Controlling Multimodal Conversational Agents with Coverage-Enhanced Latent Actions
作者: Yongqi Li, Hao Lang, Tieyun Qian, Yongbin Li
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-01-12
💡 一句话要点
提出覆盖增强的潜在动作方法,用于控制多模态对话Agent。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态对话Agent 强化学习 潜在动作空间 跨模态学习 循环一致性 覆盖增强 人机交互
📋 核心要点
- 现有强化学习微调多模态对话Agent时,难以处理巨大的文本token空间,限制了性能。
- 通过学习紧凑的潜在动作空间进行强化学习微调,利用未来观察估计当前动作,重构未来观察。
- 利用配对图像-文本数据和纯文本数据,结合跨模态投影器和循环一致性损失,增强码本覆盖率。
📝 摘要(中文)
本文提出了一种基于覆盖增强的潜在动作空间的多模态对话Agent(MCA)控制方法。针对现有强化学习(RL)微调MCA时面临的巨大文本token空间挑战,本文学习了一个紧凑的潜在动作空间用于RL微调。具体而言,采用从观察中学习的机制构建潜在动作空间的码本,利用未来观察来估计当前的潜在动作,进而重构未来观察。为解决配对图像-文本数据稀缺导致码本覆盖不足的问题,本文同时利用配对图像-文本数据和纯文本数据构建潜在动作空间,并使用跨模态投影器将文本嵌入转换为图像-文本嵌入。该投影器首先在配对数据上初始化,然后通过新颖的循环一致性损失在海量文本数据上进一步训练,以增强其鲁棒性。实验表明,基于潜在动作的方法在各种RL算法下,优于两个对话任务上的竞争基线。
🔬 方法详解
问题定义:现有的多模态对话Agent(MCA)在通过强化学习(RL)进行微调时,面临着文本token空间过大的问题。直接在巨大的token空间中进行动作选择,导致训练效率低下,难以收敛,并且泛化能力受限。因此,需要一种更有效的方式来控制MCA的行为,使其能够更好地适应各种人机交互场景。
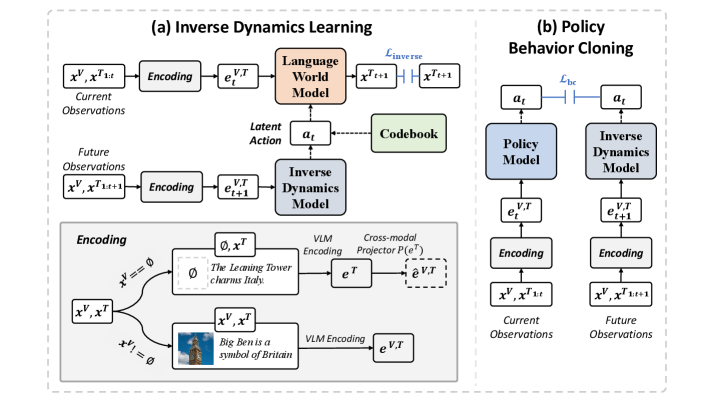
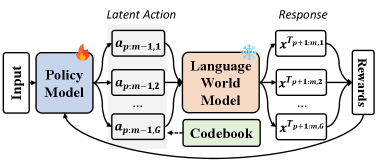
核心思路:本文的核心思路是学习一个紧凑的潜在动作空间,而不是直接在原始的文本token空间中进行动作选择。通过将高维的文本动作映射到低维的潜在空间,可以显著降低RL算法的搜索空间,提高训练效率和泛化能力。此外,利用“从观察中学习”的机制,通过预测未来状态来指导当前动作的选择,进一步提升了动作的有效性。
技术框架:整体框架包含以下几个主要模块:1) 观察编码器:将当前的多模态输入(图像和文本)编码成一个统一的嵌入表示。2) 潜在动作空间:通过码本的形式存储一系列离散的潜在动作。3) 动作预测器:根据当前观察的嵌入表示,预测一个潜在动作。4) 解码器:将潜在动作解码成文本响应。5) 跨模态投影器:用于将文本嵌入投影到图像-文本嵌入空间,从而利用纯文本数据增强潜在动作空间的覆盖率。训练过程包括两个阶段:首先,使用配对的图像-文本数据初始化跨模态投影器;然后,使用大量的纯文本数据,通过循环一致性损失进一步训练该投影器。
关键创新:本文最重要的创新点在于提出了覆盖增强的潜在动作空间学习方法。具体来说,通过结合配对的图像-文本数据和纯文本数据,并利用跨模态投影器和循环一致性损失,有效地解决了数据稀缺问题,显著提升了潜在动作空间的覆盖率。这使得RL算法能够更好地探索和利用潜在动作空间,从而获得更优的性能。与现有方法相比,本文的方法能够更有效地利用无标签数据,提升模型的鲁棒性和泛化能力。
关键设计:1) 循环一致性损失:用于训练跨模态投影器,确保文本嵌入经过投影后,能够尽可能地保留原始文本的信息。2) 码本大小:潜在动作空间的码本大小是一个重要的超参数,需要根据具体任务进行调整。3) 损失函数:除了循环一致性损失外,还包括重构损失和RL相关的奖励函数,用于指导潜在动作空间的学习和优化。
🖼️ 关键图片

📊 实验亮点
实验结果表明,本文提出的方法在两个对话任务上均优于竞争基线。具体而言,在某些任务上,该方法能够将性能提升超过10%。此外,实验还验证了跨模态投影器和循环一致性损失的有效性,证明了利用纯文本数据可以显著提升潜在动作空间的覆盖率。
🎯 应用场景
该研究成果可广泛应用于各种多模态对话场景,例如智能客服、虚拟助手、游戏AI等。通过学习更有效的对话策略,可以提升人机交互的自然性和流畅性,改善用户体验。此外,该方法还可以扩展到其他需要控制生成模型的任务中,例如图像生成、视频生成等。
📄 摘要(原文)
Vision-language models are increasingly employed as multimodal conversational agents (MCAs) for diverse conversational tasks. Recently, reinforcement learning (RL) has been widely explored for adapting MCAs to various human-AI interaction scenarios. Despite showing great enhancement in generalization performance, fine-tuning MCAs via RL still faces challenges in handling the extremely large text token space. To address this, we learn a compact latent action space for RL fine-tuning instead. Specifically, we adopt the learning from observation mechanism to construct the codebook for the latent action space, where future observations are leveraged to estimate current latent actions that could further be used to reconstruct future observations. However, the scarcity of paired image-text data hinders learning a codebook with sufficient coverage. Thus, we leverage both paired image-text data and text-only data to construct the latent action space, using a cross-modal projector for transforming text embeddings into image-text embeddings. We initialize the cross-modal projector on paired image-text data, and further train it on massive text-only data with a novel cycle consistency loss to enhance its robustness. We show that our latent action based method outperforms competitive baselines on two conversation tasks across various RL algorithms.