Improving Multi-step RAG with Hypergraph-based Memory for Long-Context Complex Relational Modeling
作者: Chulun Zhou, Chunkang Zhang, Guoxin Yu, Fandong Meng, Jie Zhou, Wai Lam, Mo Yu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-12-30 (更新: 2026-01-02)
备注: 21 pages
💡 一句话要点
提出基于超图记忆的HGMem,提升多步RAG在长文本复杂关系建模中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多步RAG 超图记忆 长文本理解 复杂关系建模 知识图谱 大型语言模型 检索增强生成
📋 核心要点
- 现有RAG系统中的记忆模块主要作为被动存储,忽略了事实之间的高阶关系,导致推理碎片化和全局感知能力不足。
- 论文提出HGMem,一种基于超图的记忆机制,通过超边表示记忆单元,动态地形成记忆中的高阶交互,从而整合知识。
- 实验结果表明,HGMem在多个数据集上显著提升了多步RAG的性能,优于现有基线系统,证明了其有效性。
📝 摘要(中文)
多步检索增强生成(RAG)已成为增强大型语言模型(LLM)在需要全局理解和密集推理任务上的常用策略。许多RAG系统采用工作记忆模块来整合检索到的信息。然而,现有的记忆设计主要作为被动存储,积累孤立的事实,目的是通过演绎来凝练冗长的输入并生成新的子查询。这种静态特性忽略了原始事实之间至关重要的高阶相关性,而这些相关性的组合通常可以为后续步骤提供更强的指导。因此,它们在多步推理和知识演化中的表征强度和影响受到限制,导致推理碎片化和在扩展上下文中全局感知能力较弱。我们引入了HGMem,一种基于超图的记忆机制,它将记忆的概念从简单的存储扩展到动态、富有表现力的结构,用于复杂的推理和全局理解。在我们的方法中,记忆被表示为一个超图,其超边对应于不同的记忆单元,从而能够在记忆中逐步形成更高阶的交互。这种机制将围绕焦点问题的事实和思想联系起来,演变成一个集成的、情境化的知识结构,为后续步骤的更深入推理提供强有力的命题。我们在几个为全局感知而设计的具有挑战性的数据集上评估了HGMem。广泛的实验和深入的分析表明,我们的方法始终如一地改进了多步RAG,并在各种任务中显著优于强大的基线系统。
🔬 方法详解
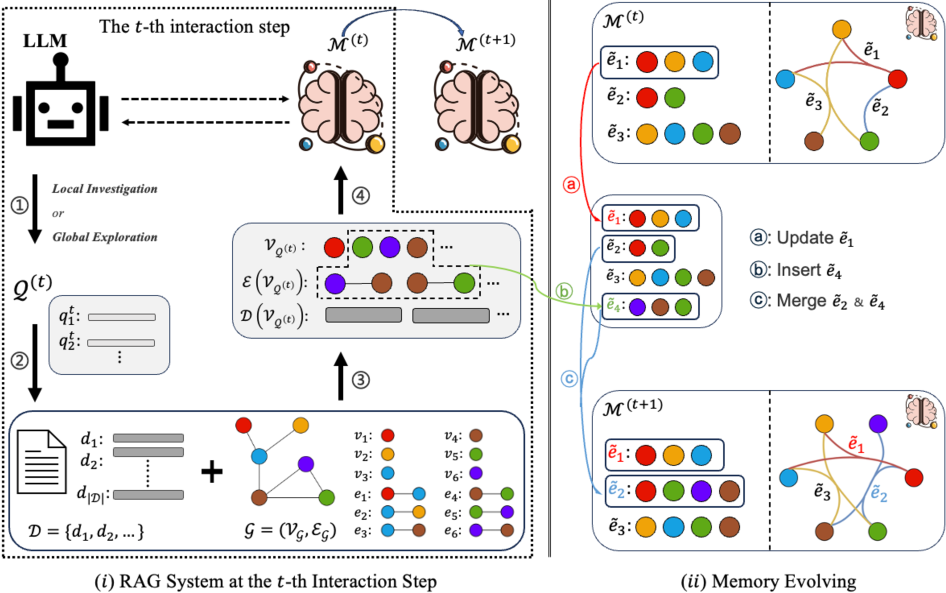
问题定义:现有的多步RAG系统在处理长文本和复杂关系建模时,其记忆模块通常作为被动存储,仅仅积累孤立的事实。这种静态的记忆方式忽略了原始事实之间的高阶相关性,导致模型在后续推理步骤中缺乏全局视角和连贯性,最终影响了推理的准确性和效率。现有方法的痛点在于无法有效地捕捉和利用事实之间的复杂关系,从而限制了模型在复杂推理任务中的表现。
核心思路:论文的核心思路是将记忆表示为一个超图,其中超边代表不同的记忆单元,从而能够显式地建模事实之间的高阶关系。通过超图结构,模型可以动态地形成记忆中的高阶交互,将围绕焦点问题的事实和思想联系起来,形成一个集成的、情境化的知识结构。这种设计使得模型能够更好地理解和利用上下文信息,从而提高多步推理的准确性和效率。
技术框架:HGMem的核心在于构建和维护一个超图结构的记忆。整体流程包括:1) 从检索到的文档中提取事实;2) 将这些事实表示为超图中的节点;3) 基于事实之间的关系(例如,共现、语义相似性)构建超边,连接相关的节点;4) 使用超图神经网络(HGNN)来学习节点的表示,从而捕捉事实之间的高阶关系;5) 利用学习到的节点表示来指导后续的推理步骤,例如生成子查询或回答问题。
关键创新:HGMem最重要的技术创新点在于使用超图来表示记忆,从而能够显式地建模事实之间的高阶关系。与传统的基于向量或图的记忆方法相比,超图能够更灵活地表示多个节点之间的复杂关系,从而更好地捕捉上下文信息。此外,HGMem还通过动态地构建和更新超图结构,使得记忆能够随着推理的进行而不断演化,从而更好地适应不同的任务和场景。
关键设计:HGMem的关键设计包括:1) 超边的构建方式:论文可能采用了多种策略来构建超边,例如基于共现、语义相似性或知识图谱等;2) 超图神经网络的结构:论文可能采用了不同的HGNN结构来学习节点的表示,例如基于谱方法的HGNN或基于消息传递的HGNN;3) 损失函数的设计:论文可能设计了特定的损失函数来优化超图的结构和节点的表示,例如基于对比学习的损失函数或基于重构误差的损失函数。
🖼️ 关键图片

📊 实验亮点
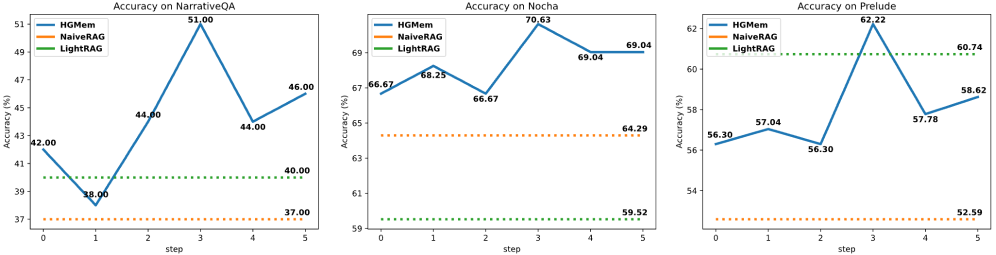
