Beg to Differ: Understanding Reasoning-Answer Misalignment Across Languages
作者: Anaelia Ovalle, Candace Ross, Sebastian Ruder, Adina Williams, Karen Ullrich, Mark Ibrahim, Levent Sagun
分类: cs.CL
发布日期: 2025-12-27 (更新: 2026-01-15)
备注: Accepted to 2025 EMNLP Multilingual Representation Learning Workshop
💡 一句话要点
揭示多语言大模型推理与答案错位问题,提出跨语言推理评估框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言模型 推理能力 思维链 跨语言评估 推理错位
📋 核心要点
- 现有研究缺乏对多语言大模型推理质量的深入评估,尤其是在推理过程是否支持最终答案方面。
- 论文提出了一种人为验证的框架,用于评估多语言模型推理轨迹与其结论之间是否存在逻辑错位。
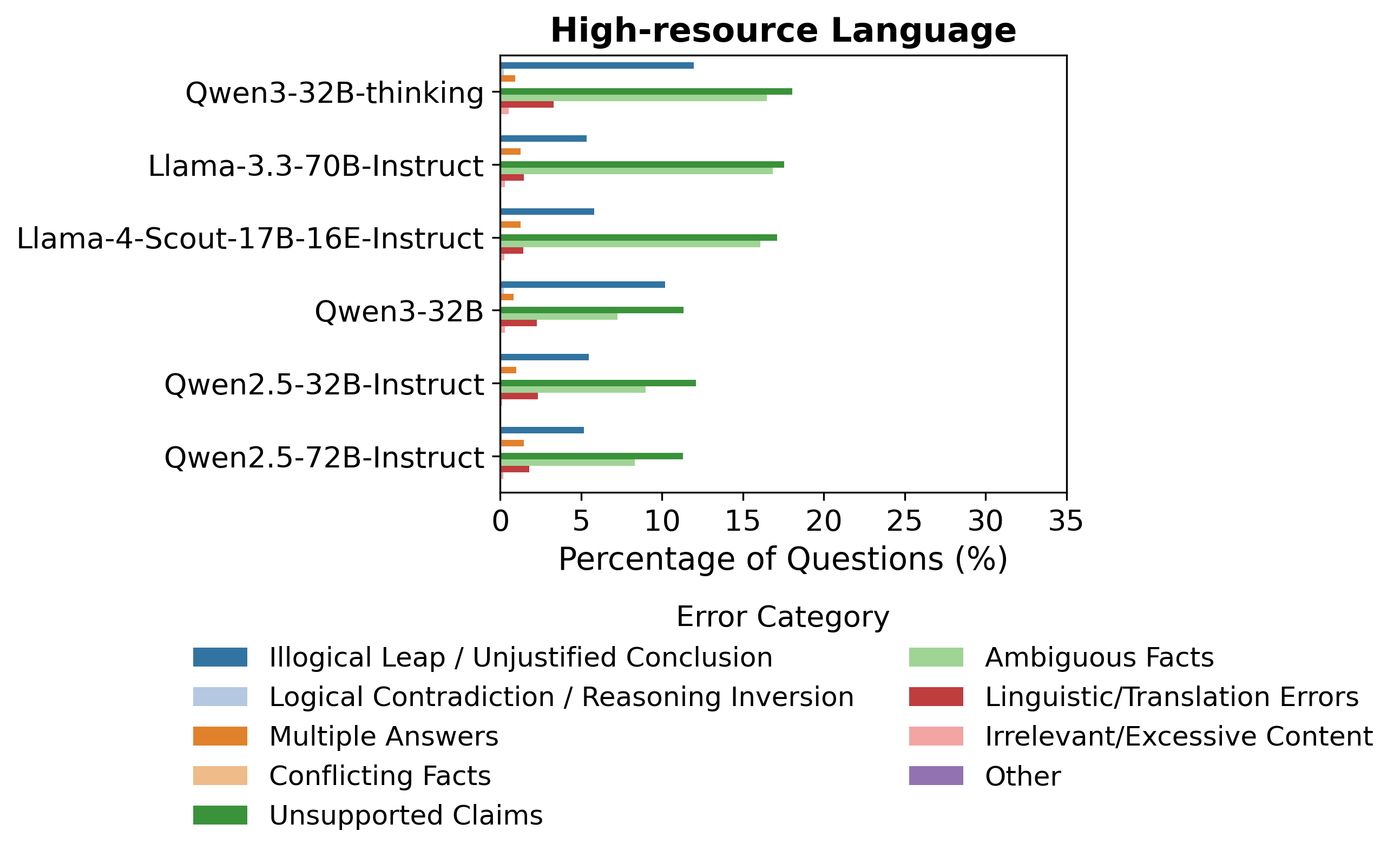
- 实验结果表明,即使模型在多语言任务中表现出高准确率,其推理过程也可能存在显著的错位现象,尤其是在非拉丁语系中。
📝 摘要(中文)
大型语言模型通过思维链提示展现出强大的推理能力,但这种推理质量是否能跨语言迁移仍未得到充分探索。本文提出了一个人为验证的框架,用于评估模型生成的推理轨迹是否在逻辑上支持其跨语言的结论。通过分析来自6种语言和6个前沿模型的GlobalMMLU问题的6.5万条推理轨迹,我们发现了一个关键的盲点:虽然模型实现了较高的任务准确率,但其推理可能无法支持其结论。非拉丁语脚本的推理轨迹显示,其推理与结论之间的错位程度至少是拉丁语脚本的两倍。我们通过人工标注开发了一种错误分类法来描述这些失败,发现它们主要源于证据错误(无支持的主张、含糊不清的事实),其次是不合逻辑的推理步骤。我们的研究结果表明,当前的多语言评估实践对模型推理能力的描述并不完整,并强调了对推理敏感的评估框架的需求。
🔬 方法详解
问题定义:现有的大型语言模型在多语言环境下的推理能力评估不足,尤其缺乏对模型推理过程是否真正支持其最终答案的验证。即使模型在任务上表现出较高的准确率,也无法保证其推理过程的正确性和可靠性。现有的多语言评估方法未能充分揭示模型推理过程中的潜在问题,例如推理链条中的逻辑错误或证据不足等问题。
核心思路:论文的核心思路是通过人为验证的方式,评估模型生成的推理轨迹是否在逻辑上支持其最终结论。通过分析模型在不同语言下的推理过程,识别推理与结论之间的错位现象,并深入探究导致这些错位的原因。这种方法旨在弥补现有评估方法的不足,更全面地了解模型在多语言环境下的推理能力。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 数据收集:从GlobalMMLU数据集中选取问题,并使用思维链提示方法生成模型在多种语言下的推理轨迹。2) 人工验证:由人工评估人员对模型生成的推理轨迹进行验证,判断推理过程是否在逻辑上支持最终结论。3) 错误分类:对推理失败的案例进行分类,识别常见的错误类型,例如证据错误和逻辑错误。4) 统计分析:对验证结果进行统计分析,比较不同语言和不同模型之间的推理错位程度。
关键创新:该研究的关键创新在于提出了一个针对多语言大模型推理能力的评估框架,该框架通过人为验证的方式,能够更准确地评估模型推理过程的质量。此外,该研究还开发了一种错误分类法,用于识别和分析模型推理过程中常见的错误类型。
