Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
作者: Xin Cheng, Wangding Zeng, Damai Dai, Qinyu Chen, Bingxuan Wang, Zhenda Xie, Kezhao Huang, Xingkai Yu, Zhewen Hao, Yukun Li, Han Zhang, Huishuai Zhang, Dongyan Zhao, Wenfeng Liang
分类: cs.CL, cs.AI
发布日期: 2026-01-12
💡 一句话要点
提出Engram,通过可扩展查找的条件记忆,为大语言模型引入新的稀疏性维度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 条件记忆 稀疏性 知识检索 N-gram嵌入
📋 核心要点
- Transformer缺乏原生知识查找机制,导致其检索效率低下,需要通过计算来模拟检索。
- 论文提出条件记忆作为一种互补的稀疏性维度,通过Engram模块实现快速知识查找。
- 实验表明,Engram在知识检索、通用推理和代码/数学等领域均优于同等参数和FLOPs的MoE模型。
📝 摘要(中文)
本文提出了一种新的稀疏性维度——条件记忆,以补充Transformer模型在知识查找方面的不足。通过Engram模块实现条件记忆,Engram模块是对经典N-gram嵌入的改进,实现了O(1)的查找复杂度。论文提出了稀疏性分配问题,并发现了一个U型缩放规律,该规律优化了神经计算(MoE)和静态记忆(Engram)之间的权衡。基于此规律,Engram被扩展到27B参数,性能优于参数量和FLOPs相当的MoE基线。除了在知识检索任务(如MMLU +3.4; CMMLU +4.0)上的提升,在通用推理(如BBH +5.0; ARC-Challenge +3.7)和代码/数学领域(如HumanEval +3.0; MATH +2.4)也观察到更大的增益。机制分析表明,Engram减轻了骨干网络早期层在静态重建方面的负担,有效地加深了网络以进行复杂推理。此外,通过将局部依赖性委托给查找,释放了注意力容量用于全局上下文,从而显著提高了长上下文检索能力(如Multi-Query NIAH: 84.2 to 97.0)。Engram还实现了基础设施感知效率:其确定性寻址支持从主机内存进行运行时预取,开销可忽略不计。条件记忆有望成为下一代稀疏模型不可或缺的建模原语。
🔬 方法详解
问题定义:Transformer模型在知识检索方面效率较低,需要通过计算来模拟检索过程,这限制了模型在知识密集型任务上的表现。现有方法,如MoE,虽然通过条件计算扩展了模型容量,但仍然缺乏直接的知识查找机制。
核心思路:论文的核心思路是引入条件记忆作为一种新的稀疏性维度,与MoE等条件计算方法互补。通过将知识存储在外部记忆模块中,模型可以快速查找相关信息,而无需通过复杂的计算来重建知识。Engram模块通过改进经典的N-gram嵌入,实现了O(1)的查找复杂度,从而提高了知识检索的效率。
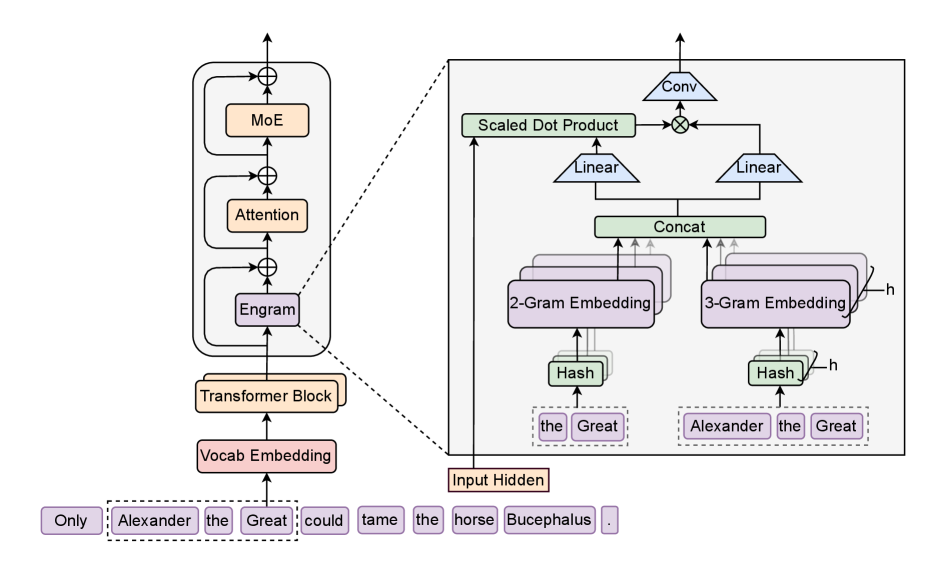
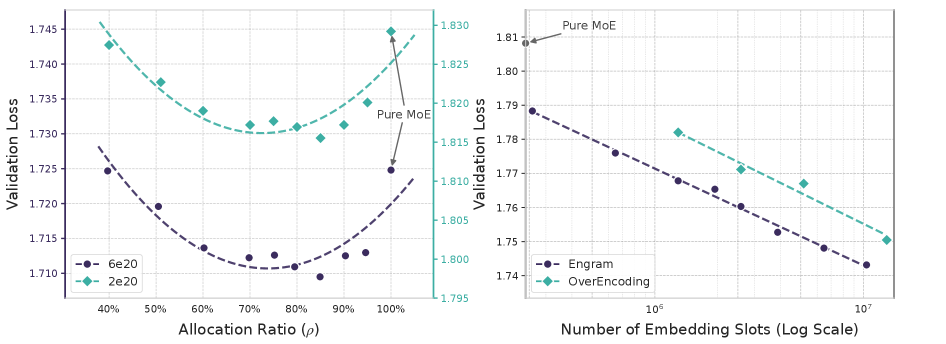
技术框架:Engram模块可以插入到Transformer模型的不同层中,与现有的MoE层结合使用。整体架构包含一个Transformer骨干网络,以及若干个Engram模块。当输入一个token序列时,Engram模块首先将token序列转换为N-gram表示,然后使用N-gram作为索引,从外部记忆模块中查找相应的嵌入向量。这些嵌入向量随后被用于增强Transformer层的输入。论文还提出了稀疏性分配问题,旨在优化神经计算(MoE)和静态记忆(Engram)之间的权衡。
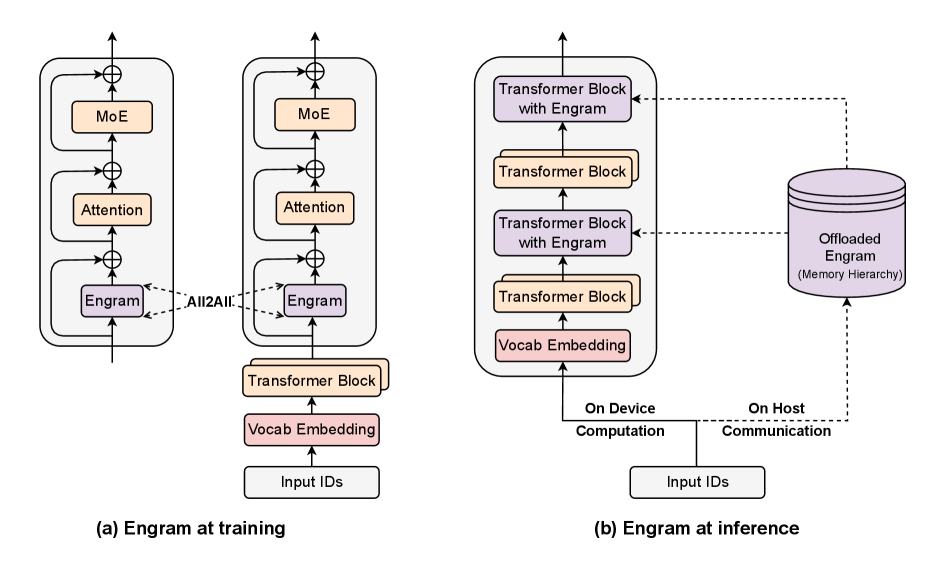
关键创新:最重要的技术创新点是引入了条件记忆的概念,并将其实现为Engram模块。与传统的知识检索方法相比,Engram模块具有O(1)的查找复杂度,可以实现快速的知识检索。此外,Engram模块还可以与MoE等条件计算方法结合使用,从而进一步提高模型的性能。Engram模块通过将局部依赖性委托给查找,释放了注意力容量用于全局上下文,从而显著提高了长上下文检索能力。
