Proof of Time: A Benchmark for Evaluating Scientific Idea Judgments
作者: Bingyang Ye, Shan Chen, Jingxuan Tu, Chen Liu, Zidi Xiong, Samuel Schmidgall, Danielle S. Bitterman
分类: cs.CL, cs.AI
发布日期: 2026-01-12
备注: under review
💡 一句话要点
提出PoT:一个评估科学研究想法判断质量的半可验证基准框架。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 科学研究评估 大型语言模型 基准框架 半可验证 代理研究 时间分割 下游信号
📋 核心要点
- 现有方法缺乏可扩展的方式来评估大型语言模型对科学研究想法的判断质量。
- PoT框架通过将科学想法的判断与未来可观察的下游信号联系起来,实现半可验证的评估。
- 实验表明,更高的交互预算通常会提高代理性能,而工具使用的好处取决于具体任务。
📝 摘要(中文)
大型语言模型越来越多地被用于评估和预测研究想法,但我们缺乏可扩展的方法来评估模型对这些科学想法的判断质量。为此,我们引入了PoT,这是一个半可验证的基准框架,它将科学想法的判断与下游信号(例如,引用和研究人员议程的变化)联系起来,这些信号在稍后变得可观察。PoT冻结了离线沙箱中预先设定的证据快照,并要求模型预测截止日期后的结果,从而在获得真实数据时实现可验证的评估,无需详尽的专家标注即可实现可扩展的基准测试,并分析人类与模型之间针对同行评审奖等信号的不一致。此外,PoT还提供了一个受控的测试平台,用于评估科学想法的基于代理的研究判断,在提示消融和预算缩放的情况下,将使用工具的代理与非代理基线进行比较。在跨越四个基准领域的30,000多个实例中,我们发现,与非代理基线相比,更高的交互预算通常会提高代理性能,而工具使用的好处在很大程度上取决于任务。通过将时间分割的、未来可验证的目标与用于工具使用的离线沙箱相结合,PoT支持对代理在面向未来的科学想法判断任务上进行可扩展的评估。
