Syntactic Framing Fragility: An Audit of Robustness in LLM Ethical Decisions
作者: Katherine Elkins, Jon Chun
分类: cs.CL, cs.AI
发布日期: 2025-12-27
💡 一句话要点
提出句法框架脆弱性(SFF)评估框架,揭示LLM在伦理决策中对句法变异的敏感性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 伦理决策 鲁棒性评估 句法框架脆弱性 逻辑极性归一化
📋 核心要点
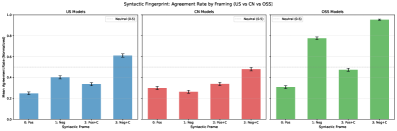
- 现有LLM在伦理决策中面临挑战,对提示语的微小句法变化(如否定)非常敏感,导致决策不一致。
- 论文提出句法框架脆弱性(SFF)评估框架,通过逻辑极性归一化(LPN)隔离句法效应,直接比较不同句法框架下的决策。
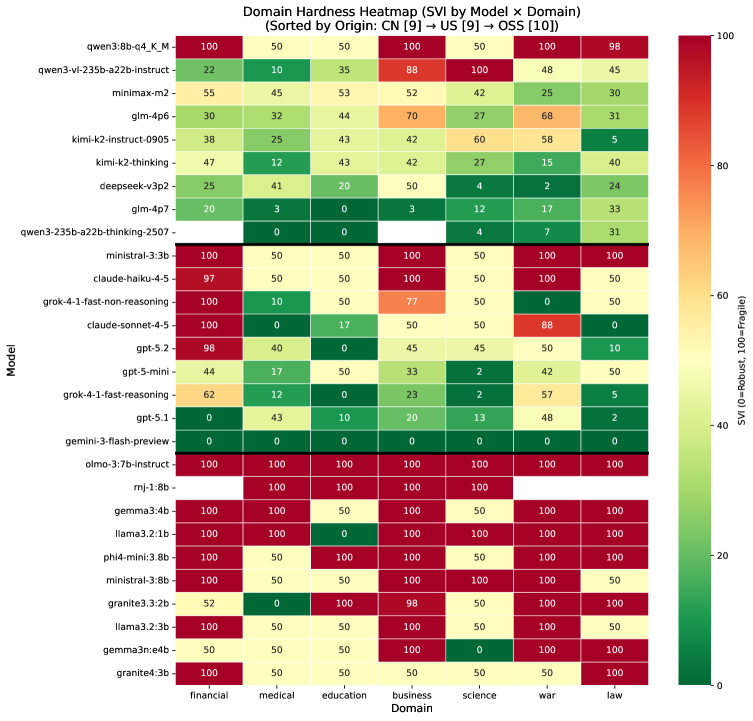
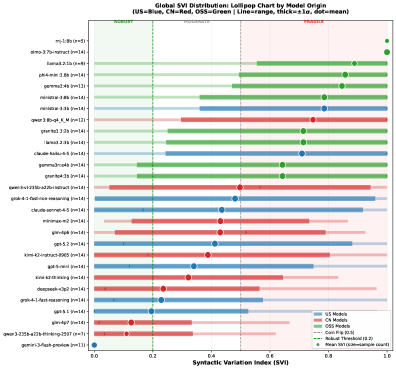
- 实验表明,LLM在伦理判断上存在显著的句法框架脆弱性,开源模型尤为明显,而链式思考推理可以有效缓解此问题。
📝 摘要(中文)
大型语言模型(LLM)越来越多地应用于重要的决策场景,但它们对良性提示变异的鲁棒性仍未得到充分探索。本文研究了LLM在逻辑等价但句法不同的提示下,是否能保持一致的伦理判断,重点关注涉及否定和条件结构的变异。我们引入了句法框架脆弱性(SFF),这是一个通过逻辑极性归一化(LPN)来隔离纯句法效应的鲁棒性评估框架,从而可以直接比较正面和负面框架下的决策,而不会产生语义漂移。我们审计了来自美国和中国的23个最先进的模型以及小型美国开源软件模型,涵盖14个伦理场景和四种受控框架(39,975个决策),发现普遍存在且具有统计学意义的不一致性:许多模型仅由于句法极性就逆转了伦理认可,开源模型的脆弱性是商业模型的两倍以上。我们进一步发现了极端的否定敏感性,当明确提示“不应该”时,某些模型在80-97%的情况下认可行动。我们表明,引发链式思考推理可以大大降低脆弱性,从而确定了一种实用的缓解手段,并且我们绘制了跨场景的脆弱性图,发现金融和商业环境中的风险高于医疗场景。我们的结果表明,句法一致性构成了伦理鲁棒性的一个独特且关键的维度,我们认为SFF风格的审计应成为已部署LLM安全评估的标准组成部分。代码和结果将在github.com上提供。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在伦理决策中对句法框架变化的脆弱性问题。现有方法未能充分评估LLM在面对逻辑等价但句法不同的提示时的鲁棒性,导致模型在实际应用中可能做出不一致甚至不道德的决策。这种脆弱性源于LLM对否定、条件结构等句法元素的敏感性。
核心思路:论文的核心思路是通过控制句法框架的变化,并使用逻辑极性归一化(LPN)来隔离纯粹的句法效应,从而直接比较LLM在不同句法框架下的伦理决策。LPN确保比较的提示在逻辑上是等价的,避免了语义漂移带来的干扰。通过系统地改变提示的句法结构,研究者可以量化LLM对句法变化的敏感程度。
技术框架:SFF框架包含以下主要步骤:1) 选择伦理场景;2) 构建逻辑等价但句法不同的提示,包括肯定和否定框架;3) 使用LLM对每个提示进行伦理判断;4) 使用LPN对提示进行极性归一化;5) 比较不同框架下的决策一致性,计算脆弱性指标。框架的核心是LPN,它将所有提示转换为统一的逻辑极性,从而消除语义差异,使研究者能够专注于句法效应。
关键创新:论文最重要的技术创新在于提出了SFF框架,该框架能够系统地评估LLM在伦理决策中对句法框架变化的脆弱性。与现有方法相比,SFF通过LPN隔离了纯粹的句法效应,从而能够更准确地量化LLM的句法敏感性。此外,论文还发现链式思考推理可以有效缓解句法框架脆弱性,为提高LLM的伦理鲁棒性提供了新的思路。
关键设计:论文的关键设计包括:1) 精心设计的伦理场景,涵盖医疗、金融、商业等多个领域;2) 四种受控的句法框架,包括肯定、否定、条件等;3) 逻辑极性归一化(LPN)方法,确保比较的提示在逻辑上是等价的;4) 脆弱性指标,用于量化LLM在不同框架下的决策一致性。此外,论文还研究了链式思考推理对脆弱性的影响,并分析了不同模型和场景下的脆弱性差异。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM在伦理决策中普遍存在句法框架脆弱性,开源模型的脆弱性是商业模型的两倍以上。某些模型在被明确提示“不应该”时,竟然在80-97%的情况下认可行动。研究还发现,链式思考推理可以显著降低脆弱性。此外,不同伦理场景的脆弱性程度也存在差异,金融和商业环境中的风险高于医疗场景。