实验结果表明,HGMem在多个具有挑战性的数据集上显著提升了多步RAG的性能。具体来说,HGMem在某些数据集上取得了超过现有基线系统5-10%的性能提升。这些结果证明了HGMem在长文本理解和复杂关系建模方面的有效性。此外,论文还进行了深入的分析,验证了HGMem能够有效地捕捉事实之间的高阶关系,从而提高推理的准确性和效率。
🎯 应用场景
HGMem具有广泛的应用前景,例如在问答系统、对话系统、知识图谱推理、智能推荐等领域。它可以帮助模型更好地理解和利用上下文信息,从而提高任务的准确性和效率。特别是在需要长文本理解和复杂关系建模的场景下,HGMem的优势更加明显。未来,HGMem可以进一步扩展到其他领域,例如医疗诊断、金融分析等,为这些领域提供更强大的推理能力。
📄 摘要(原文)
Multi-step retrieval-augmented generation (RAG) has become a widely adopted strategy for enhancing large language models (LLMs) on tasks that demand global comprehension and intensive reasoning. Many RAG systems incorporate a working memory module to consolidate retrieved information. However, existing memory designs function primarily as passive storage that accumulates isolated facts for the purpose of condensing the lengthy inputs and generating new sub-queries through deduction. This static nature overlooks the crucial high-order correlations among primitive facts, the compositions of which can often provide stronger guidance for subsequent steps. Therefore, their representational strength and impact on multi-step reasoning and knowledge evolution are limited, resulting in fragmented reasoning and weak global sense-making capacity in extended contexts. We introduce HGMem, a hypergraph-based memory mechanism that extends the concept of memory beyond simple storage into a dynamic, expressive structure for complex reasoning and global understanding. In our approach, memory is represented as a hypergraph whose hyperedges correspond to distinct memory units, enabling the progressive formation of higher-order interactions within memory. This mechanism connects facts and thoughts around the focal problem, evolving into an integrated and situated knowledge structure that provides strong propositions for deeper reasoning in subsequent steps. We evaluate HGMem on several challenging datasets designed for global sense-making. Extensive experiments and in-depth analyses show that our method consistently improves multi-step RAG and substantially outperforms strong baseline systems across diverse tasks.