Efficient Context Scaling with LongCat ZigZag Attention
作者: Chen Zhang, Yang Bai, Jiahuan Li, Anchun Gui, Keheng Wang, Feifan Liu, Guanyu Wu, Yuwei Jiang, Defei Bu, Li Wei, Haihang Jing, Hongyin Tang, Xin Chen, Xiangzhou Huang, Fengcun Li, Rongxiang Weng, Yulei Qian, Yifan Lu, Yerui Sun, Jingang Wang, Yuchen Xie, Xunliang Cai
分类: cs.CL, cs.AI
发布日期: 2025-12-30 (更新: 2026-01-06)
备注: 10 pages, 3 figures, 3 tables
💡 一句话要点
提出LongCat ZigZag Attention,加速长文本处理,提升长程推理与Agent能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏注意力 长文本处理 Transformer 长程推理 Agent 计算效率 ZigZag注意力
📋 核心要点
- 现有全注意力模型在长文本处理中计算成本高昂,限制了其在资源受限场景下的应用。
- LoZA通过稀疏注意力模式,在不显著增加计算负担的前提下,提升模型处理长文本的能力。
- 实验表明,LoZA能够加速长文本处理,并提升模型在长程推理和Agent任务中的性能。
📝 摘要(中文)
本文提出了一种名为LongCat ZigZag Attention (LoZA) 的稀疏注意力机制,旨在将现有的全注意力模型转化为计算预算有限的稀疏版本。在长文本场景下,LoZA 能够显著加速预填充密集型(例如,检索增强生成)和解码密集型(例如,工具集成推理)任务。具体而言,通过在中期训练阶段将 LoZA 应用于 LongCat-Flash,我们得到了 LongCat-Flash-Exp,一个可以快速处理高达 100 万 tokens 的长文本基础模型,从而实现高效的长期推理和长程 Agent 能力。
🔬 方法详解
问题定义:现有Transformer模型中的全注意力机制在处理长文本时,计算复杂度呈平方增长,导致计算资源消耗巨大,难以应用于实际场景,尤其是在需要快速响应的检索增强生成和工具集成推理等任务中。因此,如何降低长文本处理的计算成本,同时保持模型的性能,是一个重要的挑战。
核心思路:LoZA的核心思路是通过引入一种新的稀疏注意力模式,即ZigZag注意力,来减少需要计算的注意力权重数量。这种模式旨在在降低计算复杂度的同时,尽可能保留重要的上下文信息,从而在计算效率和模型性能之间取得平衡。
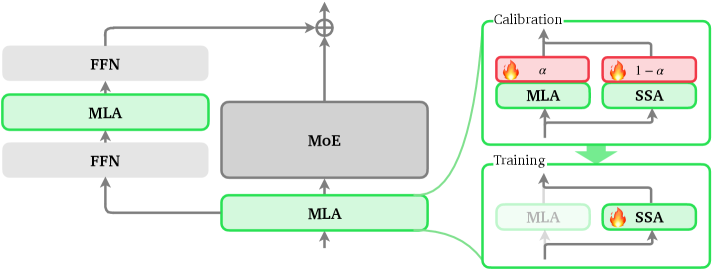
技术框架:LoZA可以作为一个模块嵌入到现有的Transformer模型中,替换原有的全注意力层。具体来说,LoZA首先将输入序列分割成若干个块,然后在每个块内部进行全注意力计算,块与块之间采用ZigZag模式进行连接,即每个块只与相邻的几个块进行注意力交互。这种局部全注意力和全局稀疏注意力的结合,使得模型能够有效地处理长文本,同时降低计算复杂度。