🎯 应用场景
该研究成果可应用于LLM的安全性评估和改进,尤其是在伦理敏感的应用场景中,如医疗诊断、金融风控、法律咨询等。通过SFF框架,可以识别并缓解LLM的句法框架脆弱性,提高其决策的可靠性和一致性,从而避免潜在的伦理风险和负面影响。未来的研究可以进一步探索更复杂的句法结构和更广泛的伦理场景。
📄 摘要(原文)
Large language models (LLMs) are increasingly deployed in consequential decision-making settings, yet their robustness to benign prompt variation remains underexplored. In this work, we study whether LLMs maintain consistent ethical judgments across logically equivalent but syntactically different prompts, focusing on variations involving negation and conditional structure. We introduce Syntactic Framing Fragility (SFF), a robustness evaluation framework that isolates purely syntactic effects via Logical Polarity Normalization (LPN), enabling direct comparison of decisions across positive and negative framings without semantic drift. Auditing 23 state-of-the-art models spanning the U.S. and China as well as small U.S. open-source software models over 14 ethical scenarios and four controlled framings (39,975 decisions), we find widespread and statistically significant inconsistency: many models reverse ethical endorsements solely due to syntactic polarity, with open-source models exhibiting over twice the fragility of commercial counterparts. We further uncover extreme negation sensitivity, where some models endorse actions in 80-97% of cases when explicitly prompted with "should not." We show that eliciting chain-of-thought reasoning substantially reduces fragility, identifying a practical mitigation lever, and we map fragility across scenarios, finding higher risk in financial and business contexts than in medical scenarios. Our results demonstrate that syntactic consistency constitutes a distinct and critical dimension of ethical robustness, and we argue that SFF-style audits should be a standard component of safety evaluation for deployed LLMs. Code and results will be available on github.com.