Eliminating Agentic Workflow for Introduction Generation with Parametric Stage Tokens
作者: Meicong Zhang, Tiancheng su, Guoxiu He
分类: cs.CL, cs.AI
发布日期: 2025-12-28
💡 一句话要点
提出STIG框架,通过参数化阶段令牌消除Agentic工作流,提升LLM生成研究介绍的质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 Agentic工作流 研究介绍生成 阶段令牌 指令微调
📋 核心要点
- 现有Agentic工作流在生成研究介绍时存在推理链长、误差累积和文本连贯性差等问题。
- 论文提出STIG框架,通过参数化阶段令牌将工作流逻辑编码到LLM中,实现单次推理生成。
- 实验表明,STIG在语义相似性和句子级结构合理性方面优于传统Agentic工作流和其他基线。
📝 摘要(中文)
近年来,使用预定义的Agentic工作流指导大型语言模型(LLM)进行文献分类和综述已成为研究热点。然而,撰写研究介绍更具挑战性,它需要严谨的逻辑、连贯的结构和抽象的概括。现有的工作流通常存在推理链过长、误差累积和文本连贯性降低等问题。为了解决这些限制,我们提出消除外部Agentic工作流,而是直接将它们的逻辑结构参数化到LLM中,从而在单次推理中生成完整的介绍。为此,我们引入了用于介绍生成的阶段令牌(STIG)。STIG将原始工作流的多个阶段转换为显式的阶段信号,这些信号指导模型在生成过程中遵循不同的逻辑角色和功能。通过指令微调,模型学习阶段令牌和文本功能之间的映射,以及阶段之间的逻辑顺序和转换模式,并将这些知识编码到模型参数中。实验结果表明,STIG可以在单次推理中生成多阶段文本,而不需要显式的工作流调用。在语义相似性和句子级结构合理性指标上,STIG优于传统的Agentic工作流和其他基线。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在生成研究介绍时,由于传统Agentic工作流的局限性而导致的问题。现有的Agentic工作流通常依赖于预定义的外部流程,这会导致推理链过长、误差累积,并降低生成文本的连贯性。此外,研究介绍需要严谨的逻辑、连贯的结构和抽象的概括,这使得现有的工作流难以胜任。
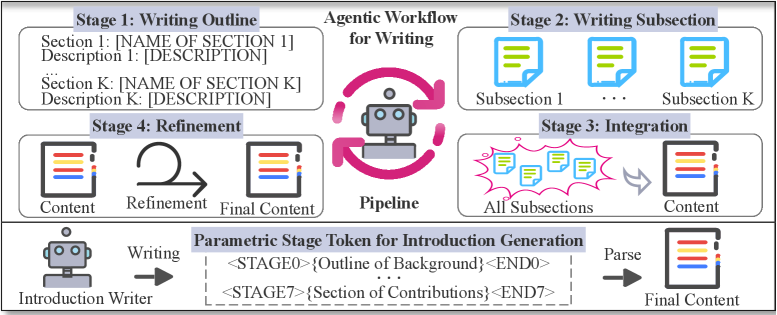
核心思路:论文的核心思路是消除外部Agentic工作流,转而将工作流的逻辑结构直接参数化到LLM中。通过将工作流的多个阶段转换为显式的阶段信号(Stage Tokens),模型可以在单次推理中生成完整的介绍。这种方法避免了外部工作流的调用,减少了误差累积的可能性,并提高了生成文本的连贯性。
技术框架:STIG框架的核心是Stage Token。它将原始Agentic工作流的多个阶段(例如,背景介绍、问题提出、方法概述、贡献总结)转换为显式的阶段信号。在生成过程中,模型根据当前的Stage Token来确定应该执行的逻辑角色和功能。通过指令微调,模型学习Stage Token与文本功能之间的映射关系,以及阶段之间的逻辑顺序和转换模式。整个过程无需显式的工作流调用,而是在单次推理中完成。
关键创新:论文最重要的技术创新点在于将Agentic工作流的逻辑结构参数化到LLM中。与传统的Agentic工作流相比,STIG不需要预定义的外部流程,而是通过Stage Token来引导模型生成。这种方法避免了外部工作流的调用,减少了误差累积的可能性,并提高了生成文本的连贯性。此外,STIG还通过指令微调,使模型能够学习Stage Token与文本功能之间的映射关系,从而更好地理解和执行生成任务。
关键设计:STIG的关键设计在于Stage Token的定义和指令微调过程。Stage Token需要能够清晰地表达工作流的各个阶段,并与相应的文本功能建立明确的映射关系。指令微调过程需要设计合适的训练数据,以使模型能够学习Stage Token与文本功能之间的映射关系,以及阶段之间的逻辑顺序和转换模式。具体的参数设置、损失函数和网络结构等技术细节在论文的补充材料中提供。
🖼️ 关键图片


📊 实验亮点
实验结果表明,STIG在语义相似性和句子级结构合理性指标上均优于传统的Agentic工作流和其他基线方法。具体而言,STIG能够生成更符合逻辑、结构更合理的介绍文本,并且在语义上更接近人工撰写的介绍。这些结果验证了STIG框架的有效性和优越性。
🎯 应用场景
该研究成果可应用于自动化科研写作、论文辅助生成等领域,帮助研究人员更高效地撰写高质量的研究介绍。此外,该方法还可以推广到其他需要多阶段生成的文本任务中,例如报告撰写、新闻报道等,具有广泛的应用前景和实际价值,有望提升LLM在复杂文本生成任务中的表现。
📄 摘要(原文)
In recent years, using predefined agentic workflows to guide large language models (LLMs) for literature classification and review has become a research focus. However, writing research introductions is more challenging. It requires rigorous logic, coherent structure, and abstract summarization. Existing workflows often suffer from long reasoning chains, error accumulation, and reduced textual coherence. To address these limitations, we propose eliminating external agentic workflows. Instead, we directly parameterize their logical structure into the LLM. This allows the generation of a complete introduction in a single inference. To this end, we introduce the Stage Token for Introduction Generation (STIG). STIG converts the multiple stages of the original workflow into explicit stage signals. These signals guide the model to follow different logical roles and functions during generation. Through instruction tuning, the model learns the mapping between stage tokens and text functions. It also learns the logical order and transition patterns between stages, encoding this knowledge into the model parameters. Experimental results show that STIG can generate multi-stage text in a single inference. It does not require explicit workflow calls. STIG outperforms traditional agentic workflows and other baselines on metrics of semantic similarity and sentence-level structural rationality. The code is provided in the Supplementary Materials.