CEC-Zero: Zero-Supervision Character Error Correction with Self-Generated Rewards
作者: Zhiming Lin, Kai Zhao, Sophie Zhang, Peilai Yu, Canran Xiao
分类: cs.CL
发布日期: 2025-12-30
备注: AAAI'26 poster
💡 一句话要点
CEC-Zero:基于自生成奖励的零监督中文错别字纠正
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 中文拼写纠错 零监督学习 强化学习 大型语言模型 自生成奖励
📋 核心要点
- 现有中文拼写纠错方法依赖大量标注数据,且对新错误泛化能力不足,限制了实际应用。
- CEC-Zero利用强化学习,让LLM通过自我纠错学习,无需人工标注即可提升纠错能力。
- 实验表明,CEC-Zero在多个数据集上显著优于监督学习方法和微调LLM,提升了纠错性能。
📝 摘要(中文)
大规模中文拼写纠错(CSC)对于实际文本处理至关重要,但现有的LLM和监督方法缺乏对新错误的鲁棒性,并且依赖于昂贵的标注。我们引入了CEC-Zero,一个零监督强化学习框架,通过使LLM能够纠正自己的错误来解决这个问题。CEC-Zero从干净的文本中合成错误的输入,通过语义相似性和候选一致性计算聚类共识奖励,并使用PPO优化策略。在9个基准测试中,它优于监督基线10-13 F$_1$个点,优于强大的LLM微调5-8个点,并具有无偏奖励和收敛的理论保证。CEC-Zero为鲁棒、可扩展的CSC建立了一个无标签范例,释放了LLM在嘈杂文本管道中的潜力。
🔬 方法详解
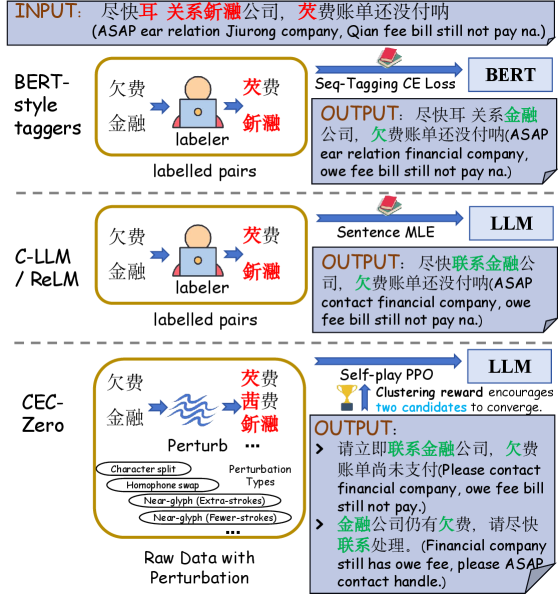
问题定义:论文旨在解决中文拼写纠错(CSC)问题,现有方法主要依赖于大规模标注数据,成本高昂且难以泛化到未见过的错误类型。此外,直接微调大型语言模型(LLM)进行CSC任务,虽然效果有所提升,但仍然需要标注数据,并且对于噪声文本的鲁棒性不足。
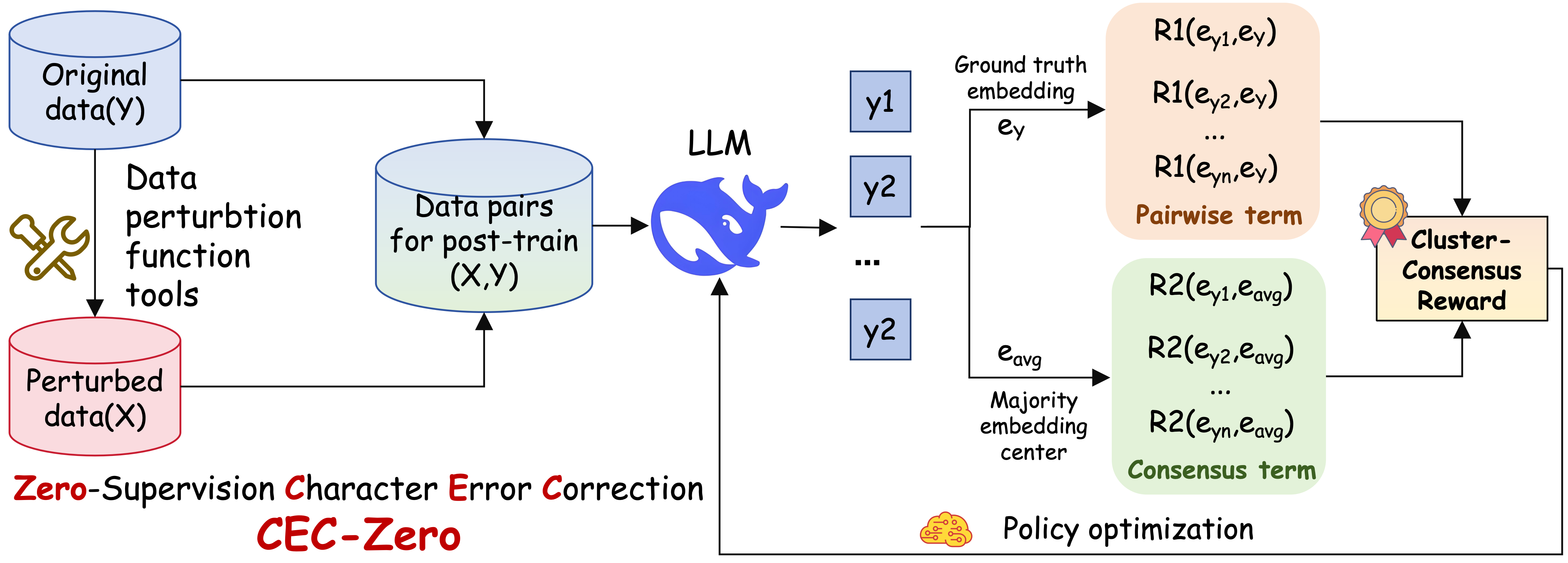
核心思路:CEC-Zero的核心思想是利用强化学习,让LLM在没有人工标注的情况下,通过与环境的交互学习如何纠正错误。具体来说,它通过生成错误样本、计算奖励信号和优化策略来实现。这种自监督的方式避免了对大量标注数据的依赖,并且能够更好地适应新的错误类型。
技术框架:CEC-Zero的整体框架包括以下几个主要模块:1) 错误生成模块:从干净文本中随机引入错误,生成带有噪声的输入样本。2) 策略网络:使用LLM作为策略网络,接收错误输入并输出纠正后的文本。3) 奖励计算模块:根据纠正后的文本计算奖励信号,奖励信号基于语义相似性和候选一致性。4) 策略优化模块:使用PPO算法优化策略网络,使其能够更好地纠正错误。
关键创新:CEC-Zero最重要的创新在于其零监督的学习范式。它不需要任何人工标注数据,而是通过自生成错误样本和自计算奖励信号来实现学习。这种方法不仅降低了标注成本,而且能够更好地适应新的错误类型,提高了模型的鲁棒性。此外,论文还提出了基于聚类共识的奖励计算方法,能够更准确地评估纠正结果的质量。
