Topic Segmentation Using Generative Language Models
作者: Pierre Mackenzie, Maya Shah, Patrick Frenett
分类: cs.CL, cs.AI
发布日期: 2025-12-27
💡 一句话要点
提出基于生成式语言模型的篇章分割方法,利用重叠递归提示策略提升分割效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 篇章分割 大型语言模型 生成式模型 提示学习 自然语言处理
📋 核心要点
- 现有篇章分割方法依赖句子语义相似性,缺乏LLMs的长程依赖建模和知识利用能力。
- 提出重叠递归提示策略,结合句子枚举,充分利用LLMs的生成能力进行篇章分割。
- 实验表明,LLMs在篇章分割上优于现有方法,但仍存在一些问题需要进一步研究。
📝 摘要(中文)
本文探索了使用生成式大型语言模型(LLMs)进行篇章分割的方法,这是一个相对未被充分研究的领域。以往的方法主要依赖句子间的语义相似性,但这些模型缺乏LLMs所具备的长程依赖关系建模能力和广阔知识。本文提出了一种使用句子枚举的重叠和递归提示策略,并支持采用边界相似性评估指标。实验结果表明,LLMs在篇章分割方面可能比现有方法更有效,但在实际应用前仍有一些问题需要解决。
🔬 方法详解
问题定义:论文旨在解决篇章分割问题,即如何将一篇文档划分成多个主题连贯的片段。现有方法,如基于句子语义相似性的方法,无法有效捕捉长距离依赖关系,并且缺乏利用大规模知识的能力,导致分割效果不佳。
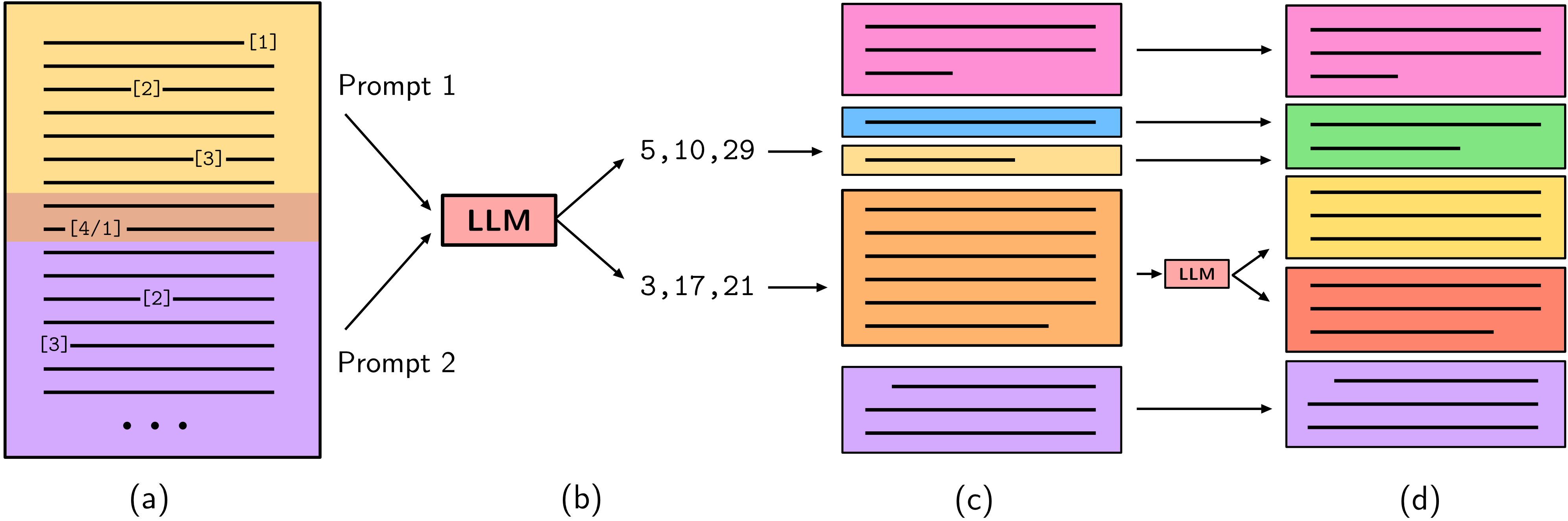
核心思路:论文的核心思路是利用大型语言模型(LLMs)的生成能力和知识储备来进行篇章分割。通过设计合适的提示(prompt),引导LLM生成与主题相关的文本,从而判断句子之间的主题边界。重叠和递归提示策略旨在更全面地评估句子之间的关系,提高分割的准确性。
技术框架:该方法主要包含以下几个阶段:1. 句子枚举:将输入文档分割成句子序列。2. 重叠提示:构建重叠的句子窗口,例如[sentence_i, sentence_{i+1}, sentence_{i+2}],作为LLM的输入。3. 递归提示:对每个句子窗口,使用LLM生成与主题相关的文本,并判断窗口内的句子是否属于同一主题。如果判断为不同主题,则在窗口内递归地进行更细粒度的分割。4. 边界确定:根据LLM的判断结果,确定主题边界。5. 边界相似性评估:采用边界相似性评估指标来评估分割结果的质量。
关键创新:该方法最重要的创新点在于利用了LLM的生成能力进行篇章分割,而不是仅仅依赖句子之间的语义相似性。重叠和递归提示策略能够更全面地评估句子之间的关系,提高分割的准确性。此外,支持采用边界相似性评估指标,使得评估更加客观。
关键设计:论文中关键的设计包括:1. 提示的设计:如何设计有效的提示,引导LLM生成与主题相关的文本,是影响分割效果的关键。具体的提示内容未知。2. 重叠窗口的大小:重叠窗口的大小会影响分割的粒度和计算复杂度。3. 递归分割的停止条件:如何确定递归分割的停止条件,避免过度分割,需要仔细设计。4. 边界相似性评估指标的选择:选择合适的边界相似性评估指标,能够更准确地评估分割结果的质量。具体参数设置和损失函数等细节未知。
🖼️ 关键图片
📊 实验亮点
论文结果表明,基于LLMs的篇章分割方法在某些情况下可以优于现有的基于语义相似性的方法。虽然具体的性能数据和提升幅度未知,但该研究证明了LLMs在篇章分割领域的潜力,并为未来的研究方向提供了新的思路。但同时也指出,LLMs在篇章分割中仍然存在一些问题,需要进一步解决。
🎯 应用场景
该研究成果可应用于多种场景,如自动生成文章摘要、构建知识图谱、改进信息检索系统、优化对话系统等。通过准确地分割篇章主题,可以更好地理解文档内容,提高信息处理的效率和质量。未来,该方法有望在教育、新闻、科研等领域发挥重要作用。
📄 摘要(原文)
Topic segmentation using generative Large Language Models (LLMs) remains relatively unexplored. Previous methods use semantic similarity between sentences, but such models lack the long range dependencies and vast knowledge found in LLMs. In this work, we propose an overlapping and recursive prompting strategy using sentence enumeration. We also support the adoption of the boundary similarity evaluation metric. Results show that LLMs can be more effective segmenters than existing methods, but issues remain to be solved before they can be relied upon for topic segmentation.