PCEval: A Benchmark for Evaluating Physical Computing Capabilities of Large Language Models
作者: Inpyo Song, Eunji Jeon, Jangwon Lee
分类: cs.CL, cs.AI
发布日期: 2025-12-31
备注: Code and Dataset available at https://github.com/Null99-Dog/PCEval-Dataset
💡 一句话要点
PCEval:用于评估大语言模型物理计算能力的首个自动化基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 物理计算 自动化评估 基准测试 硬件设计
📋 核心要点
- 现有大语言模型在物理计算等硬件约束场景下的能力评估不足,缺乏自动化评估基准。
- 提出PCEval基准,通过自动化评估LLM在逻辑电路设计、代码生成和物理布局方面的能力。
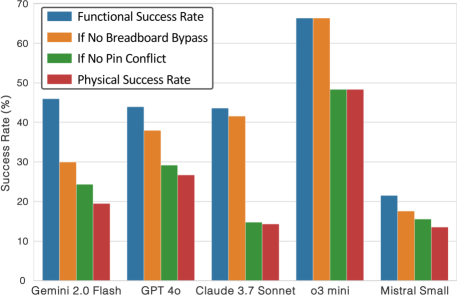
- 实验结果表明,LLM在代码生成和逻辑电路设计方面表现良好,但在物理面包板布局方面存在困难。
📝 摘要(中文)
大语言模型(LLMs)在软件开发、教育和技术辅助等多个领域展现了卓越的能力。其中,软件开发是LLMs日益普及的关键领域之一。然而,当考虑硬件约束时——例如,在物理计算中,软件必须与物理硬件交互并控制它——它们的有效性尚未得到充分探索。为了解决这一差距,我们引入了 extsc{PCEval} (物理计算评估),这是物理计算中的第一个基准,它能够对LLM在项目的逻辑和物理方面的能力进行完全自动化的评估,而无需人工评估。我们的评估框架评估LLMs在生成电路和生成跨不同项目复杂程度的兼容代码方面的能力。通过对13个领先模型进行全面测试, extsc{PCEval}提供了第一个可重现且自动验证的经验评估,评估了LLMs在仿真环境中推理基本硬件实现约束的能力。我们的研究结果表明,虽然LLMs在代码生成和逻辑电路设计方面表现良好,但它们在物理面包板布局创建方面表现不佳,尤其是在管理正确的引脚连接和避免电路错误方面。 extsc{PCEval}提高了我们对AI在硬件相关计算环境中辅助能力的理解,并为开发更有效的工具来支持物理计算教育奠定了基础。
🔬 方法详解
问题定义:现有的大语言模型在软件开发领域取得了显著进展,但在物理计算领域,由于涉及到硬件约束,例如电路设计和物理布局,其能力尚未得到充分评估。现有的评估方法通常依赖于人工评估,效率低下且难以重现。因此,需要一个自动化的基准来评估LLM在物理计算方面的能力,特别是其在逻辑电路设计、代码生成和物理布局方面的表现。
核心思路:PCEval的核心思路是构建一个自动化的评估框架,该框架能够模拟物理计算环境,并评估LLM在生成电路和代码方面的能力。该框架通过定义一系列具有不同复杂度的物理计算任务,并自动验证LLM生成的电路和代码的正确性,从而实现对LLM物理计算能力的客观评估。这种方法避免了人工评估的主观性和低效率,并提供了可重现的评估结果。
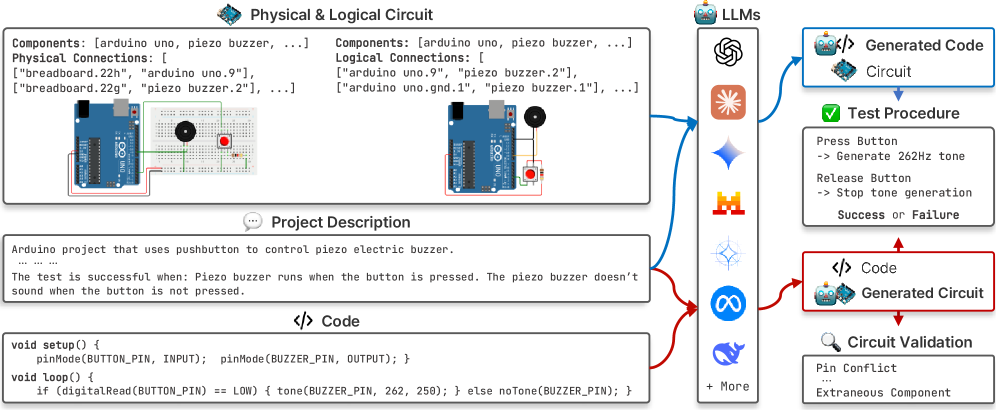
技术框架:PCEval的整体框架包括以下几个主要模块:1) 任务生成模块:该模块负责生成不同复杂度的物理计算任务,包括逻辑电路设计、代码生成和物理布局。2) LLM调用模块:该模块负责调用LLM,并向其提供任务描述,然后接收LLM生成的电路和代码。3) 仿真验证模块:该模块负责对LLM生成的电路和代码进行仿真验证,以确定其是否满足任务要求。4) 评估指标计算模块:该模块负责计算评估指标,例如电路的正确率、代码的执行效率和物理布局的合理性。
关键创新:PCEval最重要的创新点在于其自动化评估的能力。与以往依赖人工评估的方法不同,PCEval能够自动生成任务、调用LLM、验证结果和计算评估指标,从而实现了对LLM物理计算能力的全面、客观和可重现的评估。此外,PCEval还考虑了物理计算中的硬件约束,例如引脚连接和电路错误,从而更真实地反映了LLM在实际应用中的表现。
关键设计:PCEval的关键设计包括:1) 任务复杂度的控制:通过调整任务的规模和难度,可以评估LLM在不同复杂程度下的表现。2) 仿真环境的构建:PCEval构建了一个真实的物理计算仿真环境,可以模拟电路的运行和物理布局。3) 评估指标的选择:PCEval选择了一系列能够全面反映LLM物理计算能力的评估指标,例如电路的正确率、代码的执行效率和物理布局的合理性。4) 错误类型的定义:PCEval定义了一系列常见的电路错误类型,例如短路和断路,可以评估LLM在避免这些错误方面的能力。
