An Empirical Analysis of Fine-Tuning Large Language Models on Bioinformatics Literature: PRSGPT and BioStarsGPT
作者: Muhammad Muneeb, David B. Ascher
分类: cs.CL
发布日期: 2025-12-29
💡 一句话要点
提出生物信息学领域LLM微调流程,构建PRSGPT和BioStarsGPT。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 生物信息学 微调 问答系统 参数高效微调
📋 核心要点
- 现有LLM在生物信息学领域缺乏专业知识,难以直接应用于复杂任务。
- 提出一个九步流水线,利用提示工程、NLI、语义去重等技术,高效生成高质量的生物信息学QA数据集。
- 实验表明,Qwen2.5-7B在PRSGPT和BioStarsGPT任务上表现出色,显著提升了BLEU和ROUGE指标。
📝 摘要(中文)
大型语言模型(LLM)通常缺乏复杂生物信息学应用的专业知识。本文提出了一个可复现的流水线,用于在专门的生物信息学数据上微调LLM,并通过两个用例展示:PRSGPT,专注于多基因风险评分(PRS)工具;BioStarsGPT,在社区论坛讨论上训练。该九步流水线集成了多样的数据源,结构化预处理,基于提示的问答(QA)生成(通过Google Gemini),自然语言推理(NLI)用于质量控制,语义去重,基于聚类的数据分割,以及使用LoRA的参数高效微调。我们微调了三个LLM(LLaMA-3.2-3B,Qwen2.5-7B,Gemma),并在超过14个词汇和语义指标上进行了基准测试。Qwen2.5-7B表现最佳,PRSGPT的BLEU-4和ROUGE-1分别提高了82%和70%,BioStarsGPT的BLEU-4和ROUGE-1分别提高了6%和18%。开源数据集包括PRSGPT的超过28,000个QA对和BioStarsGPT的154,282个QA对。对PRSGPT的人工评估在PRS工具比较任务中产生了61.9%的准确率,与Google Gemini(61.4%)相当,但具有更丰富的方法论细节和准确的引用。BioStarsGPT在142个精选的生物信息学问题中表现出59%的概念准确性。我们的流水线实现了LLM的可扩展、特定领域的微调。它支持保护隐私、本地部署的生物信息学助手,探索它们的实际应用,并解决与其开发和使用相关的挑战、局限性和缓解策略。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在生物信息学领域应用时,由于缺乏特定领域的知识,无法有效解决该领域的复杂问题。例如,在多基因风险评分(PRS)工具比较和生物信息学概念理解方面,通用LLM的表现往往不尽如人意。因此,需要针对生物信息学文献对LLM进行微调,以提升其在该领域的专业能力。
核心思路:本文的核心思路是构建一个可复现的流水线,用于在专门的生物信息学数据上微调LLM。该流水线通过整合多样的数据源、结构化预处理、提示工程生成高质量的问答对、自然语言推理(NLI)进行质量控制、语义去重、基于聚类的数据分割以及参数高效微调等步骤,从而实现LLM在生物信息学领域的知识迁移和能力提升。
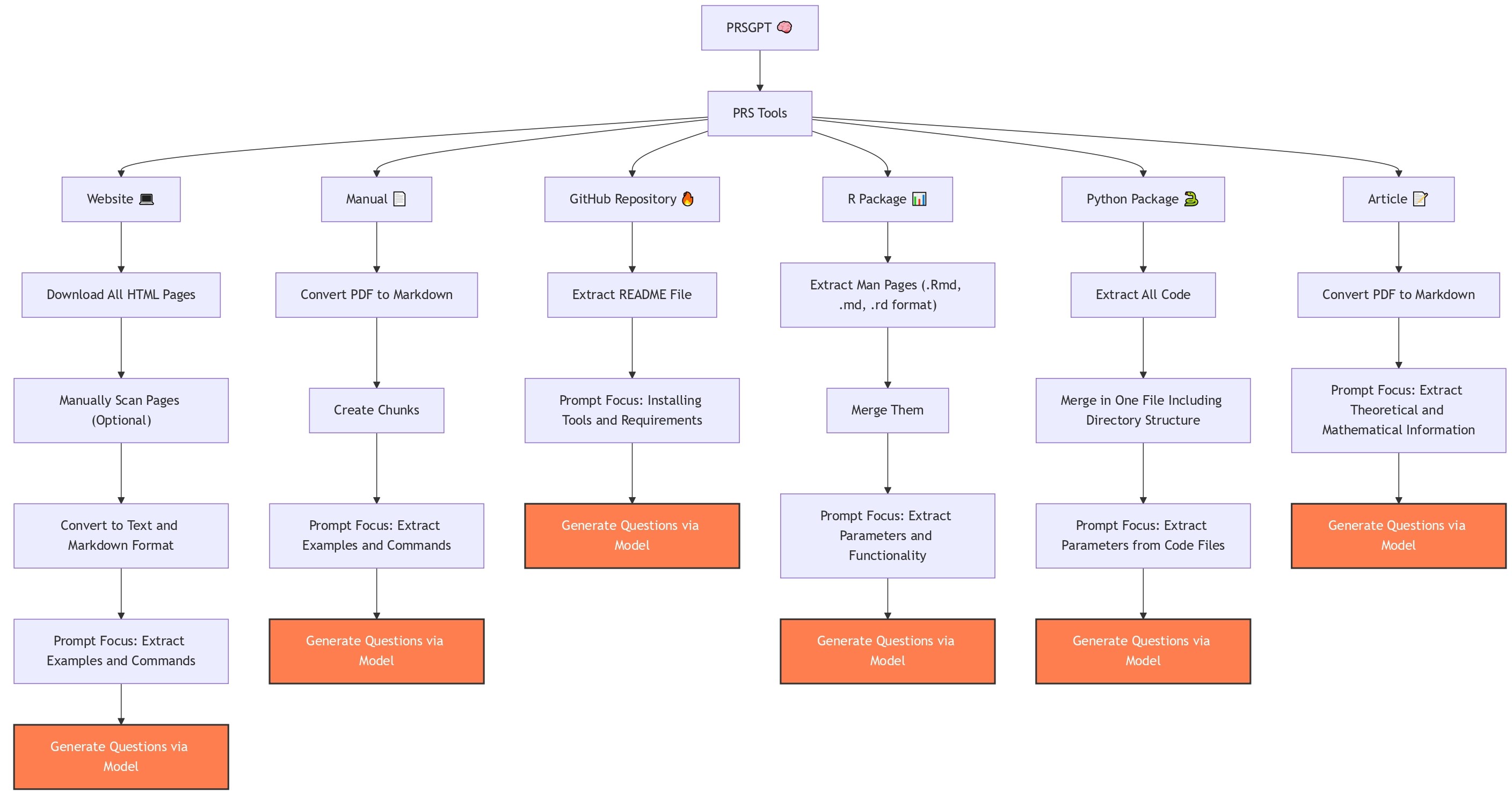
技术框架:该流水线包含九个主要步骤:1) 数据收集,整合来自不同来源的生物信息学数据;2) 结构化预处理,对数据进行清洗和格式化;3) 基于提示的问答(QA)生成,利用Google Gemini等模型生成问答对;4) 自然语言推理(NLI),对生成的问答对进行质量控制;5) 语义去重,去除重复的问答对;6) 基于聚类的数据分割,将数据分割成训练集和验证集;7) 参数高效微调,使用LoRA等技术对LLM进行微调;8) 基准测试,在多个指标上评估微调后的模型性能;9) 人工评估,对模型的生成结果进行人工评估。
关键创新:该方法的主要创新点在于构建了一个完整的、可复现的生物信息学领域LLM微调流水线。该流水线集成了多种数据处理和模型微调技术,能够高效地生成高质量的生物信息学QA数据集,并利用这些数据集对LLM进行微调,从而显著提升LLM在该领域的专业能力。与现有方法相比,该方法更加系统化和自动化,能够更好地适应不同生物信息学任务的需求。
关键设计:在参数高效微调方面,论文采用了LoRA(Low-Rank Adaptation)技术,通过引入低秩矩阵来更新LLM的权重,从而减少了需要训练的参数数量,降低了计算成本。在数据分割方面,采用了基于聚类的策略,确保训练集和验证集的数据分布相似,从而提高了模型的泛化能力。此外,论文还详细描述了提示工程的设计,包括如何选择合适的提示词和如何生成高质量的问答对。