🔬 方法详解
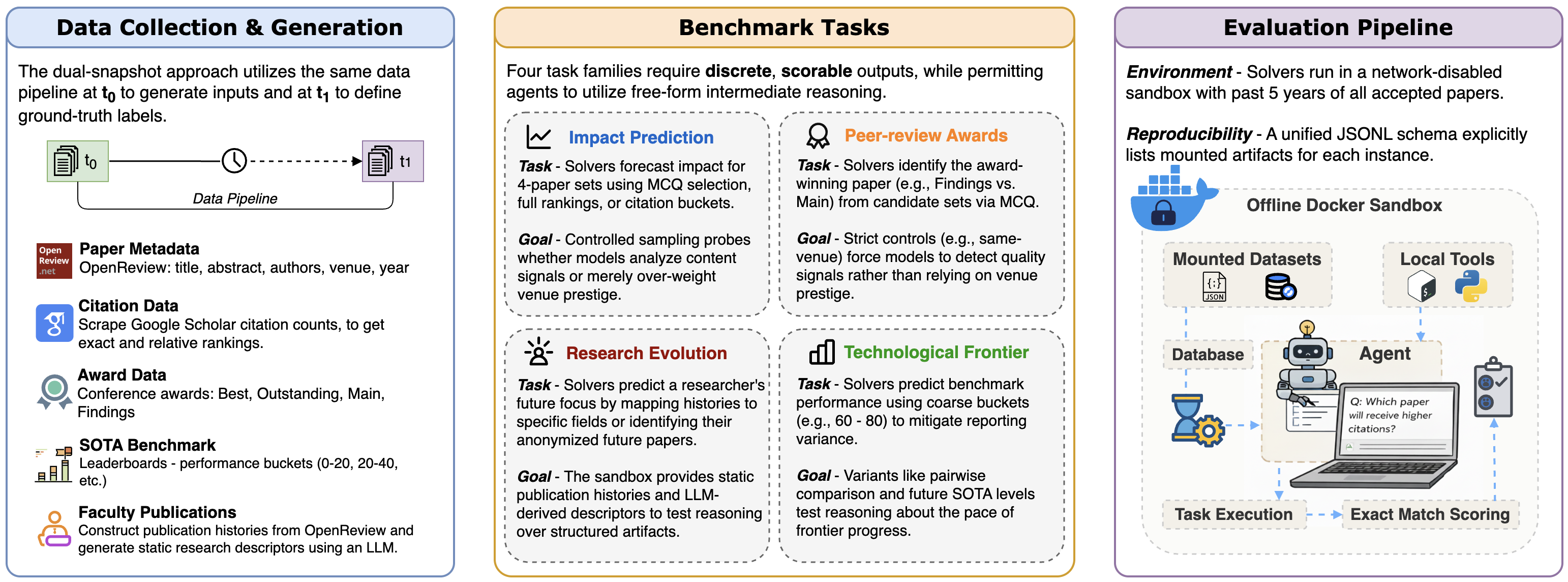
问题定义:现有方法难以有效评估大型语言模型对科学研究想法的判断质量,缺乏可扩展性和可验证性。专家标注成本高昂,难以覆盖大量研究想法。因此,需要一种能够自动、可验证地评估模型判断科学想法质量的框架。
核心思路:PoT的核心思路是利用时间分割的思想,将科学研究想法的判断与未来可观察的下游信号(如引用量、研究方向变化)联系起来。通过冻结截止日期前的证据,并要求模型预测截止日期后的结果,可以实现事后验证,从而避免了对大量专家标注的依赖。
技术框架:PoT框架包含以下主要模块:1) 离线沙箱:用于存储和管理截止日期前的科学研究信息,包括论文、作者、机构等。2) 模型判断模块:使用大型语言模型对给定的科学研究想法进行判断,预测其未来的影响力。3) 结果验证模块:在截止日期后,收集实际的下游信号(如引用量),与模型的预测结果进行比较,从而评估模型的判断质量。4) Agent-based 研究判断模块:比较工具使用代理与非代理基线在提示消融和预算缩放下的表现。
关键创新:PoT的关键创新在于其半可验证的评估机制。通过将科学研究想法的判断与未来可观察的下游信号联系起来,实现了可扩展、自动化的评估,避免了对大量专家标注的依赖。此外,PoT还提供了一个受控的测试平台,用于评估基于代理的研究判断。
关键设计:PoT的关键设计包括:1) 时间分割策略:选择合适的截止日期,以确保有足够的时间收集下游信号。2) 下游信号的选择:选择与科学研究想法质量相关的下游信号,如引用量、研究方向变化等。3) 评估指标:设计合适的评估指标,用于衡量模型预测结果与实际结果之间的差异。4) Agent的工具使用和预算控制:通过控制Agent的工具使用和预算,研究不同策略对判断结果的影响。
