Closing the Data Loop: Using OpenDataArena to Engineer Superior Training Datasets
作者: Xin Gao, Xiaoyang Wang, Yun Zhu, Mengzhang Cai, Conghui He, Lijun Wu
分类: cs.CL, cs.AI
发布日期: 2025-12-30
备注: Superior ODA-Math, ODA-Mixture Datasets
💡 一句话要点
利用OpenDataArena构建高质量训练数据集,提升大语言模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数据集工程 监督微调 数据增强 价值基准
📋 核心要点
- 现有SFT数据集构建依赖启发式方法,缺乏对样本贡献的系统性理解,导致模型性能提升受限。
- 提出OpenDataArena(ODA)框架,通过价值基准测试指导数据集构建,形成闭环反馈,优化数据质量。
- 实验表明,基于ODA构建的ODA-Math和ODA-Mixture数据集在数学推理和多领域任务上均取得SOTA结果。
📝 摘要(中文)
监督微调(SFT)数据集的构建在大语言模型(LLM)的后训练阶段至关重要,但现有方法通常依赖于启发式聚合,缺乏对单个样本如何影响模型性能的系统理解。本报告提出了一种范式转变,即利用OpenDataArena(ODA)从临时的数据集管理转向闭环数据集工程框架。该框架利用价值锚定的排序和多维分析,将价值基准测试转化为指导数据集构建的反馈信号。我们通过两个新的数据集来实例化这种方法:ODA-Math-460k,这是一个专门的数学推理数据集,它利用一种新颖的两阶段难度感知管道,在AIME和HMMT等基准测试中实现了最先进(SOTA)的结果;以及ODA-Mixture(100k和500k),这是一系列通过“锚定和修补”策略构建的多领域指令数据集,其性能优于明显更大的开源基线。我们的实验结果表明,ODA驱动的数据集显著提高了领域特定的推理能力和通用效用,同时实现了卓越的数据效率,验证了向以数据为中心的人工智能的转变,其中透明评估是工程高质量训练数据的主要引擎。
🔬 方法详解
问题定义:现有的大语言模型微调过程中,监督微调数据集的构建往往依赖于人工标注或启发式规则,缺乏对数据集中每个样本价值的精确评估和控制。这导致数据集质量参差不齐,模型训练效率低下,难以达到最优性能。现有方法的痛点在于缺乏一个系统性的、可量化的数据工程框架,无法有效地利用数据来提升模型能力。
核心思路:论文的核心思路是将数据集构建过程视为一个闭环的工程问题,通过OpenDataArena(ODA)平台,将模型在验证集上的表现(价值基准)反馈到数据集构建过程中,指导数据的选择、增强和优化。这种“价值锚定”的思路旨在构建一个高质量、高效率的训练数据集,从而提升模型的性能。
技术框架:ODA框架包含以下主要模块:1) 价值基准测试:使用预训练模型在验证集上进行推理,评估每个样本的价值(如loss、accuracy等)。2) 多维分析:对样本进行多维度分析,例如难度、领域、类型等,以便更好地理解样本的特性。3) 数据集构建:基于价值基准和多维分析的结果,采用特定的策略(如难度感知、锚定和修补)来构建训练数据集。4) 模型训练:使用构建的训练数据集对模型进行微调。5) 反馈循环:将模型在验证集上的表现反馈到数据集构建过程中,不断优化数据集。
关键创新:论文的关键创新在于提出了一个闭环的数据集工程框架,将价值基准测试作为数据集构建的指导信号。这种方法打破了传统数据集构建的盲目性,实现了数据驱动的自动化优化。此外,论文还提出了两种具体的数据集构建策略:难度感知的数学推理数据集构建和锚定-修补的多领域数据集构建。
关键设计:在ODA-Math-460k数据集中,采用了两阶段难度感知管道,首先筛选出高质量的数学问题,然后根据难度进行分层,确保数据集的多样性和挑战性。在ODA-Mixture数据集中,采用了“锚定和修补”策略,首先选择一些高质量的“锚定”样本,然后通过数据增强和生成技术来“修补”数据集,增加数据的多样性和覆盖率。具体的参数设置和损失函数选择取决于具体的任务和模型。
🖼️ 关键图片

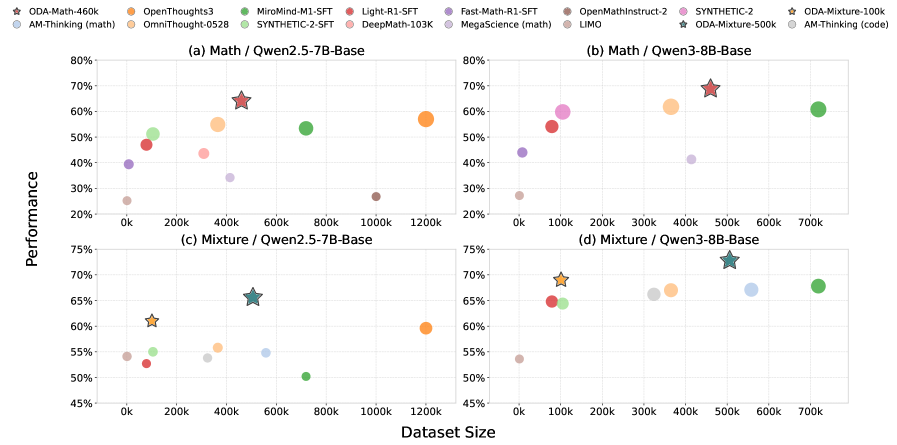
📊 实验亮点
ODA-Math-460k数据集在AIME和HMMT等数学推理基准测试中取得了SOTA结果,验证了难度感知数据集构建策略的有效性。ODA-Mixture数据集(100k和500k)在多领域任务上优于显著更大的开源基线,证明了“锚定和修补”策略的数据效率和泛化能力。这些实验结果表明,通过ODA框架构建的数据集能够显著提升模型的性能和数据利用率。
🎯 应用场景
该研究成果可广泛应用于大语言模型的训练和微调,尤其是在特定领域(如数学、编程等)的知识增强和能力提升方面。通过ODA框架,可以更高效地构建高质量的训练数据集,降低数据标注成本,加速模型迭代,并最终提升模型的性能和泛化能力。未来,该方法有望应用于更多领域,推动数据中心型AI的发展。
📄 摘要(原文)
The construction of Supervised Fine-Tuning (SFT) datasets is a critical yet under-theorized stage in the post-training of Large Language Models (LLMs), as prevalent practices often rely on heuristic aggregation without a systematic understanding of how individual samples contribute to model performance. In this report, we propose a paradigm shift from ad-hoc curation to a closed-loop dataset engineering framework using OpenDataArena (ODA), which leverages value-anchored rankings and multi-dimensional analysis to transform value benchmarking into feedback signals guiding dataset construction. We instantiate this methodology through two new datasets: \textbf{ODA-Math-460k}, a specialized mathematics reasoning dataset that utilizes a novel two-stage difficulty-aware pipeline to achieve State-of-the-Art (SOTA) results on benchmarks such as AIME and HMMT, and \textbf{ODA-Mixture (100k \& 500k)}, a series of multi-domain instruction datasets built via an ``Anchor-and-Patch'' strategy that outperforms significantly larger open-source baselines. Our empirical results demonstrate that ODA-driven datasets significantly improve both domain-specific reasoning and general utility while achieving superior data efficiency, validating a transition toward data-centric AI where transparent evaluation serves as the primary engine for engineering high-quality training data.