🖼️ 关键图片


📊 实验亮点
Qwen2.5-7B在PRSGPT任务中,BLEU-4和ROUGE-1指标分别提升了82%和70%;在BioStarsGPT任务中,BLEU-4和ROUGE-1指标分别提升了6%和18%。PRSGPT在PRS工具比较任务中达到61.9%的准确率,与Google Gemini (61.4%) 相当,但提供了更丰富的方法论细节和准确的引用。BioStarsGPT在生物信息学问题解答中达到59%的概念准确性。
🎯 应用场景
该研究成果可应用于构建隐私保护、本地部署的生物信息学助手,为研究人员提供便捷的知识检索和问题解答服务。例如,可以帮助研究人员快速比较不同的PRS工具,理解复杂的生物信息学概念,从而加速科研进程。此外,该方法还可推广到其他专业领域,为构建领域知识增强的LLM提供借鉴。
📄 摘要(原文)
Large language models (LLMs) often lack specialized knowledge for complex bioinformatics applications. We present a reproducible pipeline for fine-tuning LLMs on specialized bioinformatics data, demonstrated through two use cases: PRSGPT, focused on polygenic risk score (PRS) tools, and BioStarsGPT, trained on community forum discussions. The nine-step pipeline integrates diverse data sources, structured preprocessing, prompt-based question-answer (QA) generation (via Google Gemini), natural language inference (NLI) for quality control, semantic deduplication, clustering-based data splitting, and parameter-efficient fine-tuning using LoRA. We fine-tuned three LLMs (LLaMA-3.2-3B, Qwen2.5-7B, Gemma) and benchmarked them on over 14 lexical and semantic metrics. Qwen2.5-7B emerged as the best performer, with BLEU-4 and ROUGE-1 improvements of 82\% and 70\% for PRSGPT and 6\% and 18\% for BioStarsGPT, respectively. The open-source datasets produced include over 28,000 QA pairs for PRSGPT and 154,282 for BioStarsGPT. Human evaluation of PRSGPT yielded 61.9\% accuracy on the PRS tools comparison task, comparable to Google Gemini (61.4\%), but with richer methodological detail and accurate citations. BioStarsGPT demonstrated 59\% conceptual accuracy across 142 curated bioinformatics questions. Our pipeline enables scalable, domain-specific fine-tuning of LLMs. It enables privacy-preserving, locally deployable bioinformatics assistants, explores their practical applications, and addresses the challenges, limitations, and mitigation strategies associated with their development and use.