Accelerating Language Model Workflows with Prompt Choreography
作者: TJ Bai, Jason Eisner
分类: cs.CL
发布日期: 2025-12-28
备注: to appear in TACL (final preprint of 2025-10-12); 10 pages + appendices
💡 一句话要点
Prompt Choreography:利用动态KV缓存加速LLM工作流
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 KV缓存 Prompt工程 多智能体系统 工作流优化
📋 核心要点
- 现有LLM工作流存在大量冗余计算,重复编码消息导致效率低下,成为性能瓶颈。
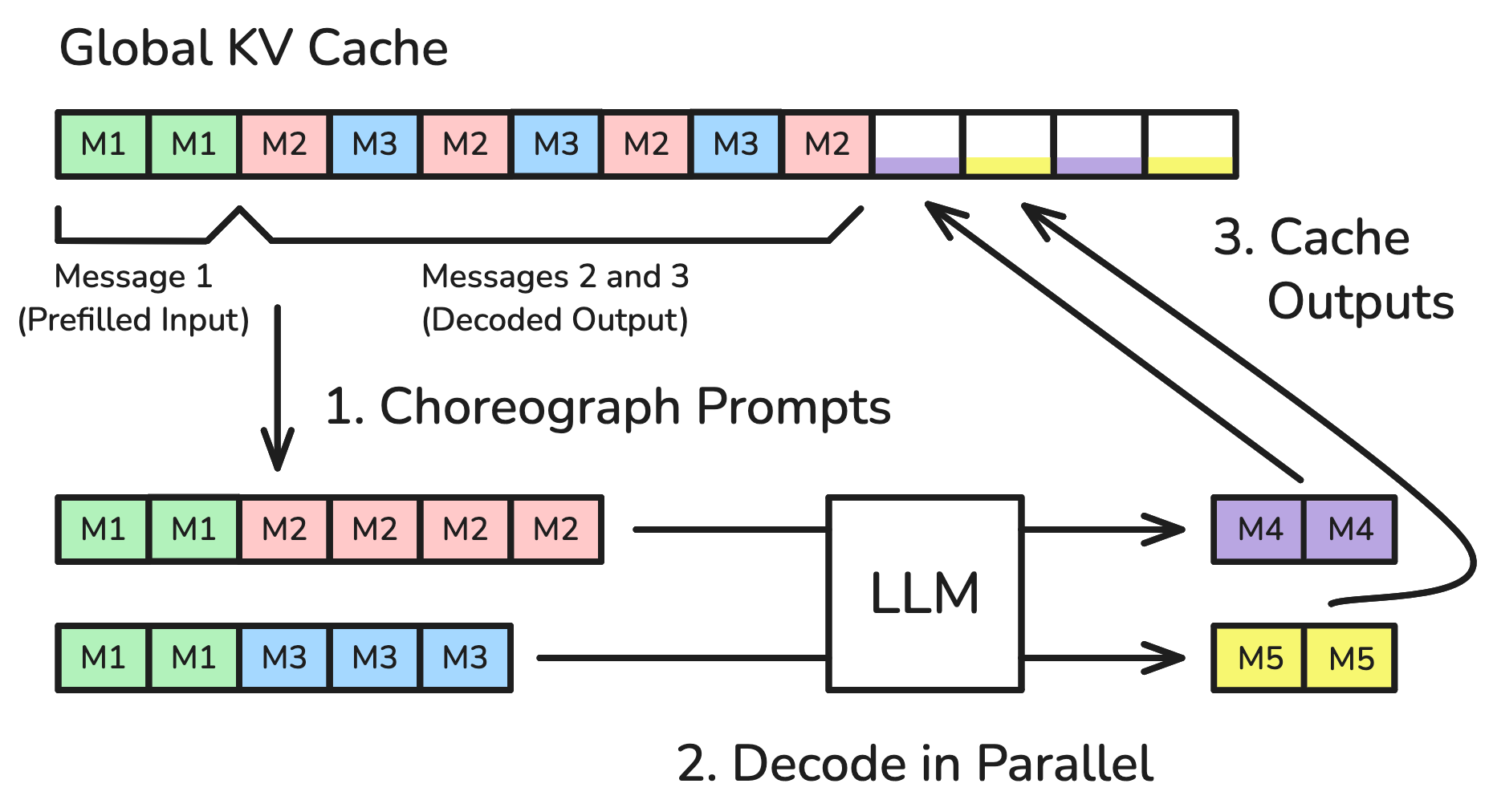
- Prompt Choreography通过维护全局动态KV缓存,允许LLM调用关注先前编码消息的任意子集,避免重复计算。
- 实验表明,该方法显著降低了消息延迟,并在特定工作流中实现了超过2.2倍的端到端加速。
📝 摘要(中文)
大型语言模型越来越多地部署在多智能体工作流中。我们提出了Prompt Choreography,一个通过维护动态的全局KV缓存来高效执行LLM工作流的框架。每次LLM调用都可以关注先前编码的消息的任意重排序子集。支持并行调用。虽然缓存消息的编码有时会产生与在新上下文中重新编码它们不同的结果,但我们在不同的设置中表明,微调LLM以使用缓存可以帮助它模仿原始结果。Prompt Choreography显著降低了每个消息的延迟(首次token时间快2.0-6.2倍),并在一些由冗余计算主导的工作流中实现了显著的端到端加速(>2.2倍)。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在多智能体工作流中效率低下的问题。现有的方法通常需要对相同的消息进行重复编码,尤其是在需要对历史信息进行追溯或组合时,这导致了大量的冗余计算,增加了延迟,降低了整体工作流的效率。