关键设计:Engram模块的关键设计包括N-gram嵌入的构建方式、记忆模块的组织方式以及如何将检索到的嵌入向量融入到Transformer层中。论文中详细描述了如何构建N-gram嵌入,以及如何使用哈希表来实现O(1)的查找复杂度。此外,论文还探讨了不同的记忆模块组织方式,以及不同的嵌入向量融合策略。损失函数的设计旨在优化N-gram嵌入的质量,并鼓励模型使用Engram模块进行知识检索。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Engram在多个任务上均优于同等参数量和FLOPs的MoE基线。例如,在MMLU上提升了3.4,在CMMLU上提升了4.0,在BBH上提升了5.0,在ARC-Challenge上提升了3.7,在HumanEval上提升了3.0,在MATH上提升了2.4。此外,Engram还显著提高了长上下文检索能力,例如在Multi-Query NIAH上从84.2提升到97.0。
🎯 应用场景
该研究成果可广泛应用于需要大量知识检索的大语言模型应用场景,例如问答系统、知识图谱推理、代码生成、数学问题求解等。通过引入条件记忆,可以提高模型的知识检索效率和推理能力,从而改善用户体验。未来,该技术有望成为下一代稀疏模型的重要组成部分。
📄 摘要(原文)
While Mixture-of-Experts (MoE) scales capacity via conditional computation, Transformers lack a native primitive for knowledge lookup, forcing them to inefficiently simulate retrieval through computation. To address this, we introduce conditional memory as a complementary sparsity axis, instantiated via Engram, a module that modernizes classic $N$-gram embedding for O(1) lookup. By formulating the Sparsity Allocation problem, we uncover a U-shaped scaling law that optimizes the trade-off between neural computation (MoE) and static memory (Engram). Guided by this law, we scale Engram to 27B parameters, achieving superior performance over a strictly iso-parameter and iso-FLOPs MoE baseline. Most notably, while the memory module is expected to aid knowledge retrieval (e.g., MMLU +3.4; CMMLU +4.0), we observe even larger gains in general reasoning (e.g., BBH +5.0; ARC-Challenge +3.7) and code/math domains~(HumanEval +3.0; MATH +2.4). Mechanistic analyses reveal that Engram relieves the backbone's early layers from static reconstruction, effectively deepening the network for complex reasoning. Furthermore, by delegating local dependencies to lookups, it frees up attention capacity for global context, substantially boosting long-context retrieval (e.g., Multi-Query NIAH: 84.2 to 97.0). Finally, Engram establishes infrastructure-aware efficiency: its deterministic addressing enables runtime prefetching from host memory, incurring negligible overhead. We envision conditional memory as an indispensable modeling primitive for next-generation sparse models.