Paragraph Segmentation Revisited: Towards a Standard Task for Structuring Speech
作者: Fabian Retkowski, Alexander Waibel
分类: cs.CL
发布日期: 2025-12-30
💡 一句话要点
提出TEDPara和YTSegPara基准,并设计MiniSeg模型,用于提升语音转录文本的段落分割效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 段落分割 语音转录 文本结构化 基准数据集 约束解码
📋 核心要点
- 现有语音转录文本缺乏结构化,影响可读性和再利用,段落分割是关键但被忽视的环节。
- 提出约束解码方法,利用大型语言模型插入段落分隔符,同时保持转录文本的原始语义和句子对齐。
- 构建TEDPara和YTSegPara基准数据集,并设计紧凑模型MiniSeg,在段落分割任务上取得领先性能。
📝 摘要(中文)
自动语音转录通常以非结构化的词流形式呈现,这降低了可读性和再利用性。本文将段落分割重新定义为缺失的结构化步骤,并填补了语音处理和文本分割交叉领域的三个空白。首先,我们建立了TEDPara(人工标注的TED演讲)和YTSegPara(带有合成标签的YouTube视频)作为段落分割任务的首批基准。这些基准侧重于未被充分探索的语音领域,其中段落分割传统上不属于后处理的一部分,同时也为更广泛的文本分割领域做出了贡献,该领域仍然缺乏稳健和自然化的基准。其次,我们提出了一种约束解码公式,允许大型语言模型插入段落分隔符,同时保留原始转录,从而实现忠实的、句子对齐的评估。第三,我们表明,一个紧凑的模型(MiniSeg)实现了最先进的准确性,并且在分层扩展时,可以以最小的计算成本联合预测章节和段落。总之,我们的资源和方法将段落分割确立为语音处理中一个标准化的、实用的任务。
🔬 方法详解
问题定义:论文旨在解决自动语音转录文本缺乏结构化的问题,具体而言,就是如何自动地将语音转录文本分割成段落。现有方法要么依赖人工标注,成本高昂,要么效果不佳,难以满足实际应用需求。语音领域的段落分割一直没有得到足够的重视,缺乏标准化的基准数据集。
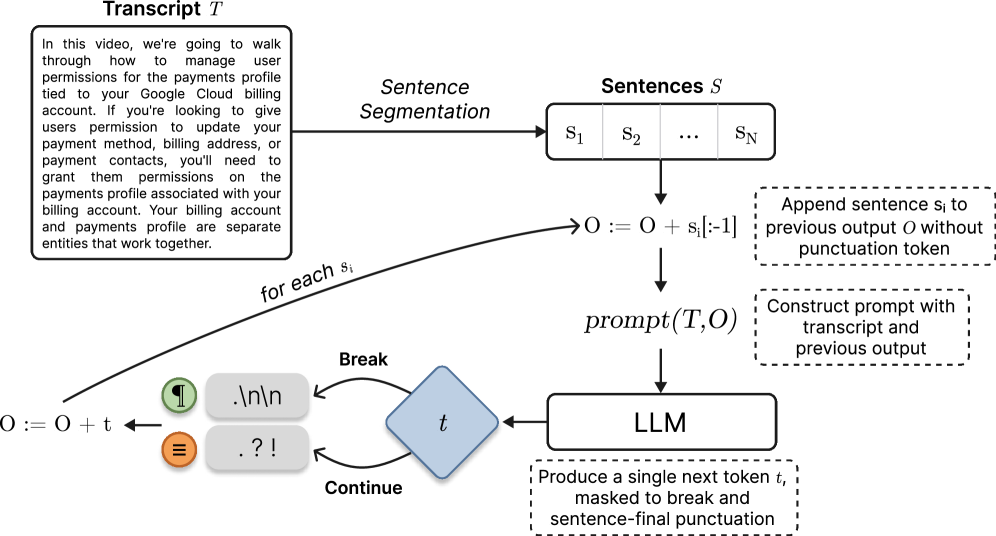
核心思路:论文的核心思路是将段落分割问题转化为一个序列标注问题,利用大型语言模型强大的文本理解能力,在保证原始转录文本内容不变的前提下,自动插入段落分隔符。通过约束解码,确保插入的分隔符与句子的边界对齐,从而保证分割的合理性。
技术框架:整体框架包括数据准备、模型训练和解码三个阶段。数据准备阶段构建了TEDPara和YTSegPara两个数据集。模型训练阶段,训练一个紧凑的模型MiniSeg,用于预测每个词是否应该插入段落分隔符。解码阶段,使用约束解码算法,利用大型语言模型生成最终的段落分割结果。该框架可以扩展为分层结构,同时预测章节和段落。
关键创新:论文的关键创新在于:1) 构建了首批针对语音转录文本段落分割的标准基准数据集TEDPara和YTSegPara;2) 提出了约束解码方法,保证了段落分割的忠实性和句子对齐;3) 设计了紧凑高效的MiniSeg模型,实现了最先进的性能。与现有方法相比,该方法无需人工干预,能够自动地对语音转录文本进行段落分割。
关键设计:约束解码的关键在于保证插入的段落分隔符与句子的边界对齐。具体实现方式是,在解码过程中,只允许在句子的结尾处插入分隔符。MiniSeg模型是一个基于Transformer的序列标注模型,输入是语音转录文本,输出是每个词是否应该插入分隔符的概率。损失函数采用交叉熵损失函数,优化目标是最小化预测概率与真实标签之间的差异。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MiniSeg模型在TEDPara和YTSegPara数据集上取得了最先进的性能。例如,在TEDPara数据集上,MiniSeg模型的F1值达到了显著高于现有基线模型的水平。此外,分层扩展的MiniSeg模型能够以极低的计算成本同时预测章节和段落,进一步提升了效率。
🎯 应用场景
该研究成果可广泛应用于语音转录文本的后处理,例如自动生成会议记录、字幕制作、语音搜索等领域。通过自动分割段落,可以显著提高文本的可读性和可理解性,方便用户快速浏览和检索信息。未来,该技术有望进一步应用于智能客服、语音助手等领域,提升人机交互的效率和用户体验。
📄 摘要(原文)
Automatic speech transcripts are often delivered as unstructured word streams that impede readability and repurposing. We recast paragraph segmentation as the missing structuring step and fill three gaps at the intersection of speech processing and text segmentation. First, we establish TEDPara (human-annotated TED talks) and YTSegPara (YouTube videos with synthetic labels) as the first benchmarks for the paragraph segmentation task. The benchmarks focus on the underexplored speech domain, where paragraph segmentation has traditionally not been part of post-processing, while also contributing to the wider text segmentation field, which still lacks robust and naturalistic benchmarks. Second, we propose a constrained-decoding formulation that lets large language models insert paragraph breaks while preserving the original transcript, enabling faithful, sentence-aligned evaluation. Third, we show that a compact model (MiniSeg) attains state-of-the-art accuracy and, when extended hierarchically, jointly predicts chapters and paragraphs with minimal computational cost. Together, our resources and methods establish paragraph segmentation as a standardized, practical task in speech processing.