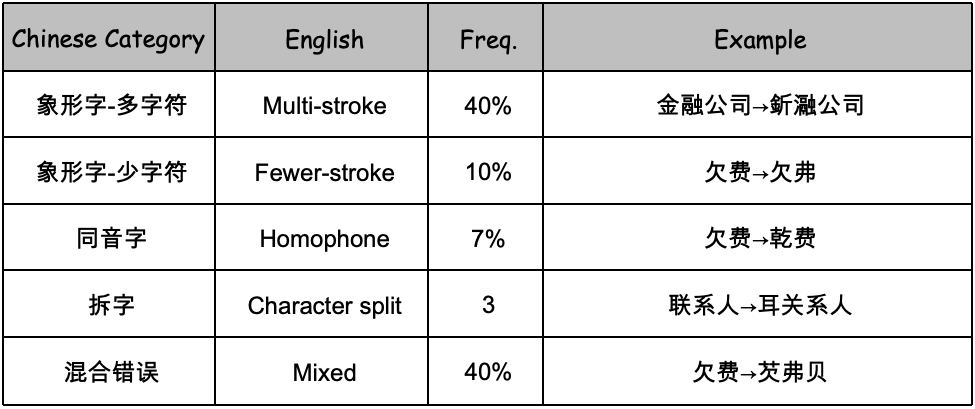
关键设计:在错误生成模块中,论文采用了随机插入、删除和替换字符的方法来模拟真实的错误类型。在奖励计算模块中,论文使用了预训练的语言模型计算语义相似度,并结合多个候选纠正结果的一致性来提高奖励信号的准确性。在策略优化模块中,论文使用了PPO算法,并对奖励函数进行了归一化处理,以提高训练的稳定性。
🖼️ 关键图片
📊 实验亮点
CEC-Zero在9个中文拼写纠错基准数据集上取得了显著的性能提升。相较于监督学习基线方法,CEC-Zero的F1值提升了10-13个百分点;与经过微调的强大LLM相比,CEC-Zero的F1值也提升了5-8个百分点。这些实验结果表明,CEC-Zero在零监督条件下能够有效地学习到中文拼写纠错能力,并超越了传统的监督学习方法。
🎯 应用场景
CEC-Zero可广泛应用于各种中文文本处理场景,如搜索引擎、社交媒体、在线教育等,提高文本质量和用户体验。该方法无需标注数据,降低了应用成本,尤其适用于处理海量噪声文本。未来,该研究可扩展到其他语言和文本处理任务,推动自然语言处理技术的发展。
📄 摘要(原文)
Large-scale Chinese spelling correction (CSC) remains critical for real-world text processing, yet existing LLMs and supervised methods lack robustness to novel errors and rely on costly annotations. We introduce CEC-Zero, a zero-supervision reinforcement learning framework that addresses this by enabling LLMs to correct their own mistakes. CEC-Zero synthesizes errorful inputs from clean text, computes cluster-consensus rewards via semantic similarity and candidate agreement, and optimizes the policy with PPO. It outperforms supervised baselines by 10--13 F$_1$ points and strong LLM fine-tunes by 5--8 points across 9 benchmarks, with theoretical guarantees of unbiased rewards and convergence. CEC-Zero establishes a label-free paradigm for robust, scalable CSC, unlocking LLM potential in noisy text pipelines.