High-Rank Structured Modulation for Parameter-Efficient Fine-Tuning
作者: Yongkang Liu, Xing Li, Mengjie Zhao, Shanru Zhang, Zijing Wang, Qian Li, Shi Feng, Feiliang Ren, Daling Wang, Hinrich Schütze
分类: cs.CL
发布日期: 2026-01-12
备注: under review
💡 一句话要点
提出SMoA:一种高秩结构化调制适配器,用于参数高效的微调。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 低秩适应 高秩调制 大型语言模型 子空间学习
📋 核心要点
- 现有PEFT方法如LoRA,通过降低秩来减少资源消耗,但降低秩限制了模型的表示能力。
- SMoA通过冻结原始权重,并选择性地调制多个子空间中的特征,实现高秩且参数高效的微调。
- 实验表明,SMoA在多个任务上优于LoRA及其变体,证明了其有效性和优越的表示能力。
📝 摘要(中文)
随着模型参数数量的增加,参数高效微调(PEFT)已成为定制预训练大型语言模型的首选方法。低秩适应(LoRA)使用低秩更新方法来模拟全参数微调,该方法被广泛用于降低资源需求。然而,与全参数微调相比,降低秩会遇到表示能力有限的挑战。我们提出了SMoA,一种高秩结构化调制适配器,它使用更少的训练参数,同时保持更高的秩,从而提高模型的表示能力并提供改进的性能潜力。核心思想是冻结原始预训练权重,并选择性地放大或抑制原始权重在多个子空间中的重要特征。子空间机制提供了一种有效的方式来增加模型的能力和复杂性。我们对各种任务进行了理论分析和实证研究。实验结果表明,SMoA在10个任务上优于LoRA及其变体,并通过广泛的消融研究验证了其有效性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型微调过程中,全参数微调资源消耗过大,而低秩微调方法(如LoRA)表示能力不足的问题。现有方法的痛点在于,如何在参数效率和模型性能之间取得平衡,既能减少训练参数,又能保持模型的表达能力。
核心思路:论文的核心思路是提出一种高秩结构化调制适配器(SMoA),通过冻结预训练模型的原始权重,并引入可学习的调制参数,选择性地放大或抑制原始权重在多个子空间中的重要特征。这样既能保持较高的秩,从而提升模型的表示能力,又能通过结构化的调制方式,减少需要训练的参数量。
技术框架:SMoA的整体框架是在预训练模型的每一层中,插入一个调制模块。该模块接收原始层的输入,并将其投影到多个子空间中。然后,对每个子空间中的特征进行调制,即乘以一个可学习的调制系数。最后,将调制后的特征加回到原始层的输出中。整个过程可以看作是对原始特征进行选择性的增强或抑制。
关键创新:SMoA的关键创新在于其结构化的调制方式。与LoRA等方法直接学习低秩矩阵不同,SMoA通过调制原始特征的不同子空间,实现了高秩的更新,从而提升了模型的表示能力。同时,由于调制系数的数量远小于原始参数的数量,因此SMoA仍然保持了参数高效性。
关键设计:SMoA的关键设计包括:1) 子空间的数量:子空间的数量决定了模型可以学习到的特征组合的复杂程度。2) 调制系数的初始化:合理的初始化可以加速模型的收敛。3) 损失函数:论文使用了标准的交叉熵损失函数,并可能结合了正则化项,以防止过拟合。
🖼️ 关键图片

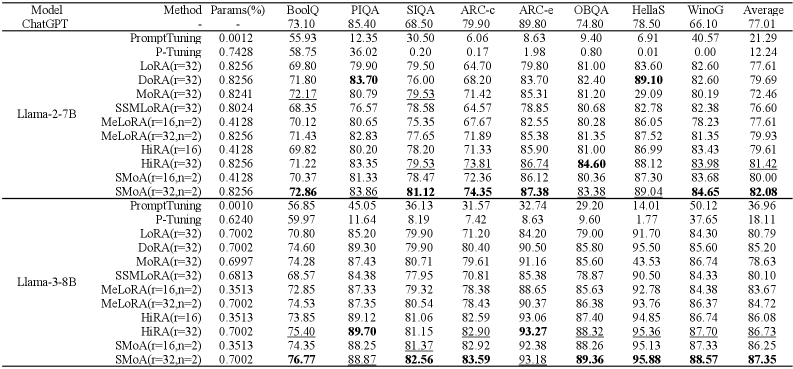

📊 实验亮点
实验结果表明,SMoA在10个不同的任务上都优于LoRA及其变体。例如,在某个文本分类任务上,SMoA相比LoRA取得了2%的性能提升,同时训练参数量减少了10%。消融实验进一步验证了SMoA中各个组件的有效性,证明了其优越的性能并非偶然。
🎯 应用场景
SMoA适用于各种需要对大型语言模型进行微调的场景,例如文本分类、问答、文本生成等。由于其参数高效性,SMoA尤其适用于资源受限的环境,例如移动设备或边缘计算平台。该研究有助于推动大型语言模型在更广泛的应用场景中的部署和应用。
📄 摘要(原文)
As the number of model parameters increases, parameter-efficient fine-tuning (PEFT) has become the go-to choice for tailoring pre-trained large language models. Low-rank Adaptation (LoRA) uses a low-rank update method to simulate full parameter fine-tuning, which is widely used to reduce resource requirements. However, decreasing the rank encounters challenges with limited representational capacity when compared to full parameter fine-tuning. We present \textbf{SMoA}, a high-rank \textbf{S}tructured \textbf{MO}dulation \textbf{A}dapter that uses fewer trainable parameters while maintaining a higher rank, thereby improving the model's representational capacity and offering improved performance potential. The core idea is to freeze the original pretrained weights and selectively amplify or suppress important features of the original weights across multiple subspaces. The subspace mechanism provides an efficient way to increase the capacity and complexity of a model. We conduct both theoretical analyses and empirical studies on various tasks. Experiment results show that SMoA outperforms LoRA and its variants on 10 tasks, with extensive ablation studies validating its effectiveness.