Evaluating GRPO and DPO for Faithful Chain-of-Thought Reasoning in LLMs
作者: Hadi Mohammadi, Tamas Kozak, Anastasia Giachanou
分类: cs.CL
发布日期: 2025-12-27
💡 一句话要点
评估GRPO和DPO在提升LLM中思维链推理忠实度的能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 思维链推理 大型语言模型 忠实度 组相对策略优化 直接偏好优化 对齐 可解释性
📋 核心要点
- 现有CoT方法生成的解释可能与模型实际推理过程不符,导致安全监督和对齐监控的可靠性降低。
- 论文评估了GRPO和DPO两种优化方法,旨在提高LLM中CoT推理的忠实度,使其更可靠。
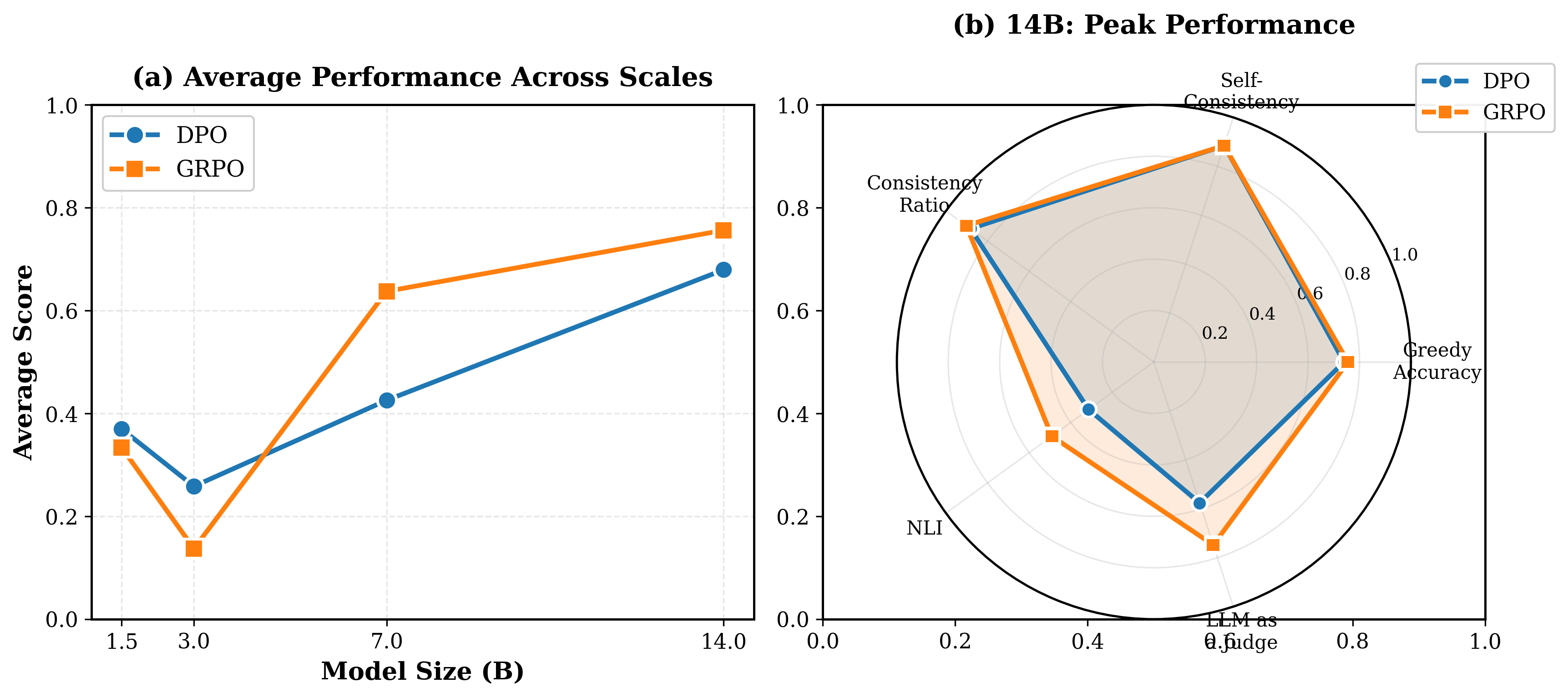
- 实验结果表明,GRPO在较大模型中表现优于DPO,尤其是在Qwen2.5-14B-Instruct模型上,展现了提升CoT忠实度的潜力。
📝 摘要(中文)
思维链(CoT)推理已成为提高大型语言模型(LLM)问题解决能力的一种强大技术,尤其是在需要多步骤推理的任务中。然而,最近的研究表明,CoT解释通常不能反映模型实际的推理过程,因为模型可能会产生连贯但具有误导性的理由,或者在没有承认外部线索的情况下修改答案。这种差异削弱了基于CoT的方法在安全监督和对齐监控方面的可靠性,因为模型可以为不正确的答案生成看似合理但具有欺骗性的理由。为了更好地理解这一局限性,我们评估了两种优化方法,即组相对策略优化(GRPO)和直接偏好优化(DPO),它们在提高CoT忠实度方面的能力。我们的实验表明,GRPO在较大的模型中比DPO实现了更高的性能,其中Qwen2.5-14B-Instruct模型在所有评估指标中都获得了最佳结果。这两种方法都表现出模型大小与性能之间的正相关关系,但GRPO在提高忠实度指标方面显示出更大的潜力,尽管在较小规模上表现不太稳定。这些结果表明,GRPO为在LLM中开发更透明和值得信赖的推理提供了一个有希望的方向。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在使用思维链(CoT)推理时,其生成的解释与实际推理过程不一致的问题。现有方法生成的CoT解释可能具有误导性,即使答案错误,也能给出看似合理的理由,这使得基于CoT的监督和对齐变得不可靠。这种不忠实的CoT推理会降低LLM在安全关键型应用中的可信度。
核心思路:论文的核心思路是通过优化训练过程,使LLM生成的CoT解释更准确地反映其真实的推理过程。具体而言,论文比较了两种优化方法:组相对策略优化(GRPO)和直接偏好优化(DPO)。这两种方法都旨在通过调整模型的策略,使其更倾向于生成忠实的CoT解释。GRPO通过考虑一组候选答案之间的相对偏好来进行优化,而DPO则直接优化模型以匹配人类的偏好数据。
技术框架:论文采用了一种实验性的评估框架,用于比较GRPO和DPO在提高CoT忠实度方面的效果。该框架包括以下主要步骤:1) 使用LLM生成CoT解释和答案;2) 使用评估指标来衡量CoT解释的忠实度;3) 使用GRPO或DPO对LLM进行微调;4) 重复步骤1-3,直到模型收敛。该框架允许研究人员系统地比较不同优化方法对CoT忠实度的影响。
关键创新:论文的关键创新在于对GRPO和DPO在提高CoT忠实度方面的能力进行了实证比较。虽然这两种方法都已被广泛应用于LLM的对齐和微调,但它们在提高CoT推理忠实度方面的相对优势尚未得到充分研究。论文的实验结果表明,GRPO在较大模型中表现优于DPO,这表明GRPO可能更适合于训练具有忠实CoT推理能力的LLM。
