Fantastic Reasoning Behaviors and Where to Find Them: Unsupervised Discovery of the Reasoning Process
作者: Zhenyu Zhang, Shujian Zhang, John Lambert, Wenxuan Zhou, Zhangyang Wang, Mingqing Chen, Andrew Hard, Rajiv Mathews, Lun Wang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-12-30
💡 一句话要点
提出RISE框架,无监督发现LLM推理过程中的行为向量并实现可控干预。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理过程 无监督学习 稀疏自编码器 行为向量 可解释性 可控干预
📋 核心要点
- 现有方法依赖人工定义的词级别概念分析LLM推理,难以捕捉所有潜在推理行为。
- 提出RISE框架,通过在思维链步骤激活上训练稀疏自编码器,无监督地发现推理行为向量。
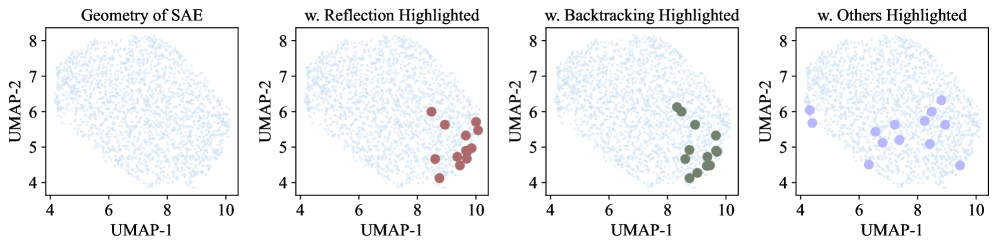
- 实验表明,RISE能发现可解释的推理行为,并能通过干预SAE向量来控制LLM的推理过程。
📝 摘要(中文)
尽管大型语言模型(LLMs)的推理能力日益增强,但其推理过程的内部机制仍未得到充分探索。以往的方法通常依赖于人工定义的词级别概念(例如,过度思考、反思)来以监督方式分析推理。然而,这些方法具有局限性,因为无法捕捉潜在推理行为的完整范围,其中许多行为难以在token空间中定义。本文提出了一个无监督框架(即RISE:通过稀疏自编码器进行推理行为可解释性),用于发现推理向量,我们将其定义为编码不同推理行为的激活空间中的方向。通过将思维链轨迹分割成句子级别的“步骤”并在步骤级别的激活上训练稀疏自编码器(SAE),我们发现了对应于可解释行为(如反思和回溯)的解耦特征。可视化和聚类分析表明,这些行为占据了解码器列空间中可分离的区域。此外,对SAE导出的向量进行有针对性的干预可以可控地放大或抑制特定的推理行为,从而在不重新训练的情况下改变推理轨迹。除了特定行为的解耦之外,SAE还捕获了诸如响应长度之类的结构属性,揭示了长推理轨迹与短推理轨迹的聚类。更有趣的是,SAE能够发现超出人类监督的新行为。我们展示了通过识别SAE解码器空间中与置信度相关的向量来控制响应置信度的能力。这些发现强调了无监督潜在发现对于解释和可控地引导LLM中的推理的潜力。
🔬 方法详解
问题定义:现有方法在分析大型语言模型(LLMs)的推理过程时,主要依赖于人工定义的词级别概念,例如“过度思考”、“反思”等。这种方法的局限性在于,它难以捕捉到所有潜在的推理行为,特别是那些难以在token空间中明确定义的行为。因此,如何更全面、更深入地理解LLMs的推理机制,成为了一个重要的研究问题。
核心思路:本文的核心思路是采用无监督学习的方法,自动发现LLMs在推理过程中表现出的各种行为模式。具体来说,通过训练稀疏自编码器(SAE)来学习LLMs在推理过程中的激活向量表示,从而发现隐藏在这些向量中的、与特定推理行为相关的方向。这种方法避免了对人工标注数据的依赖,能够更全面地探索LLMs的推理行为。
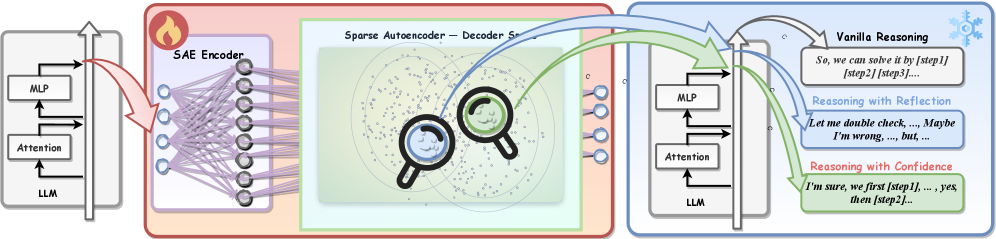
技术框架:RISE框架主要包含以下几个步骤:1) 将LLMs的思维链(Chain-of-Thought, CoT)推理轨迹分割成句子级别的“步骤”;2) 提取每个步骤对应的激活向量;3) 在这些激活向量上训练稀疏自编码器(SAE),学习到一组稀疏的特征表示;4) 分析SAE的解码器列空间,发现与特定推理行为相关的向量;5) 通过对这些向量进行干预,控制LLMs的推理过程。
关键创新:RISE框架的关键创新在于:1) 提出了使用无监督学习方法来发现LLMs推理行为的新思路,避免了对人工标注数据的依赖;2) 通过训练稀疏自编码器(SAE),学习到了一组可解释的特征表示,能够揭示LLMs推理过程中的隐藏行为;3) 实现了对LLMs推理过程的可控干预,可以通过调整SAE向量来放大或抑制特定的推理行为。
关键设计:在RISE框架中,稀疏自编码器(SAE)的设计至关重要。SAE的目标是学习到一组稀疏的特征表示,从而能够揭示LLMs推理过程中的隐藏行为。为了实现这一目标,SAE通常采用以下关键设计:1) 使用L1正则化来约束编码器的输出,鼓励其产生稀疏的激活;2) 选择合适的自编码器结构,例如,可以使用多层感知机(MLP)或卷积神经网络(CNN)作为编码器和解码器;3) 调整自编码器的超参数,例如,学习率、正则化系数等,以获得最佳的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RISE框架能够发现可解释的推理行为,例如反思和回溯。通过对SAE导出的向量进行干预,可以可控地放大或抑制特定的推理行为,从而在不重新训练的情况下改变推理轨迹。此外,RISE还能够发现超出人类监督的新行为,例如,通过识别SAE解码器空间中与置信度相关的向量来控制响应置信度。
