KALE: Enhancing Knowledge Manipulation in Large Language Models via Knowledge-aware Learning
作者: Qitan Lv, Tianyu Liu, Qiaosheng Zhang, Xingcheng Xu, Chaochao Lu
分类: cs.CL, cs.AI
发布日期: 2026-01-12
💡 一句话要点
KALE:通过知识感知学习增强大语言模型中的知识操控能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 知识图谱 知识推理 有监督微调 知识感知学习
📋 核心要点
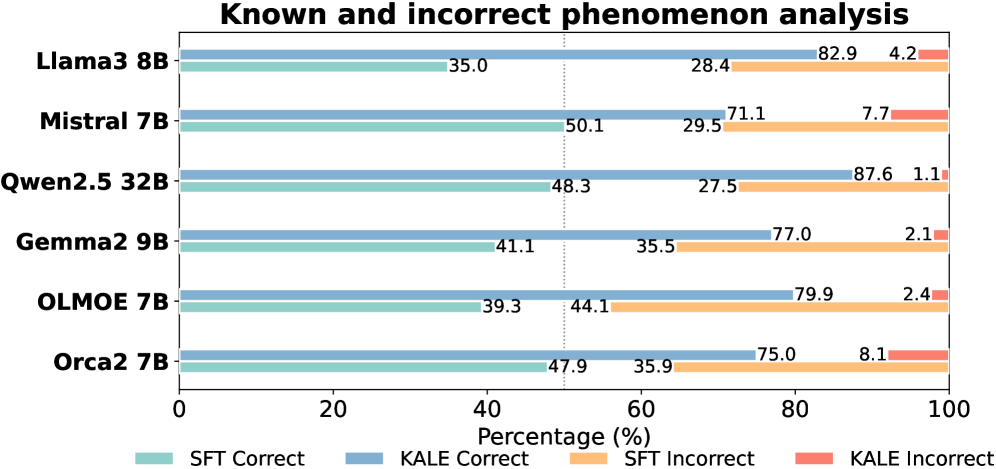
- 现有大语言模型在知识操控方面存在“已知但错误”的问题,即拥有相关知识却无法正确运用。
- KALE框架利用知识图谱生成高质量推理链,并通过知识感知微调,引导模型内化推理过程。
- 实验结果表明,KALE在多个基准测试中显著提升了模型的准确率,平均提升达4.18%。
📝 摘要(中文)
尽管在大规模知识语料库上预训练的大语言模型(LLMs)表现出色,但提升其知识操控能力——有效回忆、推理和迁移相关知识的能力——仍然具有挑战性。现有方法主要利用有监督微调(SFT)在标注数据集上增强LLMs的知识操控能力。然而,我们观察到SFT模型仍然表现出“已知但错误”的现象,即它们明确地拥有给定问题的相关知识,但未能利用它来获得正确的答案。为了解决这个挑战,我们提出了KALE(知识感知学习)——一个后训练框架,它利用知识图谱(KGs)来生成高质量的推理链,并增强LLMs的知识操控能力。具体来说,KALE首先引入了一种知识诱导(KI)数据合成方法,该方法有效地从KGs中提取多跳推理路径,从而为问答对生成高质量的推理链。然后,KALE采用了一种知识感知(KA)微调范式,通过最小化有无推理链预测之间的KL散度,内化推理链引导的推理,从而增强知识操控能力。在六种不同LLMs的八个流行基准上进行的大量实验证明了KALE的有效性,实现了高达11.72%的准确率提升,平均提升4.18%。
🔬 方法详解
问题定义:论文旨在解决大语言模型在知识操控方面存在的“已知但错误”问题。现有方法主要依赖于有监督微调,但模型即使拥有相关知识,也可能无法正确推理并给出答案。这表明模型缺乏有效利用知识进行推理的能力。
核心思路:论文的核心思路是利用知识图谱(KGs)来引导大语言模型进行推理。通过从KGs中提取多跳推理路径,生成高质量的推理链,并利用这些推理链来训练模型,从而增强模型利用知识进行推理的能力。这样设计的目的是让模型学习如何从知识中提取相关信息,并将其用于解决问题。
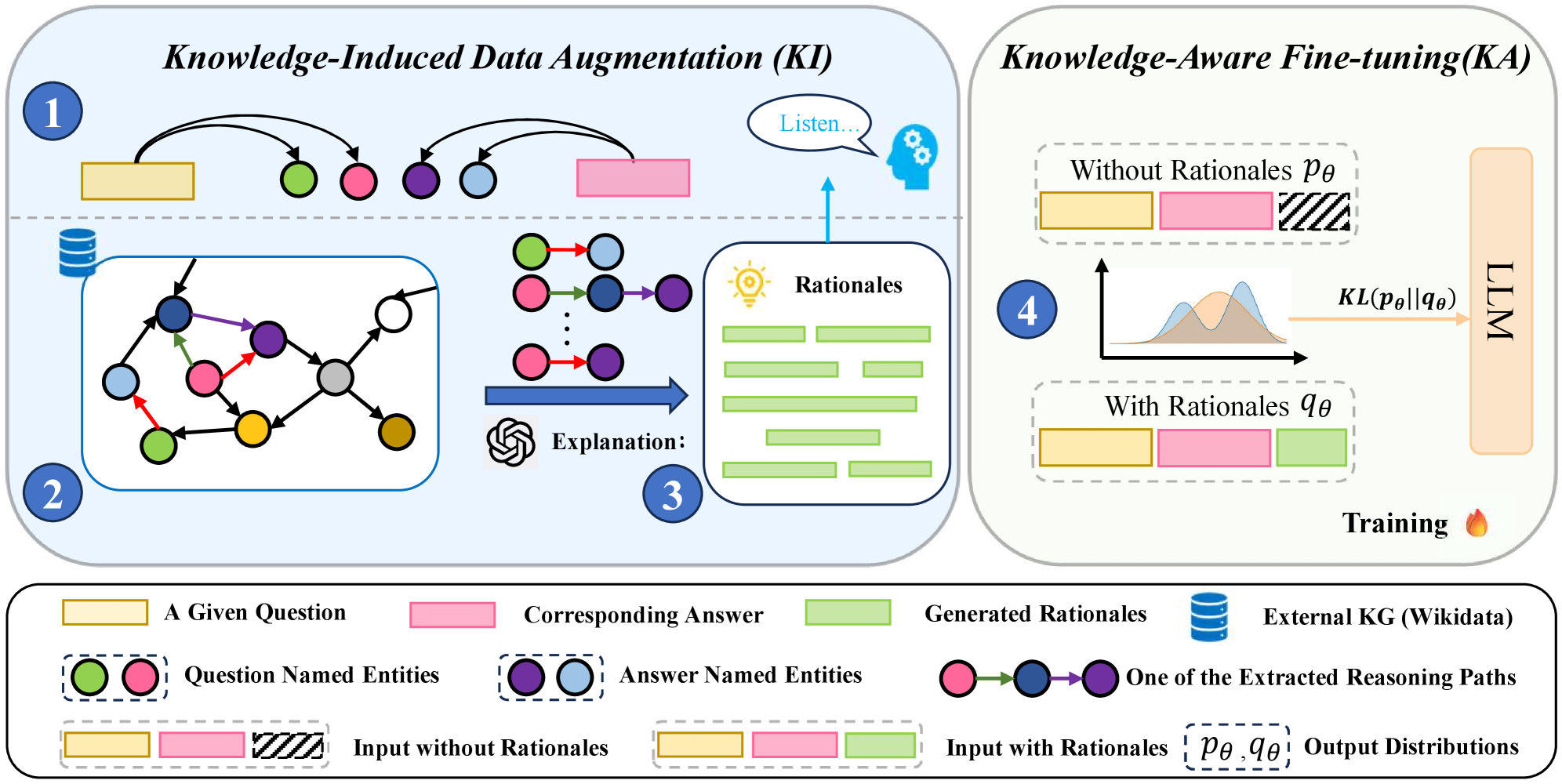
技术框架:KALE框架包含两个主要阶段:知识诱导(KI)数据合成和知识感知(KA)微调。首先,KI数据合成阶段从知识图谱中提取多跳推理路径,为问答对生成高质量的推理链。然后,KA微调阶段利用这些推理链来微调大语言模型,通过最小化有无推理链预测之间的KL散度,使模型学习内化推理过程。
关键创新:KALE的关键创新在于其知识感知的学习范式。与传统的有监督微调不同,KALE利用知识图谱生成的推理链来引导模型的学习,从而使模型能够更好地利用知识进行推理。此外,KALE通过最小化KL散度,鼓励模型在有无推理链的情况下产生一致的预测,从而增强模型的鲁棒性。
关键设计:KI数据合成阶段的关键在于如何有效地从知识图谱中提取多跳推理路径。论文采用了一种高效的搜索算法,以确保提取的推理路径既相关又具有多样性。KA微调阶段的关键在于如何选择合适的KL散度权重,以平衡有无推理链预测之间的一致性。论文通过实验确定了最佳的权重值。
🖼️ 关键图片

📊 实验亮点
