Improving Generalization in LLM Structured Pruning via Function-Aware Neuron Grouping
作者: Tao Yu, Yongqi An, Kuan Zhu, Guibo Zhu, Ming Tang, Jinqiao Wang
分类: cs.CL
发布日期: 2025-12-28
💡 一句话要点
提出Function-Aware Neuron Grouping (FANG)方法,提升LLM结构化剪枝的泛化能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 结构化剪枝 神经元分组 泛化能力 后训练量化
📋 核心要点
- 现有LLM剪枝方法在校准集偏差下泛化能力不足,无法有效适应下游任务。
- FANG通过功能感知的神经元分组,识别并保留对特定功能至关重要的神经元,缓解校准偏差。
- 实验表明,FANG在下游任务上显著提升了准确率,并与现有SOTA剪枝方法结合取得了更优结果。
📝 摘要(中文)
大型语言模型(LLM)在自然语言任务中表现出令人印象深刻的性能,但由于其规模庞大,导致计算和存储成本巨大。后训练结构化剪枝提供了一种有效的解决方案。然而,当少样本校准集不能充分反映预训练数据分布时,现有方法对下游任务的泛化能力有限。为了解决这个问题,我们提出了一种Function-Aware Neuron Grouping (FANG)的后训练剪枝框架,通过识别和保留对特定功能至关重要的神经元来缓解校准偏差。FANG基于神经元处理的语义上下文类型对神经元进行分组,并独立地剪枝每个组。在每个组内的重要性估计期间,与神经元组的功能角色强烈相关的token被赋予更高的权重。此外,FANG还保留了跨多种上下文类型做出贡献的神经元。为了在稀疏性和性能之间实现更好的权衡,它根据每个块的功能复杂性自适应地为每个块分配稀疏性。实验表明,FANG在保持语言建模性能的同时,提高了下游任务的准确性。当与FLAP和OBC这两种具有代表性的剪枝方法结合使用时,FANG取得了最先进(SOTA)的结果。具体而言,在30%和40%的稀疏度下,FANG的平均准确率比FLAP和OBC高出1.5%--8.5%。
🔬 方法详解
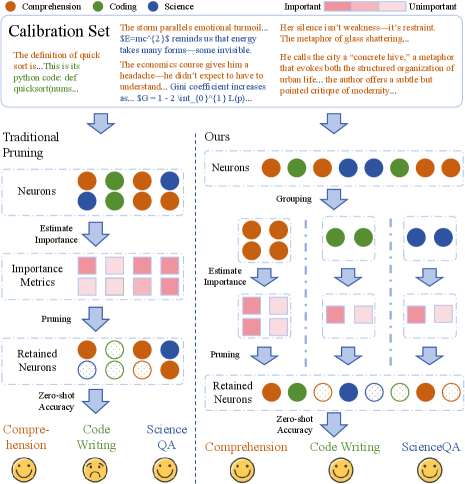
问题定义:现有LLM的后训练结构化剪枝方法依赖于校准集来估计神经元的重要性。当校准集不能充分代表预训练数据分布时,这些方法在下游任务上的泛化能力会受到限制。尤其是在少样本场景下,校准偏差问题更加突出,导致剪枝后的模型性能下降。
核心思路:FANG的核心思路是通过功能感知的神经元分组来缓解校准偏差。它假设模型中的神经元负责处理不同类型的语义上下文,因此将具有相似功能的神经元分组在一起,并独立地对每个组进行剪枝。通过这种方式,可以更有针对性地保留对特定功能至关重要的神经元,从而提高剪枝后模型的泛化能力。
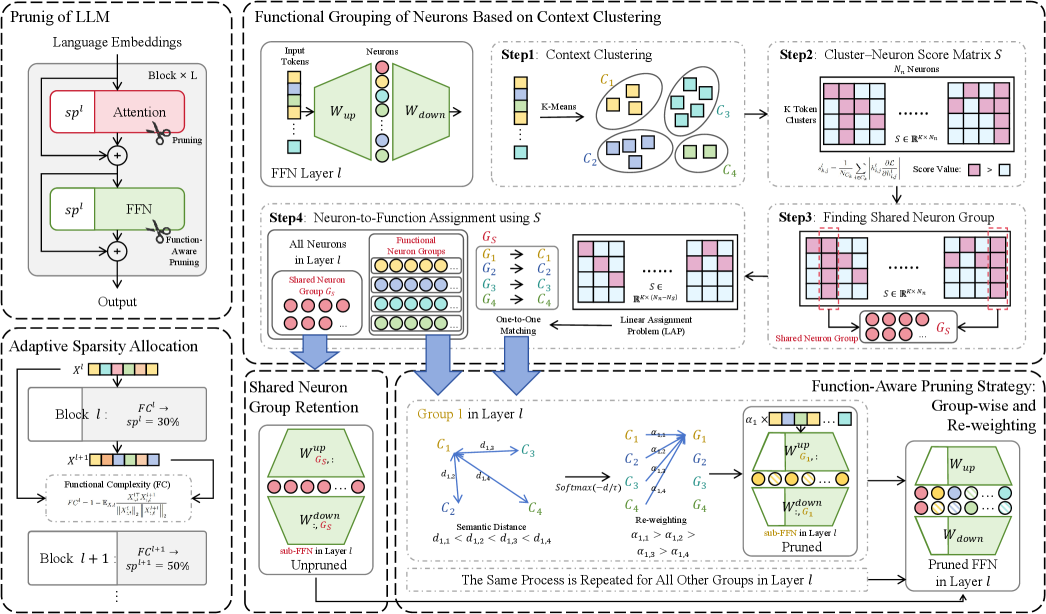
技术框架:FANG的整体框架包括以下几个主要步骤:1) 神经元分组:基于神经元处理的语义上下文类型,将神经元分组。具体实现方法未知。2) 组内重要性估计:在每个神经元组内,估计神经元的重要性。与神经元组的功能角色强烈相关的token被赋予更高的权重。3) 自适应稀疏性分配:根据每个块的功能复杂性,自适应地为每个块分配稀疏性。功能越复杂的块,分配的稀疏性越低,以保留更多的神经元。4) 神经元剪枝:根据重要性估计和稀疏性分配的结果,对每个神经元组进行剪枝。
关键创新:FANG的关键创新在于其功能感知的神经元分组策略。与传统的剪枝方法不同,FANG不是简单地根据神经元的权重或激活值来估计其重要性,而是考虑了神经元的功能角色。通过将具有相似功能的神经元分组在一起,FANG可以更有针对性地保留对特定功能至关重要的神经元,从而提高剪枝后模型的泛化能力。
关键设计:论文中没有详细描述神经元分组的具体实现方法,以及如何确定token与神经元组的功能角色之间的相关性。自适应稀疏性分配的具体策略也未知。这些都是需要进一步研究的关键设计细节。
🖼️ 关键图片