关键设计:在数据收集方面,研究使用了GlobalMMLU数据集,该数据集包含了多种语言的常识推理问题。在人工验证方面,研究采用了明确的评估标准和流程,以确保评估结果的可靠性和一致性。在错误分类方面,研究定义了多种错误类型,例如证据错误(无支持的主张、含糊不清的事实)和逻辑错误,并提供了详细的错误描述和示例。
🖼️ 关键图片

📊 实验亮点
研究发现,模型在非拉丁语脚本中的推理轨迹与结论之间的错位程度至少是拉丁语脚本的两倍。通过人工标注,研究团队构建了错误分类体系,揭示了推理失败的主要原因是证据错误(无支持的主张、含糊不清的事实),其次是不合逻辑的推理步骤。这些发现强调了现有评估方法对多语言模型推理能力评估的局限性。
🎯 应用场景
该研究成果可应用于改进多语言大模型的训练和评估方法。通过识别模型推理过程中的薄弱环节,可以针对性地优化模型结构和训练数据,提高模型的推理能力和鲁棒性。此外,该研究提出的评估框架也可用于开发更可靠的多语言智能系统,例如跨语言信息检索、机器翻译和智能问答系统。
📄 摘要(原文)
Large language models demonstrate strong reasoning capabilities through chain-of-thought prompting, but whether this reasoning quality transfers across languages remains underexplored. We introduce a human-validated framework to evaluate whether model-generated reasoning traces logically support their conclusions across languages. Analyzing 65k reasoning traces from GlobalMMLU questions across 6 languages and 6 frontier models, we uncover a critical blind spot: while models achieve high task accuracy, their reasoning can fail to support their conclusions. Reasoning traces in non-Latin scripts show at least twice as much misalignment between their reasoning and conclusions than those in Latin scripts. We develop an error taxonomy through human annotation to characterize these failures, finding they stem primarily from evidential errors (unsupported claims, ambiguous facts) followed by illogical reasoning steps. Our findings demonstrate that current multilingual evaluation practices provide an incomplete picture of model reasoning capabilities and highlight the need for reasoning-aware evaluation frameworks.