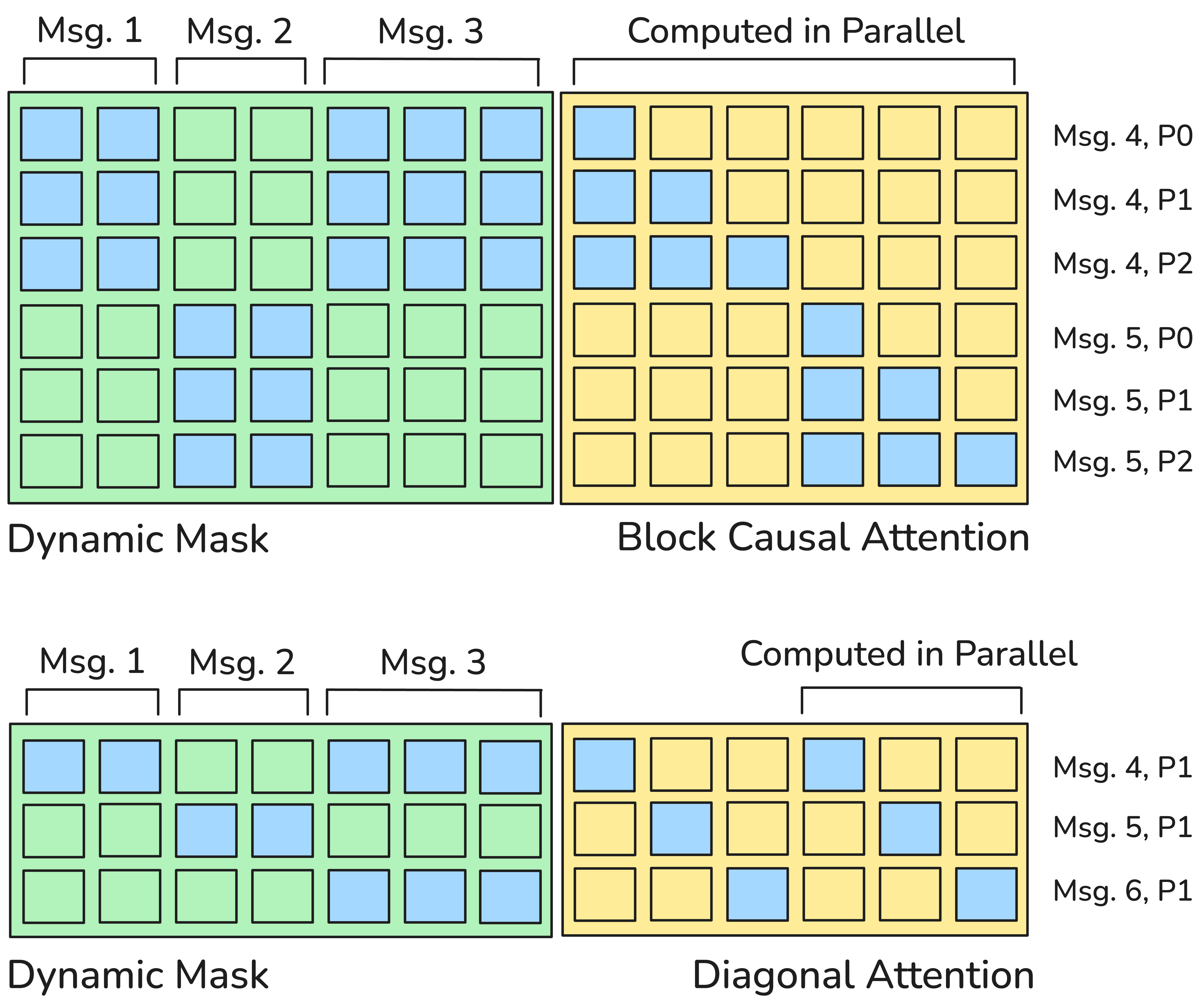
核心思路:论文的核心思路是引入一个动态的全局KV缓存(Key-Value Cache),用于存储先前编码的消息。这样,后续的LLM调用可以通过关注(attend to)缓存中已编码的消息,避免重复编码,从而加速整个工作流程。关键在于如何有效地管理和利用这个缓存,以及如何保证缓存机制引入的偏差不会显著影响LLM的性能。
技术框架:Prompt Choreography框架包含以下几个主要模块:1) 消息编码模块:负责将输入消息编码成KV表示,并存储到全局KV缓存中。2) 缓存管理模块:负责维护和更新全局KV缓存,包括消息的添加、删除和排序等操作。3) 注意力机制模块:LLM在进行推理时,可以通过注意力机制选择性地关注缓存中的消息,从而避免重复编码。4) 微调模块:为了弥补由于缓存机制引入的偏差,论文还提出了对LLM进行微调的方法,使其更好地适应缓存机制。
关键创新:该方法最重要的创新点在于提出了Prompt Choreography的概念,即通过动态管理和利用全局KV缓存,实现LLM工作流的高效执行。与传统的重复编码方法相比,Prompt Choreography可以显著减少冗余计算,提高效率。此外,通过微调LLM,可以有效缓解缓存机制引入的偏差,保证LLM的性能。
关键设计:在关键设计方面,论文可能涉及以下技术细节:1) 缓存的组织方式:如何组织和存储KV缓存,以便高效地进行检索和更新。2) 注意力机制的改进:如何改进注意力机制,使其更好地关注缓存中的消息。3) 微调策略:如何设计微调策略,使LLM更好地适应缓存机制,例如,可以使用对比学习或知识蒸馏等方法。4) 并行调用支持:如何支持并行的LLM调用,充分利用计算资源。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Prompt Choreography能够显著降低消息延迟,首次token时间快2.0-6.2倍。在一些由冗余计算主导的工作流中,实现了超过2.2倍的端到端加速。通过对LLM进行微调,可以有效缓解缓存机制引入的偏差,保证LLM的性能。这些结果表明,Prompt Choreography是一种有效的加速LLM工作流的方法。
🎯 应用场景
Prompt Choreography具有广泛的应用前景,例如在对话系统、智能客服、自动化报告生成等领域。通过加速LLM工作流,可以显著提升用户体验,降低计算成本。未来,该技术可以进一步应用于更复杂的AI系统中,例如多智能体协作、机器人控制等,实现更高效、智能的自动化。
📄 摘要(原文)
Large language models are increasingly deployed in multi-agent workflows. We introduce Prompt Choreography, a framework that efficiently executes LLM workflows by maintaining a dynamic, global KV cache. Each LLM call can attend to an arbitrary, reordered subset of previously encoded messages. Parallel calls are supported. Though caching messages' encodings sometimes gives different results from re-encoding them in a new context, we show in diverse settings that fine-tuning the LLM to work with the cache can help it mimic the original results. Prompt Choreography significantly reduces per-message latency (2.0--6.2$\times$ faster time-to-first-token) and achieves substantial end-to-end speedups ($>$2.2$\times$) in some workflows dominated by redundant computation.