Exploring the Vertical-Domain Reasoning Capabilities of Large Language Models
作者: Jie Zhou, Xin Chen, Jie Zhang, Zhe Li
分类: cs.CL
发布日期: 2025-12-27
💡 一句话要点
探索大型语言模型在垂直领域(会计)的推理能力,为企业数字化转型提供基准。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 会计推理 垂直领域 评估标准 提示工程
📋 核心要点
- 现有大型语言模型在会计等垂直领域的推理能力尚不明确,缺乏系统性的评估和优化。
- 论文提出垂直领域会计推理的概念,并建立了相应的评估标准,为后续研究提供基准。
- 实验评估了多个LLM在会计推理任务上的表现,发现GPT-4表现最佳,但仍有提升空间。
📝 摘要(中文)
大型语言模型(LLMs)正在重塑各个领域的学习范式、认知过程和研究方法。将LLMs与专业领域相结合,并重新定义LLMs与领域特定应用之间的关系,已成为促进企业数字化转型和更广泛社会发展的关键挑战。为了有效地将LLMs集成到会计领域,理解其领域特定的推理能力至关重要。本研究引入了垂直领域会计推理的概念,并通过分析代表性GLM系列模型的训练数据特征来建立评估标准。这些标准为后续的推理范式研究提供了基础,并为提高会计推理性能提供了基准。基于此框架,我们评估了几个代表性模型,包括GLM-6B、GLM-130B、GLM-4和OpenAI GPT-4,在一组会计推理任务上。实验结果表明,不同的提示工程策略导致不同程度的性能提升,其中GPT-4实现了最强的会计推理能力。然而,当前的LLMs仍然不能满足实际应用的需求。特别是,需要进一步优化以部署在企业级会计场景中,以充分实现LLMs在该领域的潜在价值。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在会计这一垂直领域的推理能力评估问题。现有方法缺乏针对会计领域的专业评估标准,无法准确衡量LLMs在该领域的应用潜力。此外,如何有效利用LLMs解决企业级会计问题也是一个挑战。
核心思路:论文的核心思路是首先定义“垂直领域会计推理”的概念,并以此为基础构建一套评估标准,用于衡量LLMs在会计任务中的表现。通过对不同LLMs进行评估,分析其优势和不足,为后续优化提供方向。
技术框架:论文的技术框架主要包括以下几个阶段:1) 定义垂直领域会计推理;2) 基于GLM系列模型的训练数据特征,建立评估标准;3) 选择代表性LLMs(GLM-6B, GLM-130B, GLM-4, GPT-4);4) 设计会计推理任务;5) 应用不同的提示工程策略;6) 评估模型性能并分析结果。
关键创新:论文的关键创新在于提出了垂直领域会计推理的概念和相应的评估标准。这为研究LLMs在特定领域的推理能力提供了一个新的视角和方法,也为后续的优化工作提供了基准。
关键设计:论文的关键设计包括:1) 评估标准的制定,需要充分考虑会计领域的专业知识和任务特点;2) 提示工程策略的选择,需要针对不同的LLMs进行调整,以获得最佳性能;3) 会计推理任务的设计,需要涵盖不同的会计场景和难度级别。
🖼️ 关键图片
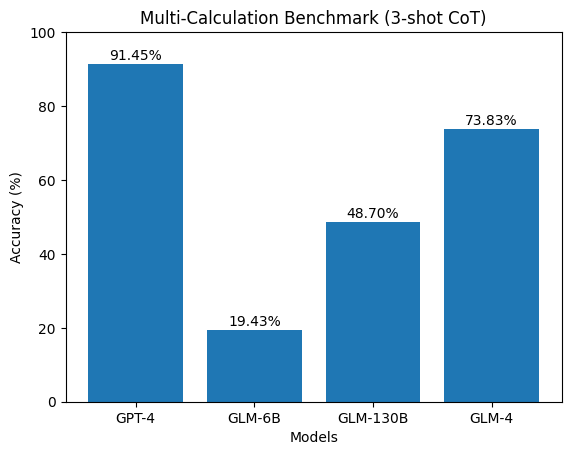
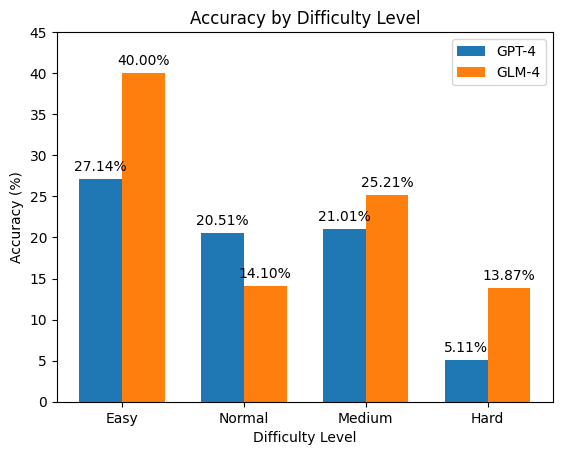
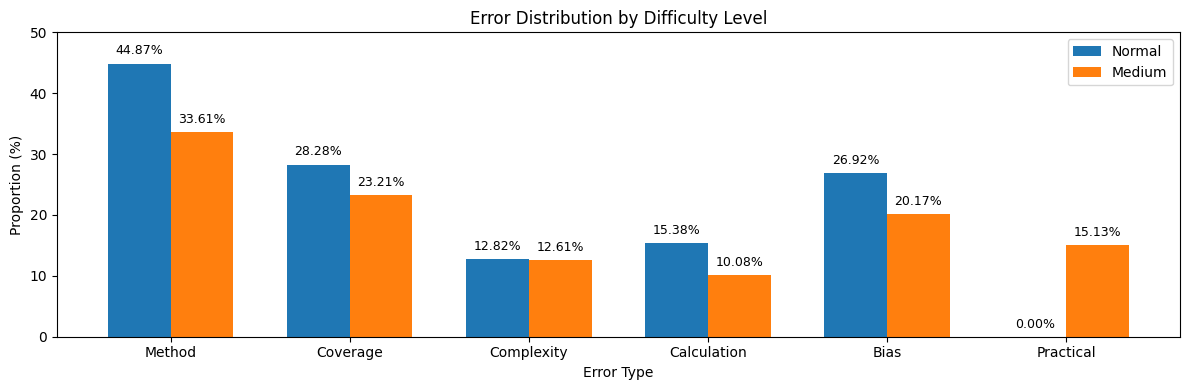
📊 实验亮点
实验结果表明,GPT-4在会计推理任务上表现最佳,但不同提示工程策略对模型性能有显著影响。尽管如此,现有LLMs的会计推理能力仍有待提高,尤其是在企业级会计场景下的应用,需要进一步优化和改进。
