Automated Analysis of Sustainability Reports: Using Large Language Models for the Extraction and Prediction of EU Taxonomy-Compliant KPIs
作者: Jonathan Schmoll, Adam Jatowt
分类: cs.CL
发布日期: 2025-12-30
💡 一句话要点
构建欧盟分类标准KPI数据集,评估大语言模型在可持续性报告分析中的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 可持续性报告 欧盟分类标准 关键绩效指标 自动化分析
📋 核心要点
- 欧盟分类标准的合规过程繁琐且耗费资源,现有方法难以满足需求,亟需自动化解决方案。
- 本文利用大型语言模型(LLM)进行可持续性报告的分析,旨在自动化提取经济活动和关键绩效指标(KPI)。
- 实验结果表明,LLM在定性任务中表现尚可,但在定量任务中表现不佳,提示需要进一步研究和优化。
📝 摘要(中文)
为了应对企业在欧盟分类标准合规方面面临的手动且资源密集型挑战,本文提出了一种利用大型语言模型(LLM)实现自动化的方法。由于缺乏公开的基准数据集,相关研究受到限制。为此,我们构建了一个新的结构化数据集,该数据集包含来自190份公司报告的真实经济活动和量化关键绩效指标(KPI)。我们使用该数据集对LLM在核心合规工作流程中进行了首次系统评估。结果表明,定性任务和定量任务之间存在明显的性能差距。LLM在识别经济活动的定性任务中表现出一定的成功,多步骤代理框架适度提高了精度。相反,这些模型在零样本设置下预测财务KPI的定量任务中彻底失败。我们还发现了一个悖论,即简洁的元数据通常比完整的非结构化报告产生更好的性能,并且发现模型置信度得分校准不佳。我们得出结论,虽然LLM尚未准备好实现完全自动化,但它们可以作为人类专家的强大辅助工具。我们的数据集为未来的研究提供了一个公共基准。
🔬 方法详解
问题定义:欧盟分类标准的合规性报告编制过程依赖于人工,耗时耗力。现有方法缺乏自动化工具,企业需要投入大量资源进行数据提取和分析。该论文旨在解决如何利用LLM自动从可持续性报告中提取符合欧盟分类标准的KPI,从而降低合规成本。
核心思路:论文的核心思路是利用LLM的自然语言处理能力,从非结构化的企业可持续性报告中提取结构化的经济活动和KPI数据。通过构建包含真实数据的基准数据集,系统地评估LLM在定性和定量任务中的表现,并识别LLM的优势和局限性。
技术框架:该研究的技术框架主要包括以下几个阶段:1)构建数据集:从190份公司报告中提取经济活动和KPI数据,构建结构化的基准数据集。2)定性任务:使用LLM识别报告中的经济活动,并采用多步骤代理框架提高精度。3)定量任务:使用LLM预测财务KPI,并在零样本设置下评估其性能。4)分析与评估:分析LLM在不同任务中的表现,并探讨元数据、模型置信度等因素对结果的影响。
关键创新:该研究的关键创新点在于:1)构建了一个公开的、结构化的欧盟分类标准KPI数据集,填补了该领域的空白。2)首次系统地评估了LLM在可持续性报告分析中的能力,揭示了LLM在定性和定量任务中的性能差异。3)发现简洁的元数据可能比完整的非结构化报告产生更好的性能,提出了值得进一步研究的悖论。
关键设计:在定性任务中,采用了多步骤代理框架,旨在通过分解任务来提高LLM的精度。在定量任务中,采用了零样本学习设置,以评估LLM在没有特定训练数据的情况下预测KPI的能力。论文还分析了模型置信度得分的校准情况,以评估模型预测结果的可靠性。具体的参数设置、损失函数、网络结构等技术细节在论文中未详细描述,属于LLM本身的设计。