🎯 应用场景
该研究成果可应用于提升LLM的可解释性和可控性,例如,可以用于诊断LLM推理过程中的错误,或者引导LLM生成特定类型的推理结果。此外,该方法还可以用于发现LLM中隐藏的偏见,并采取相应的措施进行纠正。未来,该研究有望推动LLM在安全、可靠和可信赖方向发展。
📄 摘要(原文)
Despite the growing reasoning capabilities of recent large language models (LLMs), their internal mechanisms during the reasoning process remain underexplored. Prior approaches often rely on human-defined concepts (e.g., overthinking, reflection) at the word level to analyze reasoning in a supervised manner. However, such methods are limited, as it is infeasible to capture the full spectrum of potential reasoning behaviors, many of which are difficult to define in token space. In this work, we propose an unsupervised framework (namely, RISE: Reasoning behavior Interpretability via Sparse auto-Encoder) for discovering reasoning vectors, which we define as directions in the activation space that encode distinct reasoning behaviors. By segmenting chain-of-thought traces into sentence-level 'steps' and training sparse auto-encoders (SAEs) on step-level activations, we uncover disentangled features corresponding to interpretable behaviors such as reflection and backtracking. Visualization and clustering analyses show that these behaviors occupy separable regions in the decoder column space. Moreover, targeted interventions on SAE-derived vectors can controllably amplify or suppress specific reasoning behaviors, altering inference trajectories without retraining. Beyond behavior-specific disentanglement, SAEs capture structural properties such as response length, revealing clusters of long versus short reasoning traces. More interestingly, SAEs enable the discovery of novel behaviors beyond human supervision. We demonstrate the ability to control response confidence by identifying confidence-related vectors in the SAE decoder space. These findings underscore the potential of unsupervised latent discovery for both interpreting and controllably steering reasoning in LLMs.