🖼️ 关键图片

📊 实验亮点
PCEval对13个领先的LLM进行了全面测试,结果表明,LLM在代码生成和逻辑电路设计方面表现良好,但在物理面包板布局创建方面表现不佳,尤其是在管理正确的引脚连接和避免电路错误方面。该基准为评估LLM在硬件相关计算环境中的能力提供了可重现和自动验证的经验评估。
🎯 应用场景
PCEval可应用于评估和提升大语言模型在物理计算、机器人控制、嵌入式系统等领域的应用能力。通过该基准,可以促进AI辅助硬件设计工具的开发,并为物理计算教育提供更有效的支持,例如自动生成教学案例和评估学生的设计方案。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable capabilities across various domains, including software development, education, and technical assistance. Among these, software development is one of the key areas where LLMs are increasingly adopted. However, when hardware constraints are considered-for instance, in physical computing, where software must interact with and control physical hardware -their effectiveness has not been fully explored. To address this gap, we introduce \textsc{PCEval} (Physical Computing Evaluation), the first benchmark in physical computing that enables a fully automatic evaluation of the capabilities of LLM in both the logical and physical aspects of the projects, without requiring human assessment. Our evaluation framework assesses LLMs in generating circuits and producing compatible code across varying levels of project complexity. Through comprehensive testing of 13 leading models, \textsc{PCEval} provides the first reproducible and automatically validated empirical assessment of LLMs' ability to reason about fundamental hardware implementation constraints within a simulation environment. Our findings reveal that while LLMs perform well in code generation and logical circuit design, they struggle significantly with physical breadboard layout creation, particularly in managing proper pin connections and avoiding circuit errors. \textsc{PCEval} advances our understanding of AI assistance in hardware-dependent computing environments and establishes a foundation for developing more effective tools to support physical computing education.