Understanding and Steering the Cognitive Behaviors of Reasoning Models at Test-Time
作者: Zhenyu Zhang, Xiaoxia Wu, Zhongzhu Zhou, Qingyang Wu, Yineng Zhang, Pragaash Ponnusamy, Harikaran Subbaraj, Jue Wang, Shuaiwen Leon Song, Ben Athiwaratkun
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-12-31 (更新: 2026-01-19)
💡 一句话要点
提出CREST,通过干预注意力头引导LLM推理,提升效率和准确率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 链式思维 注意力机制 推理引导 认知行为
📋 核心要点
- 现有LLM推理过程存在效率问题,表现为token生成过多导致延迟高,以及推理过程不稳定,在欠思考和过度思考间切换。
- 论文提出CREST方法,通过离线校准识别与特定认知行为相关的注意力头,并在推理时干预这些头,抑制低效推理模式。
- 实验结果表明,CREST在提高推理准确率的同时,显著降低了token使用量,实现了更快更可靠的LLM推理。
📝 摘要(中文)
大型语言模型(LLMs)通常依赖于长链式思维(CoT)推理来解决复杂任务。虽然有效,但这些轨迹常常效率低下,导致过多的token生成带来的高延迟,或不稳定的推理,在欠思考(浅薄、不一致的步骤)和过度思考(重复、冗长的推理)之间交替。本文研究了推理轨迹的结构,并发现了与验证和回溯等不同认知行为相关的特定注意力头。通过在推理时对这些头进行轻微干预,我们可以引导模型远离低效模式。基于此,我们提出了CREST,一种用于测试时认知推理引导的免训练方法。CREST包含两个组成部分:(1)离线校准步骤,用于识别认知头并导出特定于头的引导向量;(2)推理时程序,用于旋转隐藏表示以抑制沿这些向量的分量。CREST自适应地抑制无益的推理行为,从而提高准确性并降低计算成本。在不同的推理基准和模型上,CREST将准确率提高了高达17.5%,同时减少了37.6%的token使用量,为更快、更可靠的LLM推理提供了一条简单有效的途径。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在进行链式思维(CoT)推理时效率低下的问题。现有的CoT方法虽然能够解决复杂任务,但常常产生冗长且不稳定的推理轨迹,导致计算成本高昂和推理质量下降。具体表现为欠思考(推理步骤浅薄、不一致)和过度思考(推理步骤重复、冗长)。
核心思路:论文的核心思路是通过识别并干预LLM中与特定认知行为(如验证和回溯)相关的注意力头,从而引导模型避免低效的推理模式。通过抑制这些“认知头”的不良行为,可以提高推理效率和准确性。这种方法无需额外的训练,可以在测试时直接应用。
技术框架:CREST方法包含两个主要阶段:离线校准和推理时引导。 1. 离线校准:该阶段旨在识别与特定认知行为相关的注意力头,并为每个头计算一个引导向量。具体做法是分析模型在不同推理轨迹上的行为,找到与欠思考或过度思考相关的注意力模式。 2. 推理时引导:在推理过程中,CREST会旋转模型的隐藏表示,以抑制沿引导向量方向的分量。这相当于抑制了与低效认知行为相关的注意力头的激活,从而引导模型朝着更高效的推理路径前进。
关键创新:CREST的关键创新在于发现了LLM中存在与特定认知行为相关的注意力头,并提出了一种免训练的干预方法来引导模型的推理过程。与传统的微调或知识蒸馏方法不同,CREST无需额外的训练数据或计算资源,可以直接应用于现有的LLM。
关键设计: 1. 认知头识别:通过分析模型在不同推理轨迹上的注意力模式,使用相关性分析等方法识别与特定认知行为(如验证、回溯)相关的注意力头。 2. 引导向量计算:为每个认知头计算一个引导向量,该向量代表了该头在低效推理模式下的激活方向。 3. 隐藏表示旋转:在推理时,使用引导向量旋转模型的隐藏表示,以抑制与低效认知行为相关的分量。旋转角度或幅度可以通过实验进行调整,以达到最佳的性能。
