GRPO with State Mutations: Improving LLM-Based Hardware Test Plan Generation
作者: Dimple Vijay Kochar, Nathaniel Pinckney, Guan-Ting Liu, Chia-Tung Ho, Chenhui Deng, Haoxing Ren, Brucek Khailany
分类: cs.AR, cs.CL, cs.LG
发布日期: 2026-01-12
💡 一句话要点
提出GRPO-SMu,提升LLM在硬件测试计划生成中的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 硬件验证 测试计划生成 大型语言模型 强化学习 状态突变
📋 核心要点
- 现有RTL设计严重依赖临时测试平台,LLM在硬件规范推理和生成针对性测试计划方面能力不足。
- 提出GRPO-SMu,结合监督微调和强化学习,通过状态突变增强探索,提升LLM生成测试计划的质量。
- 实验结果表明,GRPO-SMu使7B模型黄金测试通过率提升至33.3%,突变检测率达到13.9%,显著优于基线。
📝 摘要(中文)
本文针对大型语言模型(LLM)在RTL验证激励生成方面推理能力的不足,进行了首次系统性研究。研究表明,包括DeepSeek-R1和Claude-4.0-Sonnet在内的先进模型在生成能够通过黄金RTL设计的激励方面,成功率仅为15.7-21.7%。为了改进LLM生成的激励,本文提出了一种综合训练方法,结合了监督微调和一种新颖的强化学习方法——带有状态突变的GRPO(GRPO-SMu),通过改变输入突变来增强探索。该方法利用基于树的分支突变策略来构建包含等效和突变树的训练数据,超越了线性突变方法,提供了丰富的学习信号。经过训练,7B参数模型实现了33.3%的黄金测试通过率和13.9%的突变检测率,比基线提高了17.6%,并且优于更大的通用模型。这些结果表明,专门的训练方法可以显著提高LLM在硬件验证任务中的推理能力,为半导体设计工作流程中的自动化子单元测试奠定基础。
🔬 方法详解
问题定义:论文旨在解决LLM在硬件测试计划生成任务中表现不佳的问题。现有方法,即直接使用LLM生成测试激励,成功率低,无法有效覆盖RTL设计的各种状态和边界条件。痛点在于LLM缺乏对硬件规范的深入理解和有效的探索策略,导致生成的测试用例质量不高。
核心思路:论文的核心思路是通过结合监督微调和强化学习,训练LLM生成高质量的测试计划。关键在于设计一种有效的探索策略,使LLM能够发现更多有价值的测试用例。GRPO-SMu通过状态突变来增强探索,即在生成测试用例的过程中,对输入状态进行随机突变,从而产生更多样化的测试用例。
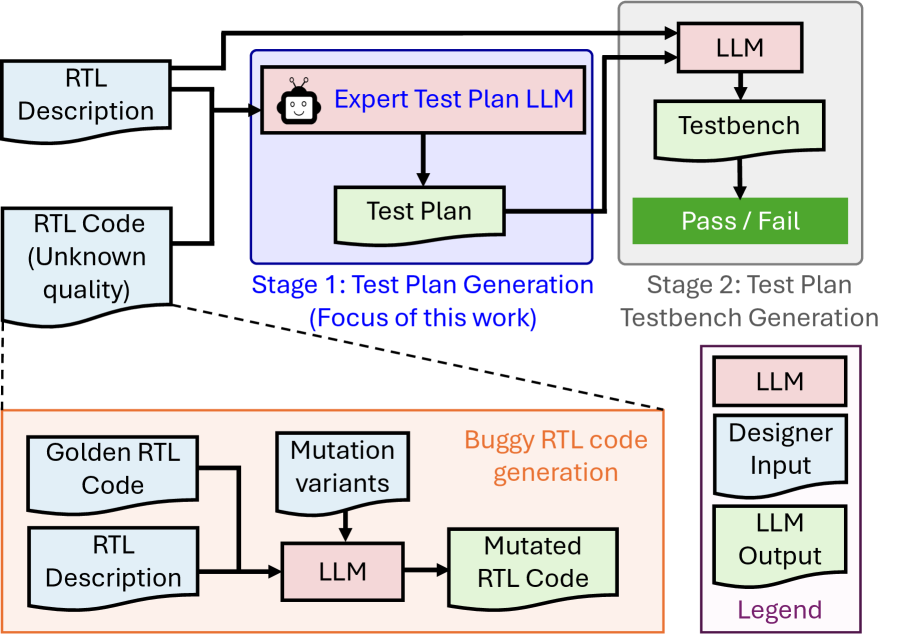
技术框架:该方法采用两阶段框架:首先,使用LLM生成测试计划;然后,执行测试计划并评估其有效性。为了训练LLM,论文结合了监督微调和强化学习。监督微调使用人工标注的测试用例作为训练数据,使LLM学习生成基本的测试用例。强化学习使用GRPO-SMu算法,通过奖励LLM生成能够通过黄金RTL设计或检测到突变的测试用例,来进一步提高LLM的性能。
关键创新:GRPO-SMu算法是该论文的关键创新点。它是一种基于树的分支突变策略,用于生成训练数据。与传统的线性突变方法不同,GRPO-SMu能够生成更丰富、更多样化的训练数据,从而提高LLM的学习效果。此外,GRPO-SMu通过状态突变来增强探索,使LLM能够发现更多有价值的测试用例。
关键设计:GRPO-SMu算法的关键设计包括:1) 基于树的分支突变策略,用于生成训练数据;2) 状态突变机制,用于增强探索;3) 奖励函数,用于评估测试用例的有效性。具体而言,树的每个节点代表一个测试用例,分支代表对测试用例的突变。状态突变通过随机改变输入状态的值来实现。奖励函数根据测试用例是否能够通过黄金RTL设计或检测到突变来计算。
🖼️ 关键图片


📊 实验亮点
实验结果表明,经过GRPO-SMu训练的7B参数模型在黄金测试通过率和突变检测率方面均取得了显著提升。黄金测试通过率达到33.3%,比基线提高了17.6%。突变检测率达到13.9%。此外,该模型还优于更大的通用模型,表明专门的训练方法可以显著提高LLM在硬件验证任务中的性能。
