Speculative Decoding: Performance or Illusion?
作者: Xiaoxuan Liu, Jiaxiang Yu, Jongseok Park, Ion Stoica, Alvin Cheung
分类: cs.CL, cs.AI
发布日期: 2025-12-31
💡 一句话要点
系统性分析推测解码在生产级LLM推理引擎中的加速效果与瓶颈
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推测解码 大型语言模型 推理加速 vLLM 性能评估
📋 核心要点
- 现有推测解码(SD)评估多基于研究原型和小批量,缺乏在生产环境下的系统性分析,难以反映真实加速效果。
- 该研究在生产级推理引擎vLLM上,针对多种SD变体、工作负载、模型规模和批量大小进行了全面评估。
- 实验结果揭示了SD性能瓶颈在于目标模型验证,实际加速效果与理论上限存在显著差距,为未来研究指明方向。
📝 摘要(中文)
推测解码(SD)已成为加速大型语言模型(LLM)推理的常用技术,但其实际效果尚不明确,因为之前的评估依赖于研究原型和不切实际的小批量大小。我们提出了,据我们所知,第一个在生产级和广泛部署的推理引擎(vLLM)上对SD进行系统研究,涵盖了多种SD变体($n$-gram, EAGLE/EAGLE-3, Draft-Model, Multi-Token Prediction),涉及不同的工作负载、模型规模和批量大小。我们分析了影响SD性能的关键因素,并量化了SD加速的理论上限。我们的结果表明,目标模型的验证主导了执行,而接受长度在输出token位置、请求和数据集之间差异显著。将测量性能与理论界限进行比较,揭示了观察到的性能与理论上限之间的巨大差距,我们利用这一观察结果来强调我们的研究在改进SD方面开辟的新的研究机会。
🔬 方法详解
问题定义:论文旨在解决推测解码(Speculative Decoding, SD)在实际生产环境中加速大型语言模型(Large Language Model, LLM)推理效果不明确的问题。现有研究多集中于研究原型和小规模实验,无法准确反映SD在工业级推理引擎中的性能表现。现有方法的痛点在于缺乏对SD在不同模型规模、工作负载和批量大小下的系统性分析,难以揭示其性能瓶颈和优化方向。
核心思路:论文的核心思路是通过在生产级推理引擎vLLM上进行大规模实验,系统性地评估多种SD变体(如n-gram、EAGLE等)的性能。通过对比实际性能与理论上限,分析影响SD性能的关键因素,从而找出SD的瓶颈并为未来的优化提供指导。论文强调了目标模型验证的开销是SD性能的主要限制因素。
技术框架:论文的技术框架主要包括以下几个阶段:1) 在vLLM上部署和配置多种SD变体;2) 设计不同的工作负载,包括不同的数据集、模型规模和批量大小;3) 测量和分析SD的实际性能,包括加速比、接受长度等指标;4) 计算SD的理论加速上限,并与实际性能进行对比;5) 分析影响SD性能的关键因素,如目标模型验证的开销。
关键创新:论文最重要的技术创新点在于首次在生产级推理引擎上对SD进行了系统性评估,揭示了SD在实际应用中的性能瓶颈。通过对比实际性能与理论上限,论文指出了目标模型验证是SD性能的主要限制因素,为未来的优化方向提供了新的视角。
