Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
作者: Junru Lu, Jiarui Qin, Lingfeng Qiao, Yinghui Li, Xinyi Dai, Bo Ke, Jianfeng He, Ruizhi Qiao, Di Yin, Xing Sun, Yunsheng Wu, Yinsong Liu, Shuangyin Liu, Mingkong Tang, Haodong Lin, Jiayi Kuang, Fanxu Meng, Xiaojuan Tang, Yunjia Xi, Junjie Huang, Haotong Yang, Zhenyi Shen, Yangning Li, Qianwen Zhang, Yifei Yu, Siyu An, Junnan Dong, Qiufeng Wang, Jie Wang, Keyu Chen, Wei Wen, Taian Guo, Zhifeng Shen, Daohai Yu, Jiahao Li, Ke Li, Zongyi Li, Xiaoyu Tan
分类: cs.CL
发布日期: 2025-12-31 (更新: 2026-01-05)
备注: 57 pages, 26 figures
💡 一句话要点
提出Youtu-LLM,一种轻量级且具备原生Agent能力的语言模型,性能超越同规模模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 轻量级LLM Agent智能 长上下文 课程学习 多潜在注意力 从头预训练 STEM教育
📋 核心要点
- 现有小模型依赖蒸馏,推理和规划能力不足,难以胜任复杂Agent任务。
- Youtu-LLM采用从头预训练方式,构建紧凑架构并设计课程学习,提升模型认知能力。
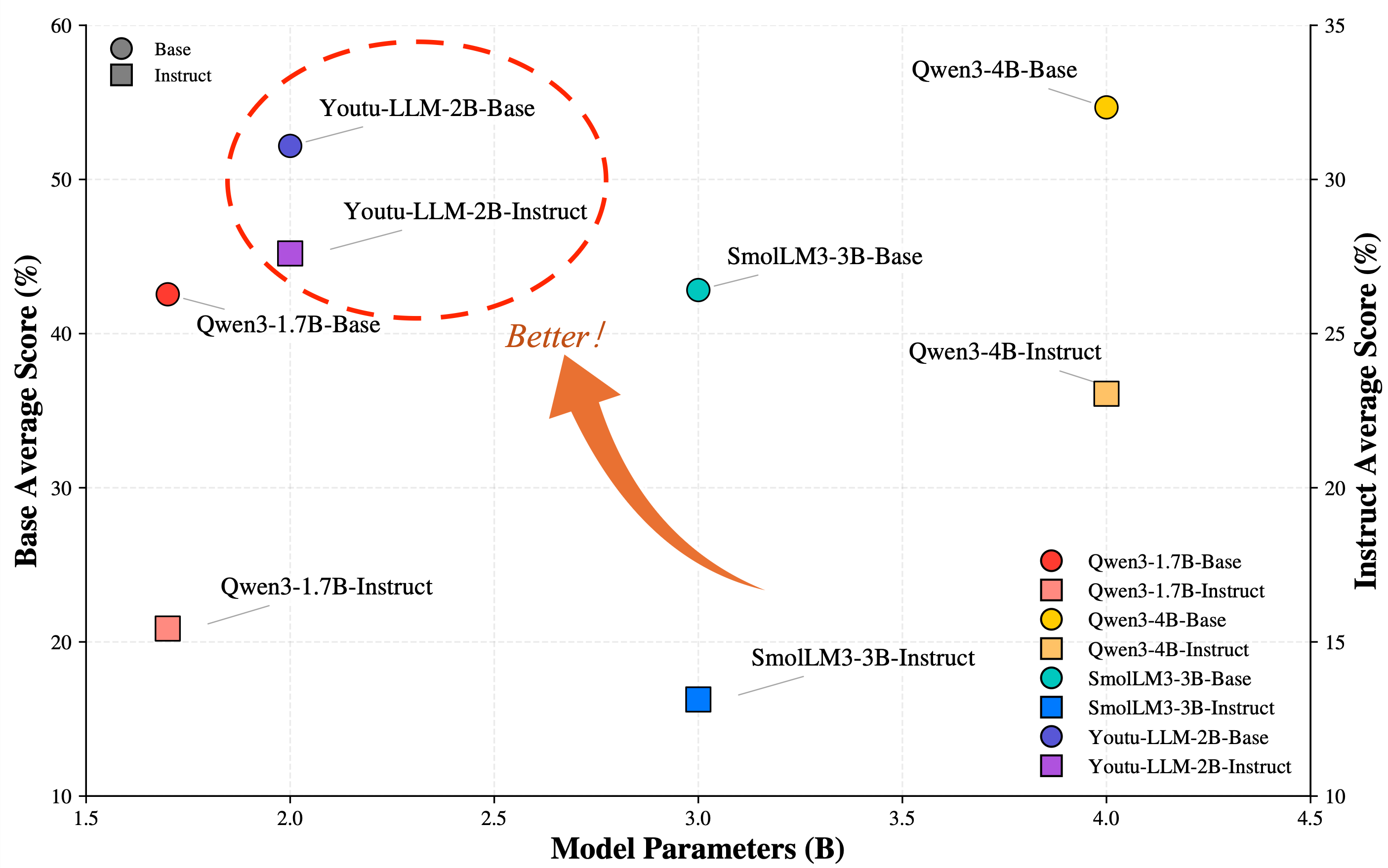
- 实验表明,Youtu-LLM在通用和Agent任务上均超越现有2B以下模型,展现强大Agent能力。
📝 摘要(中文)
本文介绍Youtu-LLM,一种轻量级但功能强大的语言模型,它兼顾了高计算效率和原生Agent智能。与依赖蒸馏的典型小型模型不同,Youtu-LLM (1.96B) 从头开始预训练,以系统地培养推理和规划能力。主要技术进步如下:(1) 具有长上下文支持的紧凑架构:Youtu-LLM 构建在具有新型 STEM 导向词汇表的密集多潜在注意力 (MLA) 架构之上,支持 128k 上下文窗口。这种设计在最小的内存占用内实现了强大的长上下文推理和状态跟踪,使其成为长程 Agent 和推理任务的理想选择。(2) 有原则的“常识-STEM-Agent”课程:我们整理了一个大约 11T tokens 的大型语料库,并实施了多阶段训练策略。