Thinking Before Constraining: A Unified Decoding Framework for Large Language Models
作者: Ngoc Trinh Hung Nguyen, Alonso Silva, Laith Zumot, Liubov Tupikina, Armen Aghasaryan, Mehwish Alam
分类: cs.CL, cs.AI
发布日期: 2026-01-12
💡 一句话要点
提出一种统一解码框架,结合自然语言推理和结构化生成,提升大语言模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 结构化生成 自然语言生成 约束解码 统一解码框架
📋 核心要点
- 现有大语言模型自然生成缺乏结构,难以解析和验证,而结构化生成限制了模型的推理能力。
- 论文提出一种统一解码框架,先允许模型自由推理,在特定触发token后切换到结构化生成。
- 实验结果表明,该方法在分类和推理任务上,准确率提升高达27%,且仅增加少量token开销。
📝 摘要(中文)
自然语言生成允许语言模型产生具有丰富推理的自由形式的响应,但缺乏保证的结构使得输出难以解析或验证。结构化生成,或约束解码,通过以JSON等标准化格式生成内容来解决这个缺点,确保一致性和保证可解析的输出,但它可能会无意中限制模型的推理能力。在这项工作中,我们提出了一种简单的方法,它结合了自然生成和结构化生成的优点。通过允许LLM自由推理,直到生成特定的触发token,然后切换到结构化生成,我们的方法保留了自然语言推理的表达能力,同时确保了结构化输出的可靠性。我们进一步在几个数据集上评估了我们的方法,涵盖分类和推理任务,以证明其有效性,与自然生成相比,在准确性方面实现了高达27%的显著提升,同时只需要10-20个额外token的少量开销。
🔬 方法详解
问题定义:现有的大语言模型在生成内容时,面临着自然语言生成和结构化生成之间的权衡问题。自然语言生成虽然具有丰富的表达能力和推理能力,但其输出缺乏结构,难以解析和验证。而结构化生成虽然能够保证输出的结构化和可解析性,但却可能限制模型的推理能力,导致性能下降。因此,如何结合两者的优点,在保证输出结构化的同时,充分发挥模型的推理能力,是一个亟待解决的问题。
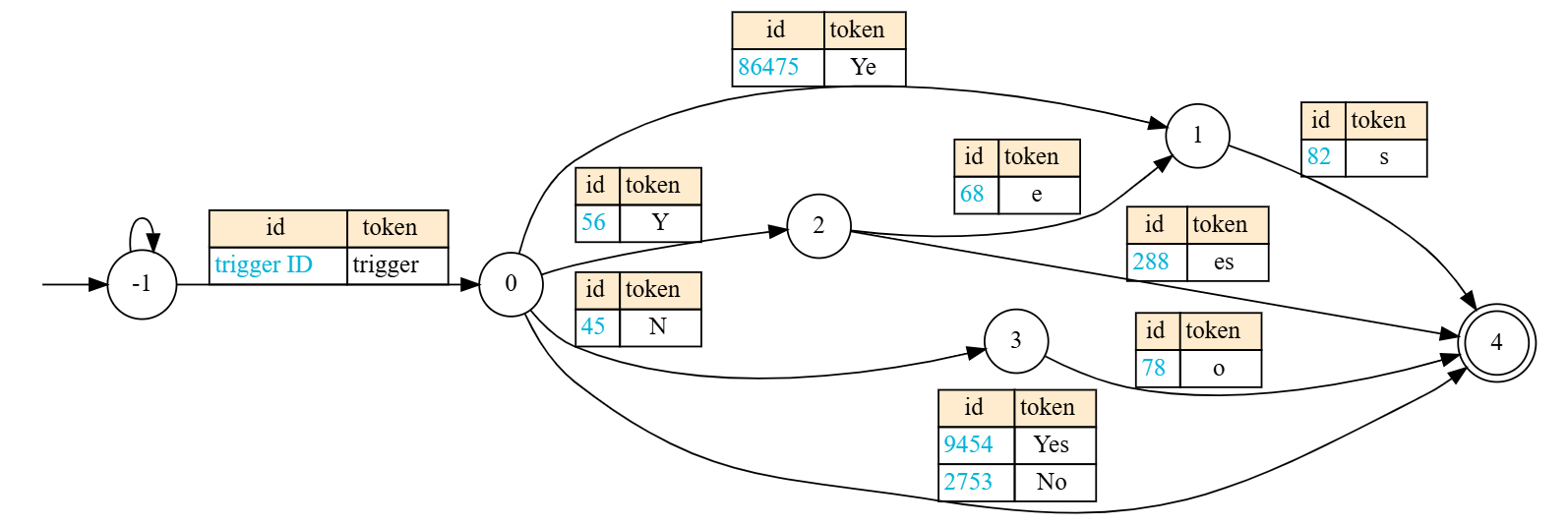
核心思路:论文的核心思路是“先思考,后约束”。具体来说,就是允许大语言模型在生成内容时,先进行自由的自然语言推理,直到生成特定的触发token后,再切换到结构化生成模式。这样,既可以充分发挥模型的推理能力,又可以保证输出的结构化和可解析性。这种方法的核心在于,通过触发token来控制生成模式的切换,从而实现自然语言生成和结构化生成的无缝衔接。
技术框架:该方法的技术框架主要包含两个阶段:自然语言推理阶段和结构化生成阶段。在自然语言推理阶段,模型可以自由地生成文本,进行推理和思考。当模型生成预定义的触发token时,系统会自动切换到结构化生成阶段。在结构化生成阶段,模型会按照预定义的结构化格式(如JSON)生成内容,确保输出的结构化和可解析性。整个过程由触发token驱动,实现两种生成模式的动态切换。
关键创新:该方法最重要的技术创新点在于其统一的解码框架,它能够将自然语言生成和结构化生成无缝地结合在一起。与传统的要么完全自然生成,要么完全结构化生成的方法不同,该方法允许模型在生成过程中动态地切换生成模式,从而兼顾了表达能力和结构化约束。这种动态切换的机制,使得模型能够更好地适应不同的任务需求,提高生成质量。
