LimAgents: Multi-Agent LLMs for Generating Research Limitations
作者: Ibrahim Al Azher, Zhishuai Guo, Hamed Alhoori
分类: cs.CL, cs.AI
发布日期: 2025-12-30
备注: 18 Pages, 9 figures
💡 一句话要点
LimAgents:多智能体LLM框架,用于生成更深入的科研论文局限性分析。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 大型语言模型 科研论文局限性 自动评审 自然语言处理
📋 核心要点
- 现有LLM在识别科研论文局限性时,往往流于表面,缺乏深度的方法论分析和上下文理解。
- LimAgents通过构建多智能体系统,模拟不同角色(如评审员、引用分析师),协同挖掘论文的潜在局限性。
- 实验表明,LimAgents显著提升了局限性识别的覆盖率,优于零样本基线,证明了其有效性。
📝 摘要(中文)
识别和阐述局限性对于透明和严谨的科学研究至关重要。然而,零样本大型语言模型(LLM)通常产生肤浅或笼统的局限性陈述(例如,数据集偏差或泛化性)。它们通常重复作者报告的局限性,而没有关注更深层次的方法论问题和背景差距。由于许多作者只披露部分或不重要的局限性,这个问题变得更加严重。我们提出了LimAgents,一个多智能体LLM框架,用于生成实质性的局限性。LimAgents集成了OpenReview评论和作者声明的局限性,以提供更强的ground truth。它还使用引用的和引用论文来捕捉更广泛的背景弱点。在这种设置中,不同的智能体具有特定的顺序角色:一些提取显式局限性,另一些分析方法论差距,一些模拟同行评审者的观点,一个引用智能体将工作置于更大的文献体系中。一个Judge智能体改进它们的输出,一个Master智能体将它们整合为清晰的集合。这种结构允许系统地识别显式的、隐式的、同行评审关注的和文献知情的局限性。此外,传统的NLP指标(如BLEU、ROUGE和余弦相似度)严重依赖于n-gram或嵌入重叠。它们经常忽略语义上相似的局限性。为了解决这个问题,我们引入了一个逐点评估协议,该协议使用LLM-as-a-Judge来更准确地衡量覆盖率。实验表明,LimAgents大大提高了性能。RAG +多智能体GPT-4o mini配置比零样本基线实现了+15.51%的覆盖率增益,而Llama 3 8B多智能体设置产生了+4.41%的改进。
🔬 方法详解
问题定义:现有方法在识别科研论文的局限性时,存在以下痛点:一是LLM倾向于重复作者已知的局限性,缺乏对方法论深层问题的挖掘;二是LLM难以捕捉论文的上下文信息,无法从引用文献的角度发现潜在问题;三是传统的NLP评价指标难以准确衡量局限性识别的覆盖率,容易忽略语义相似的表达。
核心思路:LimAgents的核心思路是利用多智能体协作,模拟不同的专家角色,从多个角度对论文进行分析,从而更全面、深入地识别其局限性。通过引入OpenReview评论、作者声明的局限性以及引用文献信息,为LLM提供更强的ground truth和上下文信息。
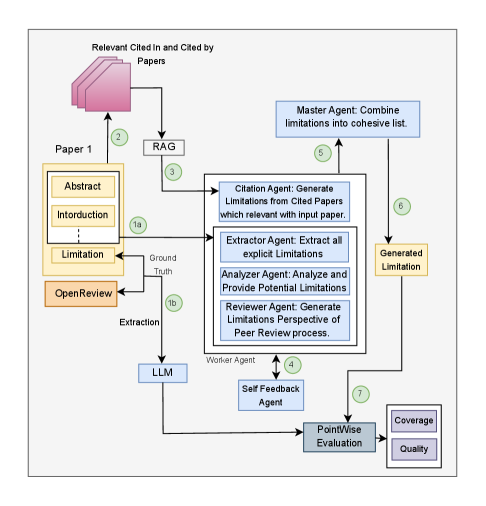
技术框架:LimAgents的技术框架主要包含以下几个模块:1) 显式局限性提取智能体:负责从论文中提取作者明确指出的局限性。2) 方法论差距分析智能体:负责分析论文的方法论是否存在潜在缺陷。3) 同行评审模拟智能体:模拟同行评审者的视角,发现论文可能存在的不足。4) 引用分析智能体:分析论文的引用和被引用情况,从文献角度发现潜在问题。5) Judge智能体:负责评估和改进各个智能体的输出。6) Master智能体:负责整合各个智能体的输出,生成最终的局限性分析报告。
关键创新:LimAgents的关键创新在于:1) 提出了多智能体协作的局限性识别框架,能够从多个角度对论文进行分析。2) 引入了OpenReview评论、作者声明的局限性以及引用文献信息,为LLM提供更强的ground truth和上下文信息。3) 提出了基于LLM的逐点评估协议,能够更准确地衡量局限性识别的覆盖率。
关键设计:在智能体设计方面,论文采用了不同的prompting策略,以引导LLM完成特定的任务。例如,对于同行评审模拟智能体,论文使用了模拟评审员提问的prompt,以促使LLM从评审的角度思考论文的局限性。此外,论文还探索了不同的LLM模型(如GPT-4o和Llama 3)在LimAgents框架下的性能表现。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LimAgents显著提升了局限性识别的覆盖率。RAG + 多智能体GPT-4o mini配置比零样本基线实现了+15.51%的覆盖率增益,而Llama 3 8B多智能体设置也实现了+4.41%的改进。这些结果证明了LimAgents框架的有效性。
🎯 应用场景
LimAgents可应用于科研论文的自动评审、研究方向的探索、以及科研诚信的评估。通过自动识别论文的局限性,可以帮助评审人员更全面地评估论文的质量,帮助研究人员更深入地理解研究领域的现状和挑战,并促进科研诚信的建设。
📄 摘要(原文)
Identifying and articulating limitations is essential for transparent and rigorous scientific research. However, zero-shot large language models (LLMs) approach often produce superficial or general limitation statements (e.g., dataset bias or generalizability). They usually repeat limitations reported by authors without looking at deeper methodological issues and contextual gaps. This problem is made worse because many authors disclose only partial or trivial limitations. We propose LimAgents, a multi-agent LLM framework for generating substantive limitations. LimAgents integrates OpenReview comments and author-stated limitations to provide stronger ground truth. It also uses cited and citing papers to capture broader contextual weaknesses. In this setup, different agents have specific roles as sequential role: some extract explicit limitations, others analyze methodological gaps, some simulate the viewpoint of a peer reviewer, and a citation agent places the work within the larger body of literature. A Judge agent refines their outputs, and a Master agent consolidates them into a clear set. This structure allows for systematic identification of explicit, implicit, peer review-focused, and literature-informed limitations. Moreover, traditional NLP metrics like BLEU, ROUGE, and cosine similarity rely heavily on n-gram or embedding overlap. They often overlook semantically similar limitations. To address this, we introduce a pointwise evaluation protocol that uses an LLM-as-a-Judge to measure coverage more accurately. Experiments show that LimAgents substantially improve performance. The RAG + multi-agent GPT-4o mini configuration achieves a +15.51% coverage gain over zero-shot baselines, while the Llama 3 8B multi-agent setup yields a +4.41% improvement.