🎯 应用场景
该研究成果可应用于半导体设计的自动化子单元测试,降低验证成本,缩短设计周期。通过自动生成高质量的测试计划,可以更全面地验证RTL设计的正确性,减少潜在的bug,提高芯片的可靠性。未来,该方法有望扩展到更复杂的硬件验证任务,例如系统级验证和形式验证。
📄 摘要(原文)
RTL design often relies heavily on ad-hoc testbench creation early in the design cycle. While large language models (LLMs) show promise for RTL code generation, their ability to reason about hardware specifications and generate targeted test plans remains largely unexplored. We present the first systematic study of LLM reasoning capabilities for RTL verification stimuli generation, establishing a two-stage framework that decomposes test plan generation from testbench execution. Our benchmark reveals that state-of-the-art models, including DeepSeek-R1 and Claude-4.0-Sonnet, achieve only 15.7-21.7% success rates on generating stimuli that pass golden RTL designs. To improve LLM generated stimuli, we develop a comprehensive training methodology combining supervised fine-tuning with a novel reinforcement learning approach, GRPO with State Mutation (GRPO-SMu), which enhances exploration by varying input mutations. Our approach leverages a tree-based branching mutation strategy to construct training data comprising equivalent and mutated trees, moving beyond linear mutation approaches to provide rich learning signals. Training on this curated dataset, our 7B parameter model achieves a 33.3% golden test pass rate and a 13.9% mutation detection rate, representing a 17.6% absolute improvement over baseline and outperforming much larger general-purpose models. These results demonstrate that specialized training methodologies can significantly enhance LLM reasoning capabilities for hardware verification tasks, establishing a foundation for automated sub-unit testing in semiconductor design workflows.