📊 实验亮点
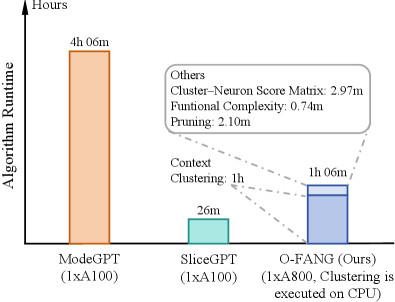
实验结果表明,FANG在下游任务上显著提升了准确率,并且在30%和40%的稀疏度下,平均准确率比FLAP和OBC分别高出1.5%和8.5%。这些结果表明,FANG能够有效地缓解校准偏差,并提高剪枝后模型的泛化能力。此外,FANG还可以与现有的剪枝方法(如FLAP和OBC)结合使用,进一步提高剪枝效果。
🎯 应用场景
FANG方法可应用于各种需要压缩LLM的场景,例如移动设备部署、边缘计算和资源受限的环境。通过提高剪枝后模型的泛化能力,FANG可以降低LLM的部署成本,并使其能够在更广泛的应用场景中使用。该方法还有助于开发更高效、更绿色的AI系统。
📄 摘要(原文)
Large Language Models (LLMs) demonstrate impressive performance across natural language tasks but incur substantial computational and storage costs due to their scale. Post-training structured pruning offers an efficient solution. However, when few-shot calibration sets fail to adequately reflect the pretraining data distribution, existing methods exhibit limited generalization to downstream tasks. To address this issue, we propose Function-Aware Neuron Grouping (FANG), a post-training pruning framework that alleviates calibration bias by identifying and preserving neurons critical to specific function. FANG groups neurons with similar function based on the type of semantic context they process and prunes each group independently. During importance estimation within each group, tokens that strongly correlate with the functional role of the neuron group are given higher weighting. Additionally, FANG also preserves neurons that contribute across multiple context types. To achieve a better trade-off between sparsity and performance, it allocates sparsity to each block adaptively based on its functional complexity. Experiments show that FANG improves downstream accuracy while preserving language modeling performance. It achieves the state-of-the-art (SOTA) results when combined with FLAP and OBC, two representative pruning methods. Specifically, FANG outperforms FLAP and OBC by 1.5%--8.5% in average accuracy under 30% and 40% sparsity.