Interpretable Safety Alignment via SAE-Constructed Low-Rank Subspace Adaptation
作者: Dianyun Wang, Qingsen Ma, Yuhu Shang, Zhifeng Lu, Zhenbo Xu, Lechen Ning, Huijia Wu, Zhaofeng He
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-12-29 (更新: 2026-01-05)
💡 一句话要点
提出SAILS,利用SAE构建低秩子空间自适应,实现大语言模型安全对齐。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 安全对齐 低秩自适应 稀疏自编码器 语义解耦 可解释性 大语言模型 参数高效微调
📋 核心要点
- 现有安全对齐方法(如LoRA)由于语义纠缠,难以有效识别安全相关的低秩子空间。
- SAILS利用稀疏自编码器(SAEs)解耦语义,构建可解释的安全子空间,并用于初始化LoRA适配器。
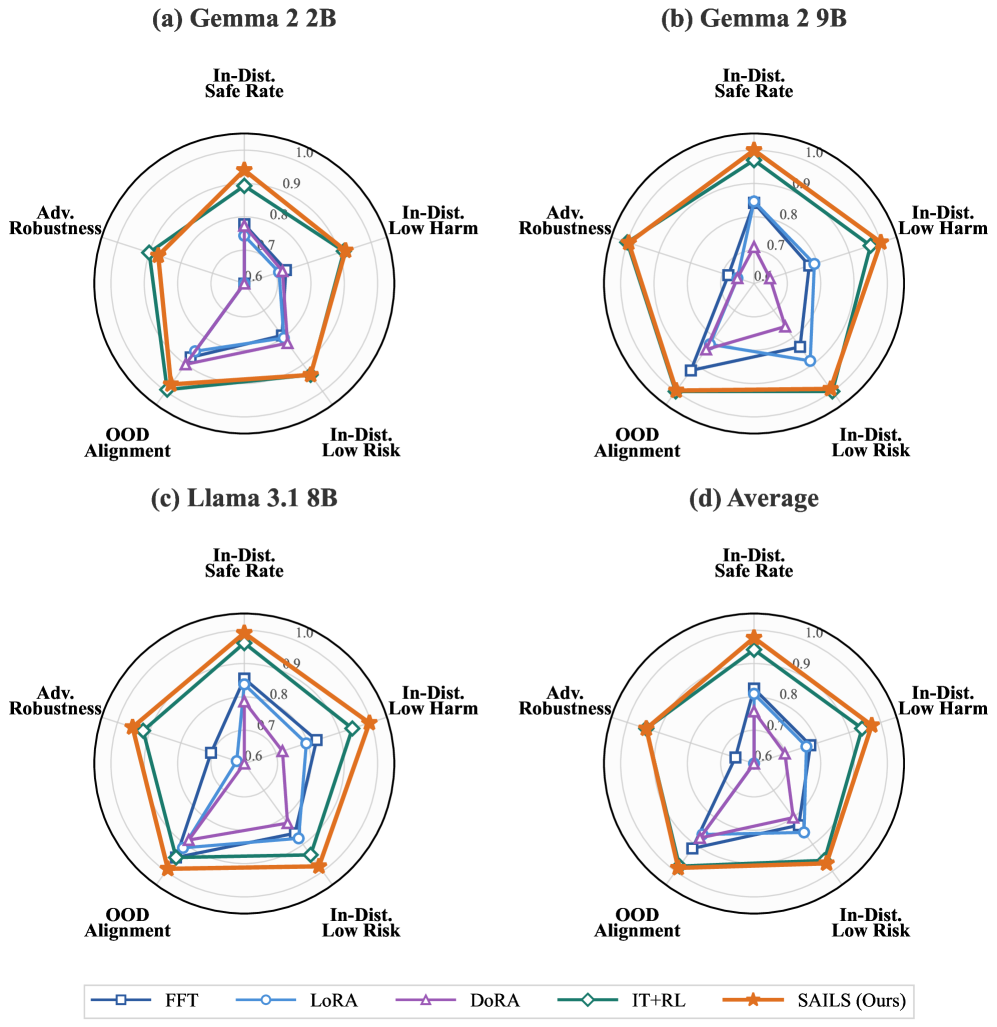
- SAILS在Gemma-2-9B上达到99.6%的安全率,超越全量微调,同时仅更新少量参数并提供可解释性。
📝 摘要(中文)
安全对齐对于负责任地部署大型语言模型(LLMs)至关重要,它旨在训练LLMs拒绝有害请求,同时保持其有用性。先前研究表明,安全行为受低秩结构控制,这暗示参数高效微调(PEFT)非常适合对齐。然而,低秩自适应(LoRA)在安全基准测试中始终不如全量微调和强化学习。我们将此差距归因于语义纠缠:由于多义性,安全相关的方向与不相关的概念交织在一起,阻碍了隐式子空间的识别。为了解决这个问题,我们提出了SAILS(通过可解释的低秩子空间实现安全对齐),它利用稀疏自编码器(SAEs)将表示解耦为单义特征,从SAE解码器方向构建可解释的安全子空间,并使用它来初始化LoRA适配器。从理论上讲,我们证明了基于SAE的识别在单义性假设下实现了任意小的恢复误差,而直接识别则存在不可约的误差下限。在实验上,SAILS在Gemma-2-9B上实现了高达99.6%的安全率,超过了全量微调7.4个百分点,并与基于RLHF的模型相匹配,同时仅更新0.19%的参数并提供可解释性。
🔬 方法详解
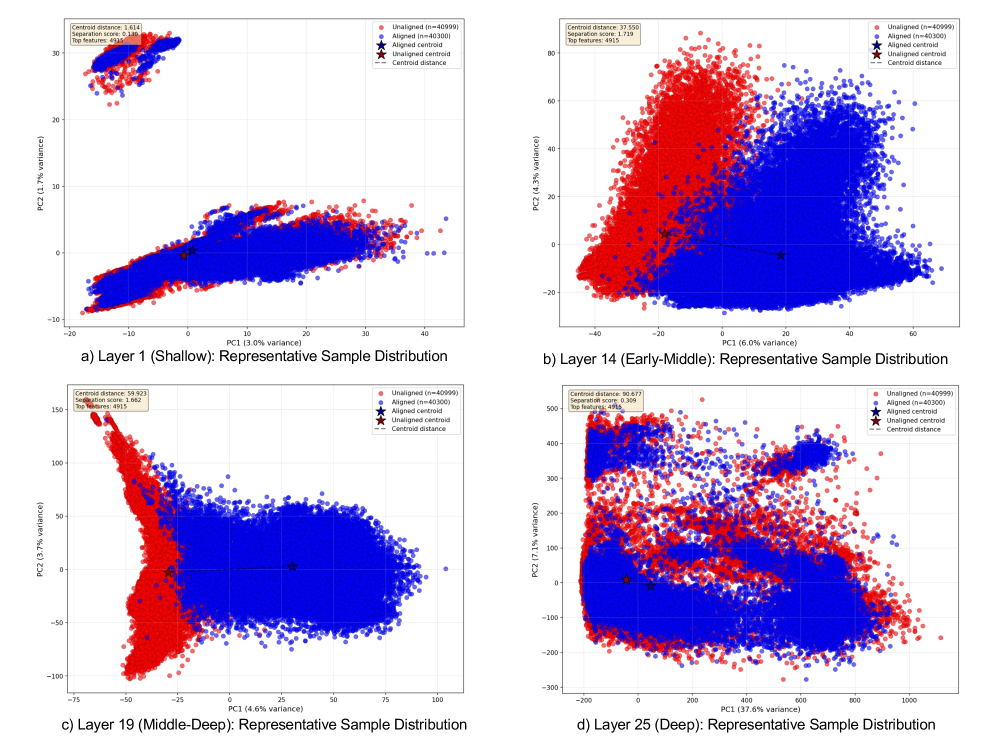
问题定义:现有的大语言模型安全对齐方法,特别是基于低秩自适应(LoRA)的方法,在安全基准测试中表现不佳,无法达到全量微调或强化学习的效果。主要原因是模型中存在语义纠缠,即安全相关的方向与不相关的概念混合在一起,使得LoRA难以有效地识别和调整安全相关的低秩子空间。这种语义纠缠阻碍了模型学习区分安全和不安全请求的能力。