关键设计:论文的关键设计包括:1) 选择vLLM作为评估平台,因为它是一个广泛部署的生产级推理引擎;2) 涵盖多种SD变体,包括n-gram、EAGLE等,以评估不同SD算法的性能;3) 设计不同的工作负载,包括不同的数据集、模型规模和批量大小,以评估SD在不同场景下的性能;4) 使用精确的测量方法来评估SD的实际性能,包括加速比、接受长度等指标;5) 使用理论分析来计算SD的理论加速上限,并与实际性能进行对比。
🖼️ 关键图片

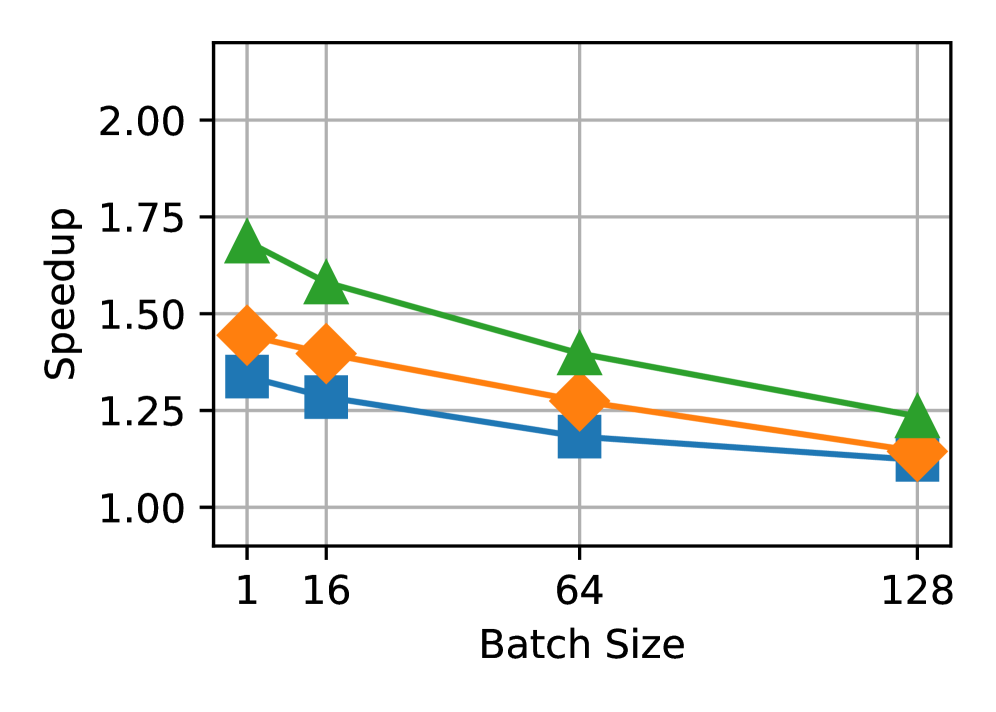
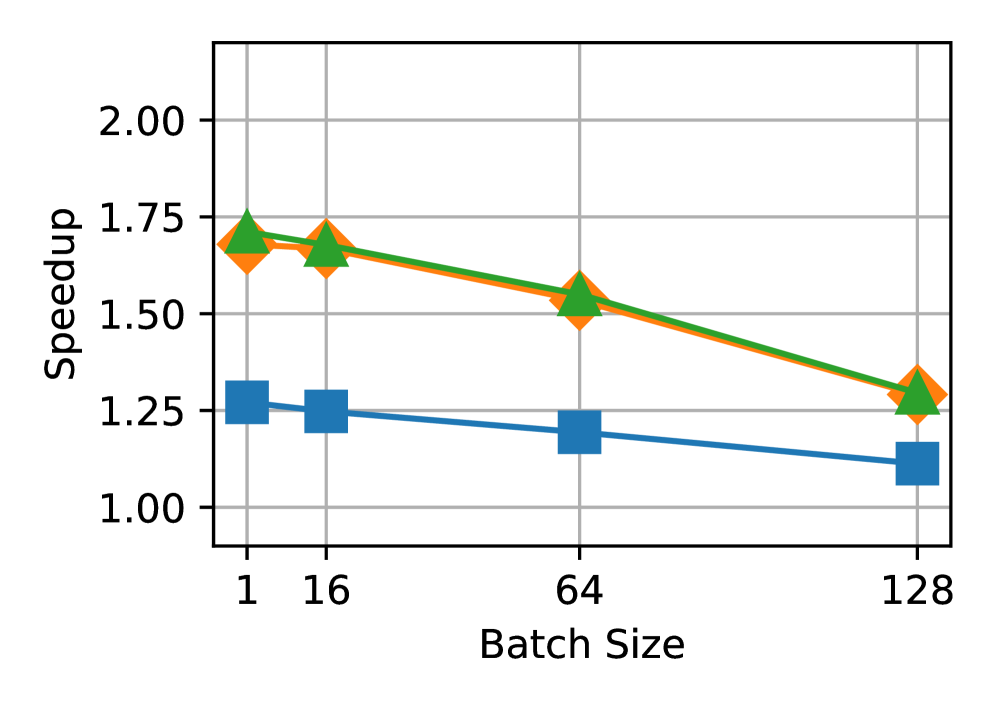
📊 实验亮点
实验结果表明,目标模型的验证是SD执行的主要瓶颈,验证开销占比显著。实际加速效果与理论上限之间存在较大差距,表明SD仍有很大的优化空间。接受长度在不同token位置、请求和数据集之间差异显著,提示需要更精细的SD策略。该研究为SD的未来发展方向提供了重要参考。
🎯 应用场景
该研究成果可应用于各种需要加速LLM推理的场景,例如在线对话系统、文本生成服务等。通过深入理解SD的性能瓶颈,可以指导开发更高效的SD算法和推理引擎,从而降低计算成本,提高用户体验。未来的研究可以基于此,探索新的SD优化策略,例如降低目标模型验证的开销。
📄 摘要(原文)
Speculative decoding (SD) has become a popular technique to accelerate Large Language Model (LLM) inference, yet its real-world effectiveness remains unclear as prior evaluations rely on research prototypes and unrealistically small batch sizes. We present, to our knowledge, the first systematic study of SD on a production-grade and widely deployed inference engine (vLLM), covering multiple SD variants ($n$-gram, EAGLE/EAGLE-3, Draft-Model, Multi-Token Prediction) across diverse workloads, model scales, and batch sizes. We analyze key factors governing SD performance, and quantify a theoretical upper bound on SD speedup. Our results show that verification by the target model dominates the execution, while acceptance length varies markedly across output token positions, requests, and datasets. Comparing measured performance with theoretical bounds reveals substantial gaps between observed and theoretical upper bounds, and we leverage this observation to highlight new research opportunities that our study opens up in improving SD.