关键设计:该方法的一个关键设计在于触发token的选择。触发token的选择需要 carefully 设计,以确保能够准确地触发生成模式的切换。此外,在结构化生成阶段,需要预定义好结构化格式,并设计相应的解码算法,以保证输出的结构化和可解析性。具体的参数设置和网络结构等技术细节,需要根据具体的任务和数据集进行调整和优化。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在多个数据集上取得了显著的性能提升。例如,在分类和推理任务上,与自然生成相比,准确率提升高达27%,同时只需要10-20个额外token的少量开销。这些结果表明,该方法能够有效地结合自然语言推理和结构化生成,提高大语言模型的性能。
🎯 应用场景
该研究成果可广泛应用于需要结构化输出的大语言模型应用场景,例如:知识图谱构建、智能问答系统、数据分析报告生成等。通过保证输出的结构化和可解析性,可以提高下游任务的效率和准确性,并为大语言模型在实际应用中发挥更大的价值奠定基础。未来,该方法有望进一步扩展到更复杂的结构化生成任务中。
📄 摘要(原文)
Natural generation allows Language Models (LMs) to produce free-form responses with rich reasoning, but the lack of guaranteed structure makes outputs difficult to parse or verify. Structured generation, or constrained decoding, addresses this drawback by producing content in standardized formats such as JSON, ensuring consistency and guaranteed-parsable outputs, but it can inadvertently restrict the model's reasoning capabilities. In this work, we propose a simple approach that combines the advantages of both natural and structured generation. By allowing LLMs to reason freely until specific trigger tokens are generated, and then switching to structured generation, our method preserves the expressive power of natural language reasoning while ensuring the reliability of structured outputs. We further evaluate our approach on several datasets, covering both classification and reasoning tasks, to demonstrate its effectiveness, achieving a substantial gain of up to 27% in accuracy compared to natural generation, while requiring only a small overhead of 10-20 extra tokens.