🖼️ 关键图片
📊 实验亮点
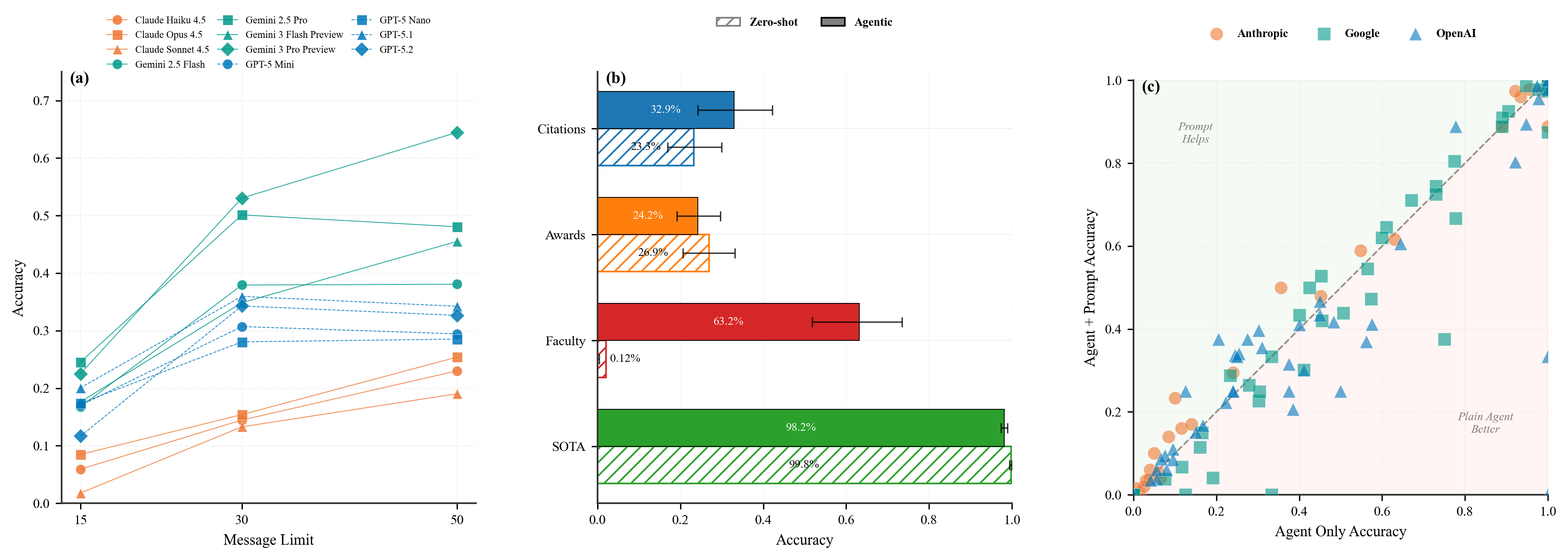
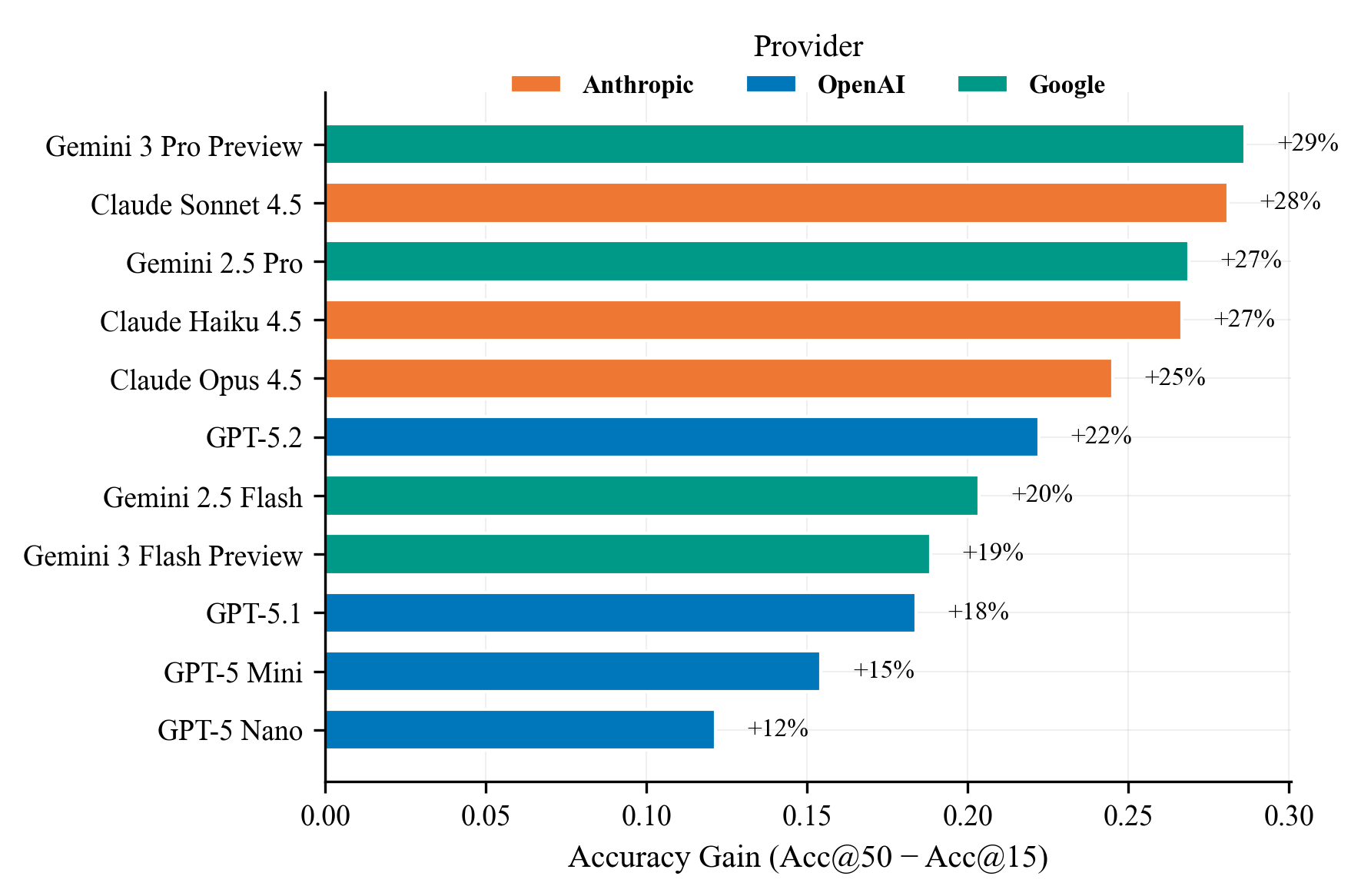
实验结果表明,与非代理基线相比,更高的交互预算通常会提高代理性能。工具使用的好处在很大程度上取决于任务。在跨越四个基准领域的30,000多个实例中进行了评估,证明了PoT框架的可行性和有效性。
🎯 应用场景
PoT框架可用于评估和改进大型语言模型在科学研究领域的应用,例如辅助科研人员进行文献综述、预测研究趋势、评估研究项目的潜力等。该框架还可以用于训练和评估基于代理的科研助手,提高科研效率和创新能力。此外,PoT还可以用于研究人类与模型在科学研究判断上的差异,从而更好地理解人类的认知过程。
📄 摘要(原文)
Large language models are increasingly being used to assess and forecast research ideas, yet we lack scalable ways to evaluate the quality of models' judgments about these scientific ideas. Towards this goal, we introduce PoT, a semi-verifiable benchmarking framework that links scientific idea judgments to downstream signals that become observable later (e.g., citations and shifts in researchers' agendas). PoT freezes a pre-cutoff snapshot of evidence in an offline sandbox and asks models to forecast post-cutoff outcomes, enabling verifiable evaluation when ground truth arrives, scalable benchmarking without exhaustive expert annotation, and analysis of human-model misalignment against signals such as peer-review awards. In addition, PoT provides a controlled testbed for agent-based research judgments that evaluate scientific ideas, comparing tool-using agents to non-agent baselines under prompt ablations and budget scaling. Across 30,000+ instances spanning four benchmark domains, we find that, compared with non-agent baselines, higher interaction budgets generally improve agent performance, while the benefit of tool use is strongly task-dependent. By combining time-partitioned, future-verifiable targets with an offline sandbox for tool use, PoT supports scalable evaluation of agents on future-facing scientific idea judgment tasks.