🖼️ 关键图片
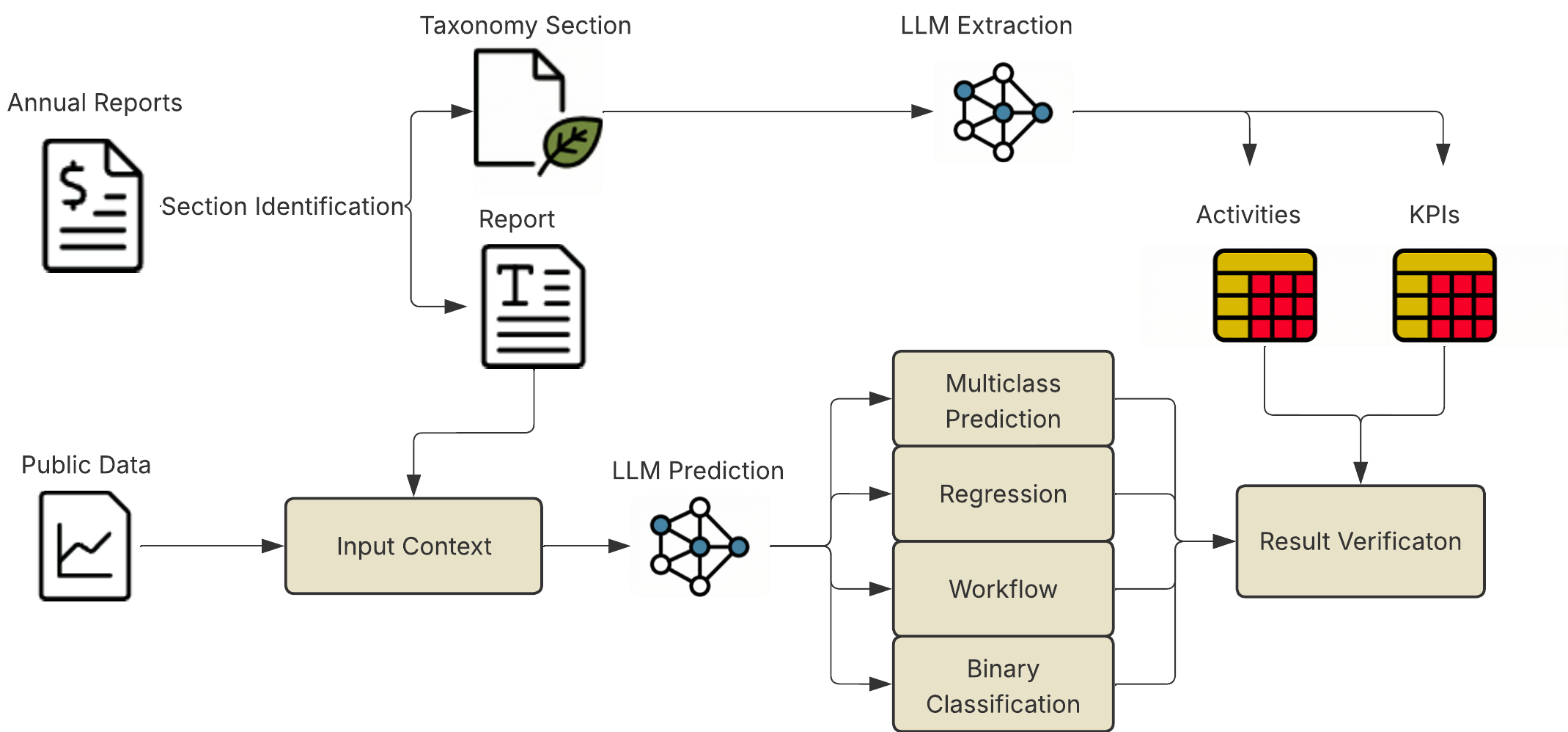


📊 实验亮点
实验结果表明,LLM在识别经济活动的定性任务中表现出一定的成功,但多步骤代理框架仅适度提高了精度。在预测财务KPI的定量任务中,LLM彻底失败。此外,研究发现简洁的元数据通常比完整的非结构化报告产生更好的性能。模型置信度得分校准不佳,表明模型预测结果的可靠性存在问题。
🎯 应用场景
该研究成果可应用于企业可持续性报告的自动分析、欧盟分类标准的合规性检查、ESG(环境、社会和治理)投资决策支持等领域。通过自动化数据提取和分析,可以降低企业合规成本,提高报告质量,并为投资者提供更准确的ESG信息。未来,该研究可以扩展到其他可持续性报告框架和标准。
📄 摘要(原文)
The manual, resource-intensive process of complying with the EU Taxonomy presents a significant challenge for companies. While Large Language Models (LLMs) offer a path to automation, research is hindered by a lack of public benchmark datasets. To address this gap, we introduce a novel, structured dataset from 190 corporate reports, containing ground-truth economic activities and quantitative Key Performance Indicators (KPIs). We use this dataset to conduct the first systematic evaluation of LLMs on the core compliance workflow. Our results reveal a clear performance gap between qualitative and quantitative tasks. LLMs show moderate success in the qualitative task of identifying economic activities, with a multi-step agentic framework modestly enhancing precision. Conversely, the models comprehensively fail at the quantitative task of predicting financial KPIs in a zero-shot setting. We also discover a paradox, where concise metadata often yields superior performance to full, unstructured reports, and find that model confidence scores are poorly calibrated. We conclude that while LLMs are not ready for full automation, they can serve as powerful assistive tools for human experts. Our dataset provides a public benchmark for future research.