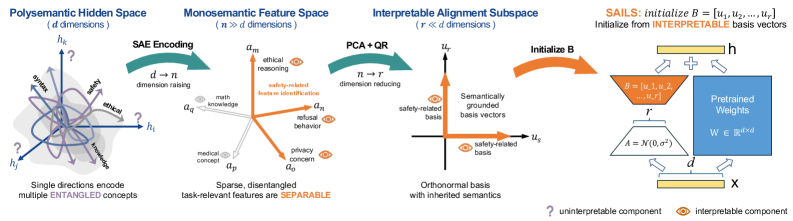
核心思路:SAILS的核心思路是利用稀疏自编码器(SAEs)来解耦模型的内部表示,将多义特征分解为单义特征。通过SAE,可以将模型内部复杂的表示分解为多个独立的、具有明确语义含义的特征。然后,基于这些单义特征,构建一个可解释的安全子空间,该子空间能够更准确地捕捉安全相关的方向。最后,使用这个安全子空间来初始化LoRA适配器,从而实现更有效的安全对齐。
技术框架:SAILS的整体框架包括以下几个主要阶段: 1. 稀疏自编码器训练:使用SAEs对预训练语言模型的中间层表示进行训练,学习将原始表示分解为稀疏的、单义的特征。 2. 安全子空间构建:基于训练好的SAE解码器方向,构建一个可解释的安全子空间。具体方法是选择与安全相关的SAE解码器方向,并将它们组合成一个低秩子空间。 3. LoRA适配器初始化:使用构建好的安全子空间来初始化LoRA适配器的权重。这样,LoRA适配器就能够专注于调整安全相关的参数,从而实现更有效的安全对齐。 4. 微调:使用安全对齐数据集对初始化后的LoRA适配器进行微调,进一步优化模型的安全性能。
关键创新:SAILS最重要的技术创新点在于利用SAEs来解耦语义,从而构建可解释的安全子空间。与直接使用LoRA进行微调相比,SAILS能够更准确地识别和调整安全相关的参数,避免了语义纠缠带来的干扰。此外,SAILS还提供了一种可解释的方法来理解模型如何进行安全决策,这对于提高模型的可信度和可靠性至关重要。
关键设计:SAILS的关键设计包括: 1. SAE结构:SAE采用标准的编码器-解码器结构,并引入稀疏性约束,鼓励模型学习稀疏的、单义的特征。 2. 安全子空间选择:通过分析SAE解码器方向与安全相关的程度,选择与安全最相关的解码器方向来构建安全子空间。具体方法可以使用人工标注或自动方法。 3. LoRA初始化:使用安全子空间的基向量来初始化LoRA适配器的权重矩阵。这样,LoRA适配器就能够专注于调整安全相关的参数。
🖼️ 关键图片
📊 实验亮点
SAILS在Gemma-2-9B模型上实现了高达99.6%的安全率,相比全量微调提升了7.4个百分点,并与基于RLHF的模型性能相当。同时,SAILS仅更新了0.19%的参数,显著降低了计算成本。此外,SAILS还提供了可解释性,有助于理解模型的安全决策过程。
🎯 应用场景
SAILS技术可应用于各种需要安全对齐的大语言模型,例如聊天机器人、智能助手等。通过提高模型拒绝有害请求的能力,降低其产生不当言论的风险,从而提升用户体验和安全性。该技术还有助于提高模型的可解释性,为安全风险评估和模型改进提供依据,促进负责任的AI发展。
📄 摘要(原文)
Safety alignment -- training large language models (LLMs) to refuse harmful requests while remaining helpful -- is critical for responsible deployment. Prior work established that safety behaviors are governed by low-rank structures, suggesting parameter-efficient fine-tuning (PEFT) should be well-suited for alignment. However, Low-Rank Adaptation (LoRA) consistently underperforms full fine-tuning and reinforcement learning on safety benchmarks. We attribute this gap to semantic entanglement: safety-relevant directions are intertwined with unrelated concepts due to polysemanticity, impeding implicit subspace identification. To address this, we propose SAILS (Safety Alignment via Interpretable Low-rank Subspace), which leverages Sparse Autoencoders (SAEs) to disentangle representations into monosemantic features, constructs an interpretable safety subspace from SAE decoder directions, and uses it to initialize LoRA adapters. Theoretically, we prove that SAE-based identification achieves arbitrarily small recovery error under monosemanticity assumptions, while direct identification suffers an irreducible error floor. Empirically, SAILS achieves up to 99.6% safety rate on Gemma-2-9B -- exceeding full fine-tuning by 7.4 points and matching RLHF-based models -- while updating only 0.19% of parameters and providing interpretability.