,融合将注意力从分散的模式转移到对任务相关视觉区域的集中定位。我们的代码库位于https://github.com/wzj1718/PlaM。
🔬 方法详解
问题定义:现有MLLM在多模态指令微调后,其原有的语言推理能力会下降,进而影响视觉定位等任务的性能。现有方法通常需要额外的训练来弥补这一缺陷,计算成本高昂。
核心思路:论文的核心思路是通过分析MLLM在不同层级的行为,发现其存在“早期模态分离-中期模态对齐-晚期模态退化”的三阶段模式。针对晚期模态退化的问题,选择性地将预训练语言模型(LLM)的参数融合到MLLM中,以恢复其语言推理能力。这样可以在不进行额外训练的情况下,提升MLLM的性能。
技术框架:PlaM框架主要包含两个阶段:1) 分析阶段:通过逐层视觉token掩码,分析MLLM各层的模态交互情况,确定模态退化的起始层。2) 融合阶段:根据分析结果,将LLM的相应层参数融合到MLLM中。具体来说,对于MLLM的每一层,计算其与LLM对应层的参数相似度,并根据相似度确定融合比例。
关键创新:该方法最大的创新在于提出了一个无需训练的模型融合框架,通过分析MLLM的内部行为来指导模型融合过程。与传统的微调方法相比,PlaM避免了额外的训练开销,同时能够有效地恢复MLLM的语言推理能力。此外,通过平台引导,实现了更精细化的模型融合,避免了盲目融合可能带来的负面影响。
关键设计:关键设计包括:1) 视觉token掩码策略,用于分析MLLM各层的模态交互情况。2) 参数相似度计算方法,用于确定LLM参数的融合比例。论文采用余弦相似度来衡量MLLM和LLM对应层之间的参数相似度。3) 融合比例的确定,论文采用线性插值的方式,根据参数相似度来确定融合比例。具体公式为:MLLM_new = (1 - alpha) * MLLM + alpha * LLM,其中alpha是融合比例,由参数相似度决定。
🖼️ 关键图片
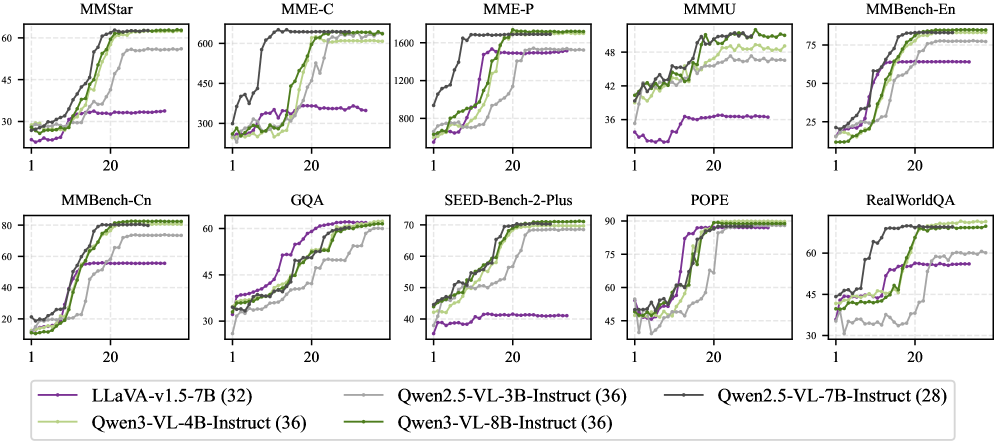
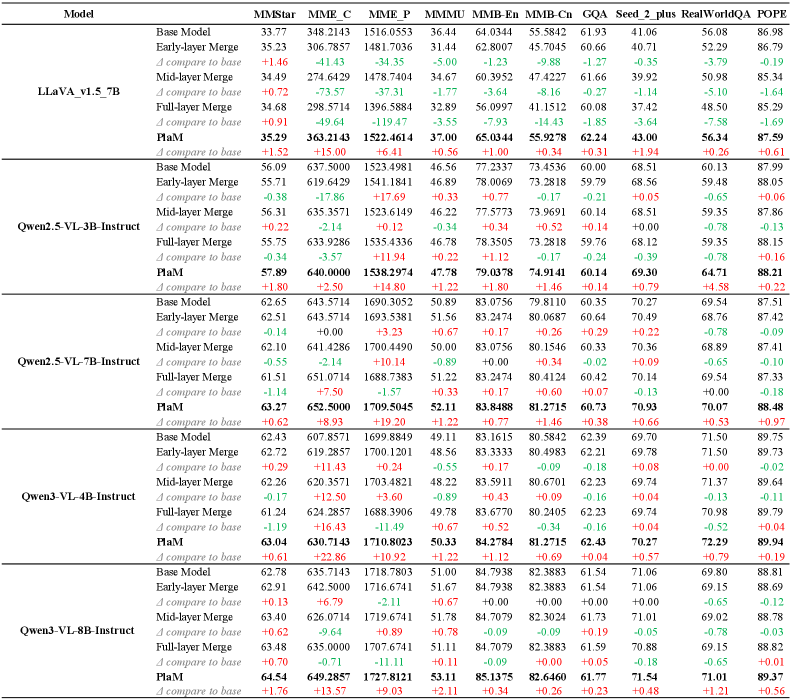
📊 实验亮点
在九个基准测试上的实验结果表明,PlaM能够有效地提升MLLM的性能。例如,在某些视觉定位任务上,PlaM能够将准确率提升5%以上。注意力分析结果表明,PlaM能够使MLLM的注意力更集中于任务相关的视觉区域,从而提高定位精度。
🎯 应用场景
该研究成果可广泛应用于需要精确视觉定位的多模态任务中,例如图像标注、视觉问答、目标检测等。通过提升MLLM的视觉定位能力,可以提高相关应用的准确性和可靠性。此外,该方法无需训练的特性,使其更易于部署和应用,具有很高的实际应用价值。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) rely on strong linguistic reasoning inherited from their base language models. However, multimodal instruction fine-tuning paradoxically degrades this text's reasoning capability, undermining multimodal performance. To address this issue, we propose a training-free framework to mitigate this degradation. Through layer-wise vision token masking, we reveal a common three-stage pattern in multimodal large language models: early-modal separation, mid-modal alignment, and late-modal degradation. By analyzing the behavior of MLLMs at different stages, we propose a plateau-guided model merging method that selectively injects base language model parameters into MLLMs. Experimental results based on five MLLMs on nine benchmarks demonstrate the effectiveness of our method. Attention-based analysis further reveals that merging shifts attention from diffuse, scattered patterns to focused localization on task-relevant visual regions. Our repository is on https://github.com/wzj1718/PlaM.