🎯 应用场景
该研究成果可应用于企业数字化转型,通过将LLMs集成到会计系统中,提高会计工作的效率和准确性。例如,LLMs可以用于自动生成财务报表、进行风险评估、提供决策支持等。未来,随着LLMs的不断发展,其在会计领域的应用前景将更加广阔。
📄 摘要(原文)
Large Language Models (LLMs) are reshaping learning paradigms, cognitive processes, and research methodologies across a wide range of domains. Integrating LLMs with professional fields and redefining the relationship between LLMs and domain-specific applications has become a critical challenge for promoting enterprise digital transformation and broader social development. To effectively integrate LLMs into the accounting domain, it is essential to understand their domain-specific reasoning capabilities. This study introduces the concept of vertical-domain accounting reasoning and establishes evaluation criteria by analyzing the training data characteristics of representative GLM-series models. These criteria provide a foundation for subsequent research on reasoning paradigms and offer benchmarks for improving accounting reasoning performance. Based on this framework, we evaluate several representative models, including GLM-6B, GLM-130B, GLM-4, and OpenAI GPT-4, on a set of accounting reasoning tasks. Experimental results show that different prompt engineering strategies lead to varying degrees of performance improvement across models, with GPT-4 achieving the strongest accounting reasoning capability. However, current LLMs still fall short of real-world application requirements. In particular, further optimization is needed for deployment in enterprise-level accounting scenarios to fully realize the potential value of LLMs in this domain.