AutoForge: Automated Environment Synthesis for Agentic Reinforcement Learning
作者: Shihao Cai, Runnan Fang, Jialong Wu, Baixuan Li, Xinyu Wang, Yong Jiang, Liangcai Su, Liwen Zhang, Wenbiao Yin, Zhen Zhang, Fuli Feng, Pengjun Xie, Xiaobin Wang
分类: cs.CL, cs.AI
发布日期: 2025-12-28
💡 一句话要点
AutoForge:用于Agent强化学习的自动化环境合成方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Agent强化学习 自动化环境合成 模拟环境 用户不稳定性 环境级别强化学习
📋 核心要点
- 现有语言代理强化学习方法依赖半自动化环境,任务难度不足,且模拟用户不稳定,环境异质性大。
- AutoForge提出统一的自动化环境合成流程,生成高难度且易验证的任务,并设计环境级别强化学习算法。
- 在多个Agent基准测试中,AutoForge验证了其有效性,并展示了良好的域外泛化能力。
📝 摘要(中文)
本文提出了一种用于增强语言代理的、经济高效且高度可扩展的模拟环境强化学习方法。现有方法局限于半自动化环境合成或缺乏足够难度的任务,在广度和深度上均有所欠缺。此外,集成到这些环境中的模拟用户的不稳定性以及模拟环境之间的异质性,给Agent强化学习带来了进一步的挑战。为此,本文提出了:(1)一个统一的自动化和可扩展的模拟环境合成流程,该流程与高难度但易于验证的任务相关联;(2)一种环境级别的强化学习算法,该算法不仅有效地缓解了用户不稳定性,而且在环境级别执行优势估计,从而提高了训练效率和稳定性。在tau-bench、tau2-Bench和VitaBench等Agent基准上的综合评估验证了本文提出方法的有效性。进一步的深入分析强调了其域外泛化能力。
🔬 方法详解
问题定义:现有Agent强化学习方法在模拟环境中训练时,面临环境构建成本高、任务难度不足、模拟用户行为不稳定以及环境异质性等问题。这些问题限制了Agent在复杂场景下的学习能力和泛化性能。现有方法难以自动化生成多样且具有挑战性的环境,并且难以有效应对模拟用户的不确定性。
核心思路:AutoForge的核心思路是自动化生成模拟环境,并设计一种环境级别的强化学习算法来解决用户不稳定性问题。通过自动化环境生成,可以降低环境构建成本,并生成多样化的训练环境。环境级别的强化学习算法则可以有效缓解模拟用户行为的不确定性,提高训练的稳定性和效率。
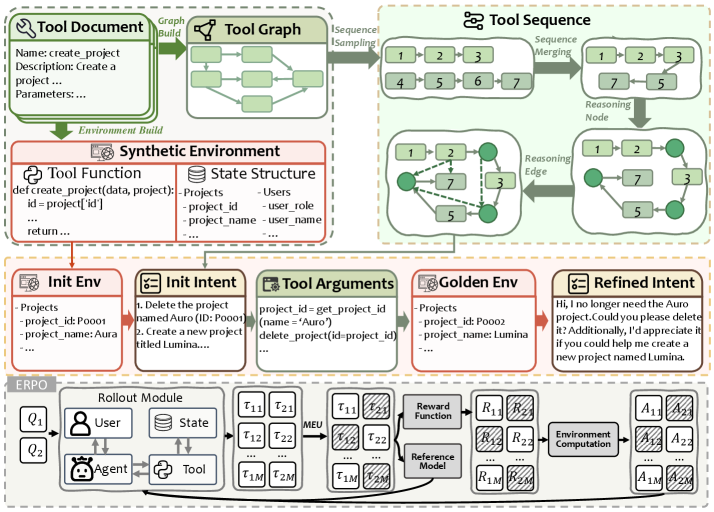
技术框架:AutoForge包含两个主要组成部分:自动化环境合成流程和环境级别强化学习算法。自动化环境合成流程负责生成具有高难度但易于验证的任务的模拟环境。环境级别强化学习算法则利用这些环境来训练Agent,并缓解用户不稳定性。整体流程包括:1. 任务定义与环境参数化;2. 环境自动生成;3. Agent在生成环境中进行强化学习训练;4. 评估Agent在真实环境或新环境中的性能。
关键创新:AutoForge的关键创新在于:(1)提出了一个统一的自动化和可扩展的模拟环境合成流程,能够生成高难度但易于验证的任务;(2)设计了一种环境级别的强化学习算法,该算法不仅有效地缓解了用户不稳定性,而且在环境级别执行优势估计,从而提高了训练效率和稳定性。与现有方法相比,AutoForge能够更高效地生成多样化的训练环境,并更有效地应对模拟用户的不确定性。
关键设计:在环境合成方面,可能涉及任务参数的随机化、环境元素的组合以及难度控制策略。在环境级别强化学习算法方面,可能包括环境奖励的设计、优势函数的构建以及针对用户不确定性的鲁棒性优化策略。具体的参数设置、损失函数和网络结构等细节在论文中应该有更详细的描述,此处未知。
🖼️ 关键图片


📊 实验亮点
AutoForge在tau-bench、tau2-Bench和VitaBench等Agent基准测试中取得了显著的性能提升,验证了其有效性。实验结果表明,AutoForge不仅能够提高Agent在训练环境中的性能,还能够提升其在域外环境中的泛化能力。具体的性能数据和提升幅度需要在论文中查找。
🎯 应用场景
AutoForge可应用于各种需要语言代理的场景,例如智能客服、虚拟助手、游戏AI等。通过自动化生成训练环境,可以降低Agent的开发成本,并提高其在复杂环境中的适应能力。该研究对于推动Agent强化学习的实际应用具有重要意义,并有望加速人工智能技术在各行业的落地。
📄 摘要(原文)
Conducting reinforcement learning (RL) in simulated environments offers a cost-effective and highly scalable way to enhance language-based agents. However, previous work has been limited to semi-automated environment synthesis or tasks lacking sufficient difficulty, offering little breadth or depth. In addition, the instability of simulated users integrated into these environments, along with the heterogeneity across simulated environments, poses further challenges for agentic RL. In this work, we propose: (1) a unified pipeline for automated and scalable synthesis of simulated environments associated with high-difficulty but easily verifiable tasks; and (2) an environment level RL algorithm that not only effectively mitigates user instability but also performs advantage estimation at the environment level, thereby improving training efficiency and stability. Comprehensive evaluations on agentic benchmarks, including tau-bench, tau2-Bench, and VitaBench, validate the effectiveness of our proposed method. Further in-depth analyses underscore its out-of-domain generalization.