ADMEDTAGGER: an annotation framework for distillation of expert knowledge for the Polish medical language
作者: Franciszek Górski, Andrzej Czyżewski
分类: cs.CL, cs.AI
发布日期: 2025-12-27
💡 一句话要点
ADMEDTAGGER:利用多语言LLM蒸馏波兰语医学文本标注知识
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学文本分类 知识蒸馏 多语言LLM 波兰语 DistilBERT
📋 核心要点
- 医学文本标注资源匮乏,限制了波兰语医学文本分类器的开发和应用。
- 利用多语言LLM(Llama3.1)作为教师模型,自动标注大量波兰语医学文本,降低标注成本。
- DistilBERT模型在五个临床类别上均取得良好F1得分(>0.80),且模型体积小,推理速度快。
📝 摘要(中文)
本文介绍了一个标注框架ADMEDTAGGER,该框架展示了如何使用在大型语料库上预训练的多语言LLM作为教师模型,来提炼标注波兰语医学文本所需的专业知识。这项工作是ADMEDVOICE项目的一部分,该项目收集了代表五个临床类别(放射学、肿瘤学、心脏病学、高血压和病理学)的大量医学文本语料库。利用这些数据,需要开发一个多分类器,但根本问题是缺乏足够的资源来标注足够数量的文本。因此,该解决方案使用多语言Llama3.1模型来标注大量的波兰语医学文本语料库。使用有限的标注资源,仅验证了这些标签的一部分,并从中创建了一个测试集。以这种方式标注的数据随后被用于训练和验证三种不同类型的基于BERT架构的分类器——精馏的DistilBERT模型、在医学数据上微调的BioBERT和在波兰语语料库上微调的HerBERT。在训练的模型中,DistilBERT模型取得了最好的结果,每个临床类别的F1得分均>0.80,其中3个类别的F1得分>0.93。因此,获得了一系列高效的分类器,由于其体积小近500倍、GPU VRAM消耗低300倍以及推理速度快数百倍,因此可以替代大型语言模型。
🔬 方法详解
问题定义:论文旨在解决波兰语医学文本分类任务中,由于缺乏足够的标注数据而导致模型训练困难的问题。现有方法依赖人工标注,成本高昂且效率低下,难以满足大规模医学文本处理的需求。
核心思路:论文的核心思路是利用知识蒸馏技术,将大型多语言LLM(Llama3.1)的知识迁移到小型BERT模型(DistilBERT、BioBERT、HerBERT)上。通过LLM自动标注大量数据,再利用少量人工标注数据进行验证,从而构建大规模训练数据集。
技术框架:整体流程包括:1) 使用Llama3.1自动标注波兰语医学文本语料库;2) 人工验证部分标注数据,构建测试集;3) 使用自动标注数据训练DistilBERT、BioBERT和HerBERT模型;4) 在测试集上评估模型性能。
关键创新:关键创新在于利用多语言LLM进行医学领域的知识迁移,克服了特定语言(波兰语)医学文本标注资源不足的难题。通过知识蒸馏,在保证模型性能的同时,显著降低了模型体积和计算资源消耗。
关键设计:论文使用了Llama3.1进行数据标注,并选择了DistilBERT、BioBERT和HerBERT三种BERT变体作为学生模型。实验中,重点关注了不同模型在五个临床类别上的F1得分,以此评估模型的分类性能。没有提及具体的损失函数和网络结构等细节。
🖼️ 关键图片
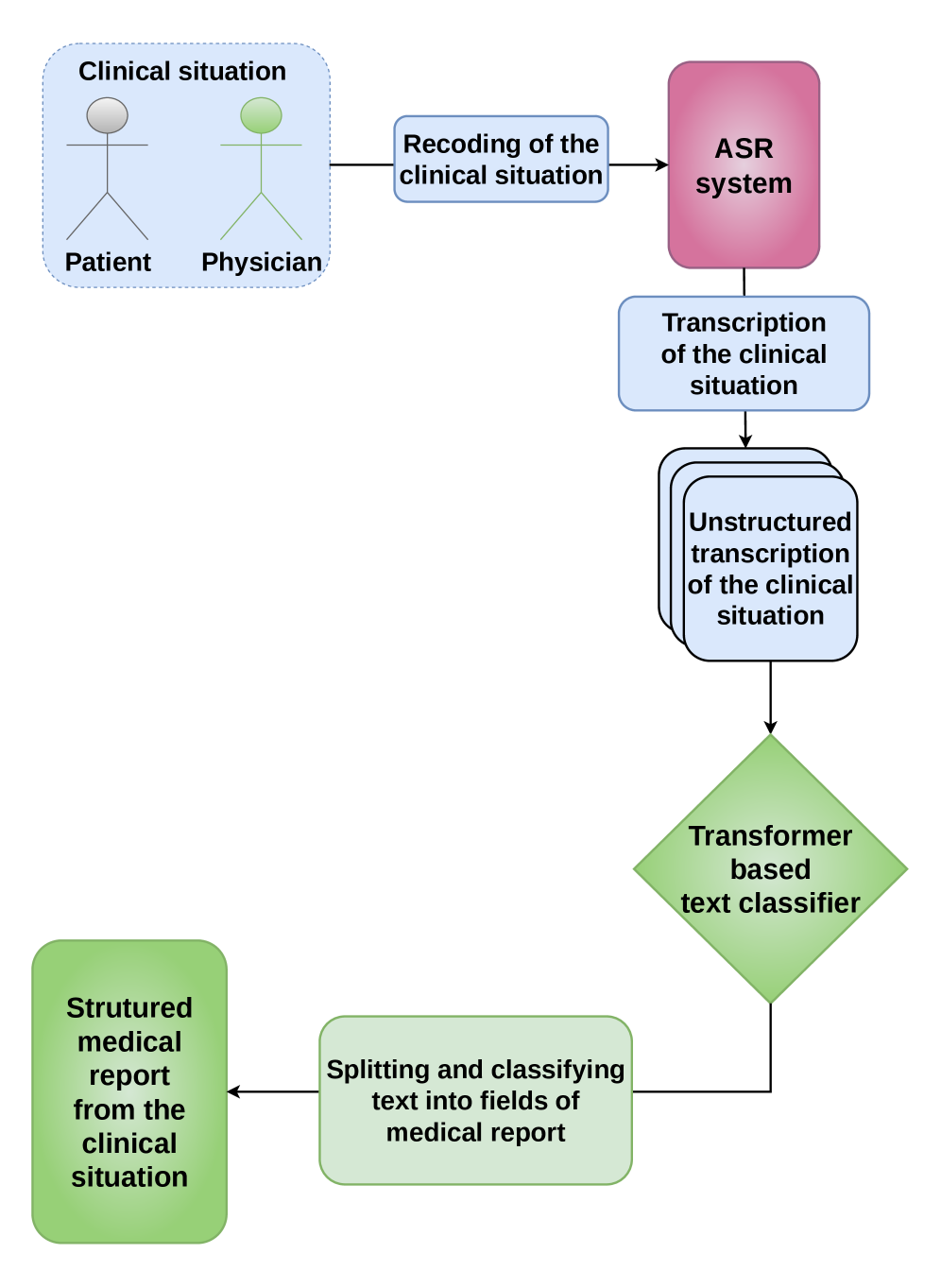
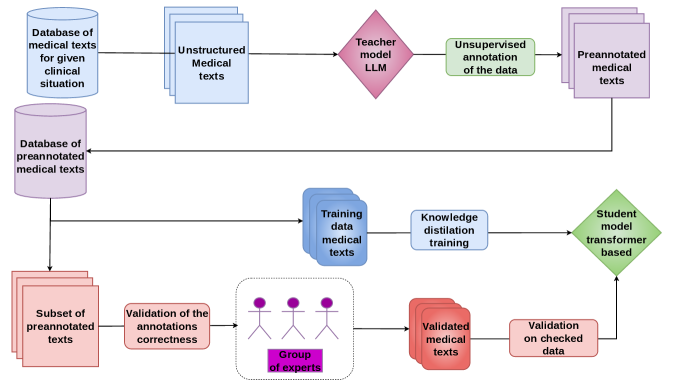

📊 实验亮点
实验结果表明,经过知识蒸馏的DistilBERT模型在五个临床类别上均取得了良好的F1得分(>0.80),其中三个类别的F1得分超过0.93。同时,DistilBERT模型相比大型LLM,体积小近500倍,GPU VRAM消耗低300倍,推理速度快数百倍,具有显著的性能优势。