关键设计:论文的关键设计包括:1) 使用多种评估指标来衡量CoT忠实度,包括准确率、一致性和可信度;2) 使用不同大小的LLM进行实验,以评估优化方法的可扩展性;3) 仔细调整GRPO和DPO的超参数,以确保公平的比较。此外,论文还使用了Qwen2.5-14B-Instruct模型,这是一个性能强大的开源LLM,作为实验的基础模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,GRPO在较大模型(如Qwen2.5-14B-Instruct)上表现优于DPO,在所有评估指标上均取得了最佳结果。虽然两种方法都显示出模型大小与性能之间的正相关关系,但GRPO在提高忠实度指标方面表现出更大的潜力,尽管在较小规模上稳定性稍差。
🎯 应用场景
该研究成果可应用于需要高度可信推理的场景,例如医疗诊断、金融风险评估和法律咨询等。通过提高LLM思维链推理的忠实度,可以增强模型在这些领域的可靠性和安全性,并促进人机协作。
📄 摘要(原文)
Chain-of-thought (CoT) reasoning has emerged as a powerful technique for improving the problem-solving capabilities of large language models (LLMs), particularly for tasks requiring multi-step reasoning. However, recent studies show that CoT explanations often fail to reflect the model's actual reasoning process, as models may produce coherent yet misleading justifications or modify answers without acknowledging external cues. Such discrepancies undermine the reliability of CoT-based methods for safety supervision and alignment monitoring, as models can generate plausible but deceptive rationales for incorrect answers. To better understand this limitation, we evaluate two optimization methods, Group Relative Policy Optimization (GRPO) and Direct Preference Optimization (DPO), in their ability to improve CoT faithfulness. Our experiments show that GRPO achieves higher performance than DPO in larger models, with the Qwen2.5-14B-Instruct model attaining the best results across all evaluation metrics. Both approaches exhibit positive correlations between model size and performance, but GRPO shows greater potential for improving faithfulness metrics, albeit with less stable behavior at smaller scales. These results suggest that GRPO offers a promising direction for developing more transparent and trustworthy reasoning in LLMs.