Structured Reasoning for Large Language Models
作者: Jinyi Han, Zixiang Di, Zishang Jiang, Ying Liao, Jiaqing Liang, Yongqi Wang, Yanghua Xiao
分类: cs.CL
发布日期: 2026-01-12
💡 一句话要点
提出结构化推理(SCR)框架,提升大语言模型推理效率和自验证能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 结构化推理 推理效率 自验证 强化学习
📋 核心要点
- 现有大语言模型推理过程冗余,存在不必要的验证和修正,缺乏对关键推理能力的针对性监督。
- 提出结构化推理(SCR)框架,将推理轨迹解耦为可评估和训练的组件,采用生成-验证-修正范式。
- 实验表明,SCR显著提高了推理效率和自验证能力,并减少了输出token长度。
📝 摘要(中文)
大型语言模型(LLMs)通过生成长链思维过程来实现强大的性能,但过长的轨迹往往会引入冗余或无效的推理步骤。一个典型的现象是,即使已经得出正确的答案,它们也经常执行不必要的验证和修正。这种局限性源于推理轨迹的非结构化性质,以及缺乏对关键推理能力的针对性监督。为了解决这个问题,我们提出了结构化推理(SCR),该框架将推理轨迹解耦为显式的、可评估的和可训练的组件。我们主要使用生成-验证-修正范式来实现SCR。具体来说,我们构建结构化的训练数据,并应用动态终止监督来指导模型决定何时终止推理。为了避免不同推理能力的学习信号之间的干扰,我们采用渐进式的两阶段强化学习策略:第一阶段针对初始生成和自我验证,第二阶段侧重于修正。在三个骨干模型上的大量实验表明,SCR显著提高了推理效率和自我验证能力。此外,与现有的推理范式相比,它最多可减少50%的输出token长度。
🔬 方法详解
问题定义:现有的大语言模型在进行复杂推理时,通常会生成很长的推理链。然而,这些推理链中往往包含大量的冗余步骤,例如不必要的验证和修正,即使模型已经得到了正确的答案。这种非结构化的推理方式导致效率低下,并且难以针对性地提升模型的关键推理能力。
核心思路:论文的核心思路是将非结构化的推理过程分解为结构化的、可评估的组件。通过显式地建模推理过程中的不同阶段(生成、验证、修正),并对每个阶段进行针对性的训练,从而提高推理的效率和准确性。这种结构化的方法使得模型能够更好地理解推理过程中的关键步骤,并避免不必要的冗余操作。
技术框架:SCR框架主要采用生成-验证-修正(Generate-Verify-Revise)的范式。首先,模型生成一个初始的推理结果;然后,模型对该结果进行自我验证,判断其是否正确;最后,如果验证结果为错误,则模型对初始结果进行修正。为了训练模型,论文构建了结构化的训练数据,并应用动态终止监督(Dynamic Termination Supervision)来指导模型何时停止推理。
关键创新:SCR的关键创新在于将推理过程显式地结构化,并针对不同的推理阶段进行独立的训练。与传统的端到端训练方法相比,SCR能够更好地控制推理过程,并提高推理的效率和准确性。此外,动态终止监督的引入使得模型能够自适应地决定何时停止推理,从而避免了不必要的冗余步骤。
关键设计:为了避免不同推理能力的学习信号之间的干扰,论文采用了一种渐进式的两阶段强化学习策略。第一阶段主要针对初始生成和自我验证进行训练,目标是使模型能够生成合理的初始结果,并准确地判断其是否正确。第二阶段则侧重于修正,目标是使模型能够有效地修正错误的初始结果。损失函数的设计也考虑了不同阶段的特点,例如,在第一阶段,论文使用了奖励函数来鼓励模型生成正确的初始结果,并惩罚错误的验证结果;在第二阶段,论文使用了奖励函数来鼓励模型有效地修正错误的初始结果。
🖼️ 关键图片

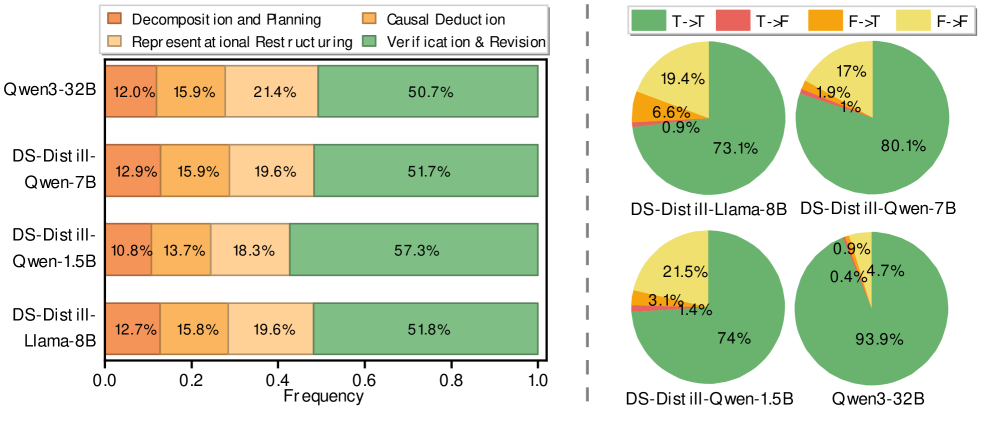

📊 实验亮点
实验结果表明,SCR框架在三个骨干模型上都取得了显著的性能提升,包括推理效率和自验证能力。与现有的推理范式相比,SCR最多可减少50%的输出token长度,这意味着模型在生成推理结果时更加简洁高效。这些结果表明,结构化推理是一种有效的提高大语言模型推理能力的方法。
🎯 应用场景
该研究成果可应用于各种需要复杂推理的场景,例如问答系统、对话系统、代码生成等。通过提高推理效率和准确性,可以提升这些系统的性能和用户体验。此外,结构化推理的方法也有助于提高模型的可解释性,使得人们更容易理解模型的推理过程,并进行调试和改进。未来,该方法可以进一步扩展到更复杂的推理任务中,例如多步推理、常识推理等。
📄 摘要(原文)
Large language models (LLMs) achieve strong performance by generating long chains of thought, but longer traces always introduce redundant or ineffective reasoning steps. One typical behavior is that they often perform unnecessary verification and revisions even if they have reached the correct answers. This limitation stems from the unstructured nature of reasoning trajectories and the lack of targeted supervision for critical reasoning abilities. To address this, we propose Structured Reasoning (SCR), a framework that decouples reasoning trajectories into explicit, evaluable, and trainable components. We mainly implement SCR using a Generate-Verify-Revise paradigm. Specifically, we construct structured training data and apply Dynamic Termination Supervision to guide the model in deciding when to terminate reasoning. To avoid interference between learning signals for different reasoning abilities, we adopt a progressive two-stage reinforcement learning strategy: the first stage targets initial generation and self-verification, and the second stage focuses on revision. Extensive experiments on three backbone models show that SCR substantially improves reasoning efficiency and self-verification. Besides, compared with existing reasoning paradigms, it reduces output token length by up to 50%.