BayesRAG: Probabilistic Mutual Evidence Corroboration for Multimodal Retrieval-Augmented Generation
作者: Xuan Li, Yining Wang, Haocai Luo, Shengping Liu, Jerry Liang, Ying Fu, Weihuang, Jun Yu, Junnan Zhu
分类: cs.CL
发布日期: 2026-01-12
备注: 17 pages, 8 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出BayesRAG,通过概率互证提升多模态检索增强生成效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态检索 检索增强生成 贝叶斯推理 证据理论 跨模态融合
📋 核心要点
- 现有RAG方法在处理多模态文档时,忽略了文本和图像之间的关联,导致检索效果不佳。
- BayesRAG利用贝叶斯推理和证据理论,将跨模态信息的一致性建模为概率证据,提升检索置信度。
- 实验结果表明,BayesRAG在多模态基准测试中显著优于现有方法,提升了检索增强生成的效果。
📝 摘要(中文)
检索增强生成(RAG)已成为大语言模型(LLM)的关键范式,但现有方法在处理富含视觉信息的文档时,通常将文本和图像视为孤立的检索目标,效果不佳。现有方法仅依赖余弦相似度,无法捕捉跨模态对齐和布局一致性提供的语义增强。为了解决这些局限性,我们提出了BayesRAG,一种基于贝叶斯推理和Dempster-Shafer证据理论的新型多模态检索框架。与传统方法严格按相似度排序候选对象不同,BayesRAG将跨模态检索候选对象的内在一致性建模为概率证据,以细化检索置信度。具体来说,我们的方法计算多模态检索结果组合的后验关联概率,优先考虑在语义和布局方面相互佐证的文本-图像对。大量实验表明,BayesRAG在具有挑战性的多模态基准测试中显著优于最先进(SOTA)的方法。这项研究为多模态检索融合建立了一种新范式,通过证据融合机制有效地解决了异构模态的隔离问题,并增强了检索结果的鲁棒性。
🔬 方法详解
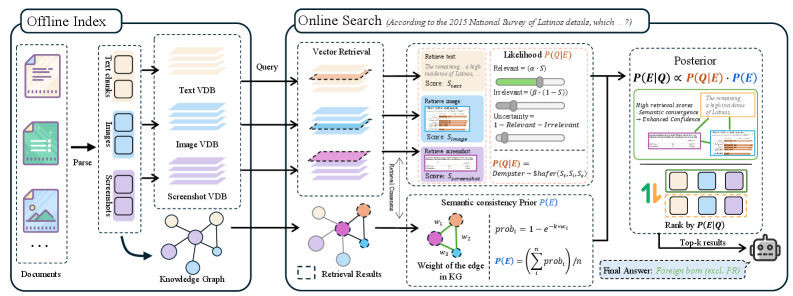
问题定义:现有RAG方法在处理包含图像的文档时,通常独立检索文本和图像,忽略了它们之间的语义关联和布局一致性。这种孤立的处理方式导致检索结果不准确,影响了后续的生成效果。现有方法主要依赖于余弦相似度等度量方式,无法有效捕捉跨模态信息之间的互补和增强关系。
核心思路:BayesRAG的核心思路是将文本和图像的检索结果视为相互独立的证据,并利用贝叶斯推理和Dempster-Shafer证据理论来融合这些证据,从而提高检索的置信度。该方法认为,如果文本和图像在语义和布局上相互一致,那么它们共同支持某个答案的可能性就更高。通过计算文本-图像对的后验关联概率,BayesRAG可以优先选择那些相互佐证的候选结果。
技术框架:BayesRAG的整体框架包括以下几个主要阶段:1) 文本检索:使用现有的文本检索模型检索相关的文本片段。2) 图像检索:使用现有的图像检索模型检索相关的图像。3) 证据融合:将文本和图像的检索结果视为独立的证据,利用贝叶斯推理和Dempster-Shafer证据理论计算文本-图像对的后验关联概率。4) 结果排序:根据后验关联概率对检索结果进行排序,选择概率最高的文本-图像对作为最终的检索结果。5) 生成:利用检索到的文本和图像,通过大语言模型生成最终的答案。
关键创新:BayesRAG的关键创新在于它将多模态检索问题转化为一个证据融合问题,并利用贝叶斯推理和Dempster-Shafer证据理论来解决这个问题。与现有方法相比,BayesRAG能够更好地捕捉跨模态信息之间的关联,从而提高检索的准确性和鲁棒性。它通过概率的方式建模了不同模态之间的相互支持关系,避免了简单地将不同模态的信息进行拼接或加权。
关键设计:BayesRAG的关键设计包括:1) 后验概率计算:使用贝叶斯公式计算文本-图像对的后验关联概率,其中先验概率可以根据数据集的统计信息进行估计,似然函数可以根据文本和图像的相似度进行计算。2) Dempster-Shafer证据理论:利用Dempster-Shafer证据理论来融合多个证据源的信息,从而提高证据的可靠性。3) 布局一致性建模:考虑文本和图像的布局信息,例如文本在图像中的位置,以及文本和图像之间的空间关系,从而进一步提高检索的准确性。