🎯 应用场景
该研究成果可应用于波兰语医学文本的自动分类、信息提取和临床决策支持等领域。通过低成本、高效的模型部署,可以提升医疗服务的智能化水平,辅助医生进行诊断和治疗,并加速医学研究的进展。未来,该方法可以推广到其他低资源语言的医学文本处理任务中。
📄 摘要(原文)
In this work, we present an annotation framework that demonstrates how a multilingual LLM pretrained on a large corpus can be used as a teacher model to distill the expert knowledge needed for tagging medical texts in Polish. This work is part of a larger project called ADMEDVOICE, within which we collected an extensive corpus of medical texts representing five clinical categories - Radiology, Oncology, Cardiology, Hypertension, and Pathology. Using this data, we had to develop a multi-class classifier, but the fundamental problem turned out to be the lack of resources for annotating an adequate number of texts. Therefore, in our solution, we used the multilingual Llama3.1 model to annotate an extensive corpus of medical texts in Polish. Using our limited annotation resources, we verified only a portion of these labels, creating a test set from them. The data annotated in this way were then used for training and validation of 3 different types of classifiers based on the BERT architecture - the distilled DistilBERT model, BioBERT fine-tuned on medical data, and HerBERT fine-tuned on the Polish language corpus. Among the models we trained, the DistilBERT model achieved the best results, reaching an F1 score > 0.80 for each clinical category and an F1 score > 0.93 for 3 of them. In this way, we obtained a series of highly effective classifiers that represent an alternative to large language models, due to their nearly 500 times smaller size, 300 times lower GPU VRAM consumption, and several hundred times faster inference.