关键创新:LoZA的关键创新在于其ZigZag注意力模式。与传统的全局稀疏注意力模式相比,ZigZag模式能够更好地捕捉长距离依赖关系,同时避免了全局注意力带来的高计算成本。此外,LoZA的设计具有通用性,可以应用于各种不同的Transformer模型,而无需进行大量的修改。
关键设计:LoZA的关键设计包括块的大小、ZigZag连接的稀疏度等参数。这些参数需要根据具体的任务和数据集进行调整,以达到最佳的性能。此外,LoZA还可以与其他稀疏注意力技术相结合,进一步提高计算效率。论文中,LoZA被应用于LongCat-Flash模型,并通过中期训练得到LongCat-Flash-Exp模型。
🖼️ 关键图片
📊 实验亮点
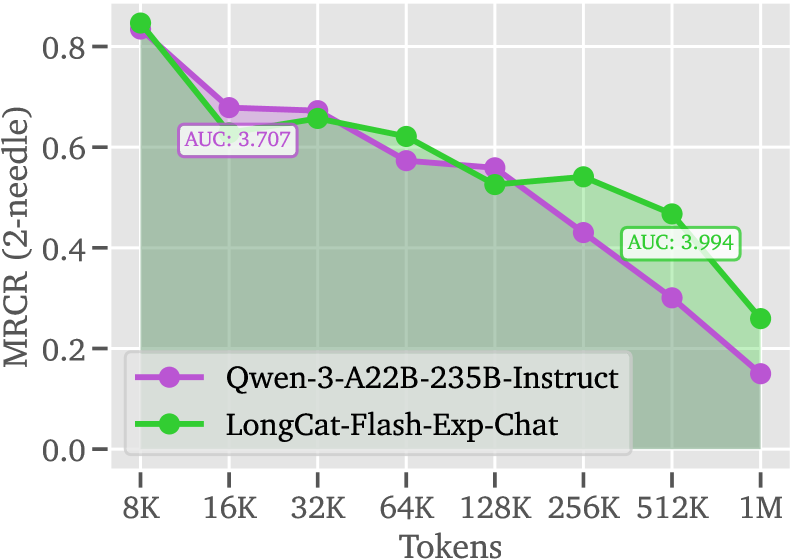
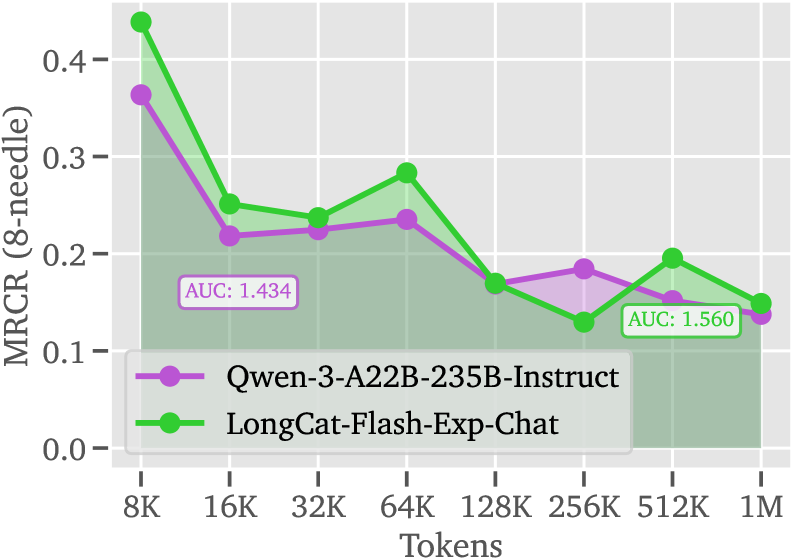
LoZA通过应用于LongCat-Flash模型,成功训练出LongCat-Flash-Exp,该模型能够处理高达100万tokens的长文本。实验结果表明,LoZA在长文本处理任务中能够显著加速计算过程,同时保持甚至提升模型性能,尤其是在长程推理和Agent任务中表现突出。具体性能数据和对比基线信息在论文中详细给出。
🎯 应用场景
LoZA具有广泛的应用前景,包括但不限于:长文本摘要、机器翻译、问答系统、代码生成、对话系统、以及需要长期记忆和推理的Agent任务。通过降低长文本处理的计算成本,LoZA使得这些应用能够更好地部署在资源受限的设备上,并能够处理更长的上下文信息,从而提高性能和用户体验。
📄 摘要(原文)
We introduce LongCat ZigZag Attention (LoZA), which is a sparse attention scheme designed to transform any existing full-attention models into sparse versions with rather limited compute budget. In long-context scenarios, LoZA can achieve significant speed-ups both for prefill-intensive (e.g., retrieval-augmented generation) and decode-intensive (e.g., tool-integrated reasoning) cases. Specifically, by applying LoZA to LongCat-Flash during mid-training, we serve LongCat-Flash-Exp as a long-context foundation model that can swiftly process up to 1 million tokens, enabling efficient long-term reasoning and long-horizon agentic capabilities.