实验结果表明,KALE在八个流行的基准测试中显著提升了模型的准确率。例如,在某些基准测试中,KALE实现了高达11.72%的准确率提升,平均提升为4.18%。这些结果表明,KALE是一种有效的增强大语言模型知识操控能力的方法,并且具有广泛的适用性。
🎯 应用场景
KALE框架可应用于各种需要知识推理的大语言模型应用场景,例如问答系统、知识图谱补全、智能客服等。通过增强模型对知识的操控能力,可以提高这些应用的准确性和可靠性,从而提升用户体验和解决实际问题。该研究对提升大语言模型在知识密集型任务中的表现具有重要意义。
📄 摘要(原文)
Despite the impressive performance of large language models (LLMs) pretrained on vast knowledge corpora, advancing their knowledge manipulation-the ability to effectively recall, reason, and transfer relevant knowledge-remains challenging. Existing methods mainly leverage Supervised Fine-Tuning (SFT) on labeled datasets to enhance LLMs' knowledge manipulation ability. However, we observe that SFT models still exhibit the known&incorrect phenomenon, where they explicitly possess relevant knowledge for a given question but fail to leverage it for correct answers. To address this challenge, we propose KALE (Knowledge-Aware LEarning)-a post-training framework that leverages knowledge graphs (KGs) to generate high-quality rationales and enhance LLMs' knowledge manipulation ability. Specifically, KALE first introduces a Knowledge-Induced (KI) data synthesis method that efficiently extracts multi-hop reasoning paths from KGs to generate high-quality rationales for question-answer pairs. Then, KALE employs a Knowledge-Aware (KA) fine-tuning paradigm that enhances knowledge manipulation by internalizing rationale-guided reasoning through minimizing the KL divergence between predictions with and without rationales. Extensive experiments on eight popular benchmarks across six different LLMs demonstrate the effectiveness of KALE, achieving accuracy improvements of up to 11.72% and an average of 4.18%.