🖼️ 关键图片
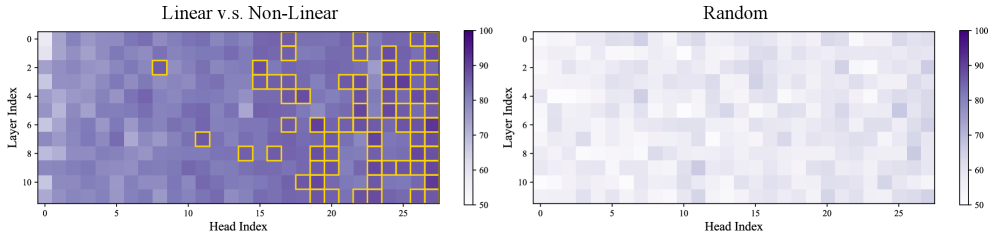
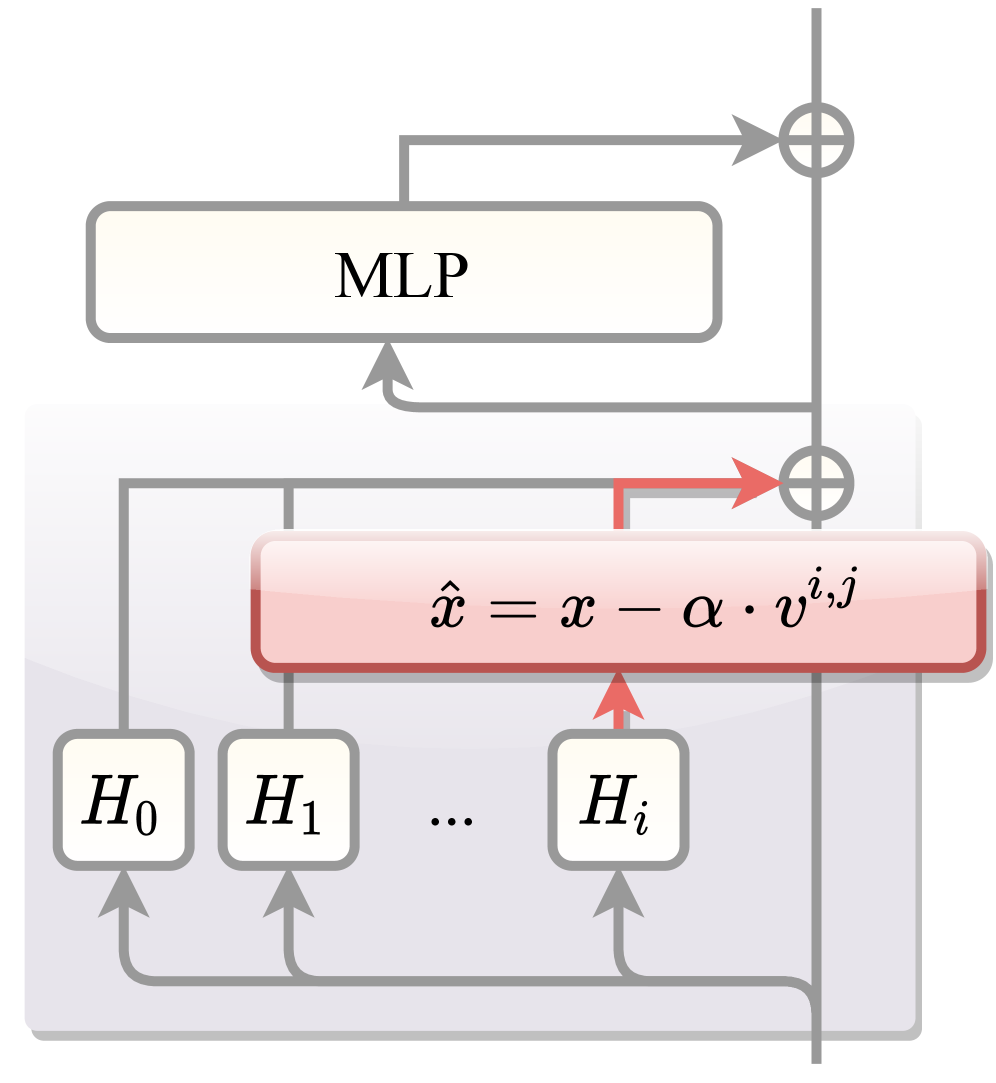

📊 实验亮点
实验结果表明,CREST在多个推理基准测试中显著提高了LLM的性能。例如,在某些任务上,CREST将准确率提高了高达17.5%,同时减少了37.6%的token使用量。这些结果表明,CREST是一种简单而有效的LLM推理优化方法。
🎯 应用场景
CREST方法可应用于各种需要LLM进行复杂推理的场景,例如问答系统、代码生成、数学问题求解等。通过提高推理效率和准确率,CREST可以降低LLM的部署成本,并提升用户体验。该方法还有助于理解LLM的内部工作机制,为开发更高效、更可控的LLM提供新的思路。
📄 摘要(原文)
Large Language Models (LLMs) often rely on long chain-of-thought (CoT) reasoning to solve complex tasks. While effective, these trajectories are frequently inefficient, leading to high latency from excessive token generation, or unstable reasoning that alternates between underthinking (shallow, inconsistent steps) and overthinking (repetitive, verbose reasoning). In this work, we study the structure of reasoning trajectories and uncover specialized attention heads that correlate with distinct cognitive behaviors such as verification and backtracking. By lightly intervening on these heads at inference time, we can steer the model away from inefficient modes. Building on this insight, we propose CREST, a training-free method for Cognitive REasoning Steering at Test-time. CREST has two components: (1) an offline calibration step that identifies cognitive heads and derives head-specific steering vectors, and (2) an inference-time procedure that rotates hidden representations to suppress components along those vectors. CREST adaptively suppresses unproductive reasoning behaviors, yielding both higher accuracy and lower computational cost. Across diverse reasoning benchmarks and models, CREST improves accuracy by up to 17.5% while reducing token usage by 37.6%, offering a simple and effective pathway to faster, more reliable LLM reasoning.