通过逐步将预训练数据分布从一般常识转移到复杂的 STEM 和 Agent 任务,我们确保模型获得深刻的认知能力,而不是表面上的对齐。(3) 可扩展的 Agent 中期训练:专门针对 Agent 中期训练,我们采用多样化的数据构建方案来合成跨数学、编码和工具使用领域的丰富多样的轨迹。这种高质量的数据使模型能够有效地内化规划和反思行为。广泛的评估表明,Youtu-LLM 为 2B 以下的 LLM 树立了新的技术水平。在通用基准测试中,它实现了与更大模型相比具有竞争力的性能,而在特定于 Agent 的任务中,它显着超越了现有的 SOTA 基线,表明轻量级模型可以拥有强大的内在 Agent 能力。
🔬 方法详解
问题定义:现有的小型语言模型通常依赖于知识蒸馏,这限制了它们的原生推理和规划能力,尤其是在需要长上下文理解和复杂决策的Agent任务中。这些模型难以在计算效率和智能水平之间取得平衡。
核心思路:Youtu-LLM的核心思路是从头开始预训练一个轻量级的语言模型,并采用专门设计的训练策略,使其能够原生具备强大的Agent能力。通过构建紧凑的架构、支持长上下文以及采用多阶段课程学习,模型能够逐步掌握常识、STEM知识和Agent技能。
技术框架:Youtu-LLM的整体框架包括三个主要阶段:预训练阶段、中期训练阶段和微调阶段。预训练阶段使用大规模的通用语料库,中期训练阶段专注于Agent任务相关的数据,微调阶段则针对特定任务进行优化。模型架构基于多潜在注意力(MLA),并支持长达128k的上下文窗口。
关键创新:Youtu-LLM的关键创新在于其“常识-STEM-Agent”课程学习策略和可扩展的Agent中期训练方法。课程学习策略通过逐步增加训练数据的难度,使模型能够循序渐进地掌握知识和技能。Agent中期训练则通过合成多样化的数据,使模型能够学习规划和反思行为。
关键设计:Youtu-LLM采用了STEM导向的词汇表,以更好地支持科学和技术领域的任务。在训练过程中,使用了多种损失函数,包括语言模型损失、对比学习损失等,以提高模型的性能。此外,模型还采用了数据增强技术,以增加训练数据的多样性。
🖼️ 关键图片


📊 实验亮点
Youtu-LLM在多个基准测试中取得了显著成果。在通用基准测试中,它与更大的模型相比具有竞争力。在Agent特定任务中,它显著超越了现有的SOTA基线,证明了轻量级模型可以拥有强大的内在Agent能力。具体性能数据和提升幅度在论文中有详细展示。
🎯 应用场景
Youtu-LLM凭借其轻量级和强大的Agent能力,可广泛应用于资源受限的场景,如移动设备、嵌入式系统和边缘计算环境。它能够支持智能助手、自动化客服、智能家居控制等应用,并有望在机器人、自动驾驶等领域发挥重要作用,实现更智能、更高效的自动化。
📄 摘要(原文)
We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.