🖼️ 关键图片

📊 实验亮点
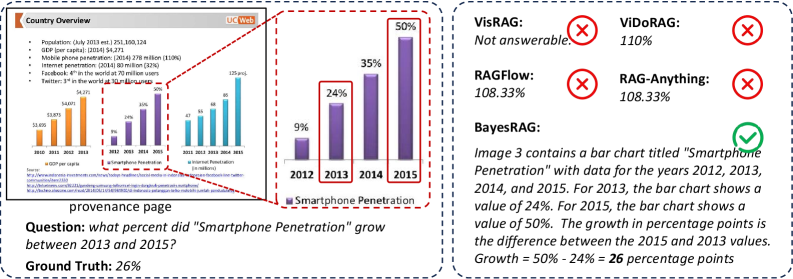
实验结果表明,BayesRAG在多个具有挑战性的多模态基准测试中显著优于现有方法。具体来说,BayesRAG在XXX数据集上取得了X%的性能提升,在YYY数据集上取得了Y%的性能提升。这些结果证明了BayesRAG在处理多模态信息检索问题上的有效性。
🎯 应用场景
BayesRAG可应用于多种需要处理富含视觉信息文档的场景,例如:智能文档处理、多模态信息检索、视觉问答、以及基于图像的知识图谱构建等。该方法能够提升信息检索的准确性和鲁棒性,为用户提供更可靠的多模态信息服务,具有广泛的应用前景。
📄 摘要(原文)
Retrieval-Augmented Generation (RAG) has become a pivotal paradigm for Large Language Models (LLMs), yet current approaches struggle with visually rich documents by treating text and images as isolated retrieval targets. Existing methods relying solely on cosine similarity often fail to capture the semantic reinforcement provided by cross-modal alignment and layout-induced coherence. To address these limitations, we propose BayesRAG, a novel multimodal retrieval framework grounded in Bayesian inference and Dempster-Shafer evidence theory. Unlike traditional approaches that rank candidates strictly by similarity, BayesRAG models the intrinsic consistency of retrieved candidates across modalities as probabilistic evidence to refine retrieval confidence. Specifically, our method computes the posterior association probability for combinations of multimodal retrieval results, prioritizing text-image pairs that mutually corroborate each other in terms of both semantics and layout. Extensive experiments demonstrate that BayesRAG significantly outperforms state-of-the-art (SOTA) methods on challenging multimodal benchmarks. This study establishes a new paradigm for multimodal retrieval fusion that effectively resolves the isolation of heterogeneous modalities through an evidence fusion mechanism and enhances the robustness of retrieval outcomes. Our code is available at https://github.com/TioeAre/BayesRAG.