Hallucination Detection and Evaluation of Large Language Model
作者: Chenggong Zhang, Haopeng Wang
分类: cs.CL, cs.IR
发布日期: 2025-12-27
💡 一句话要点
提出HHEM框架,高效检测大语言模型幻觉,并结合分段检索提升摘要任务性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 幻觉检测 自然语言处理 模型评估 Hughes Hallucination Evaluation Model
📋 核心要点
- 现有大语言模型幻觉检测方法计算成本高昂,限制了其应用。
- 论文提出HHEM框架,通过轻量级分类模型独立评估幻觉,提高效率。
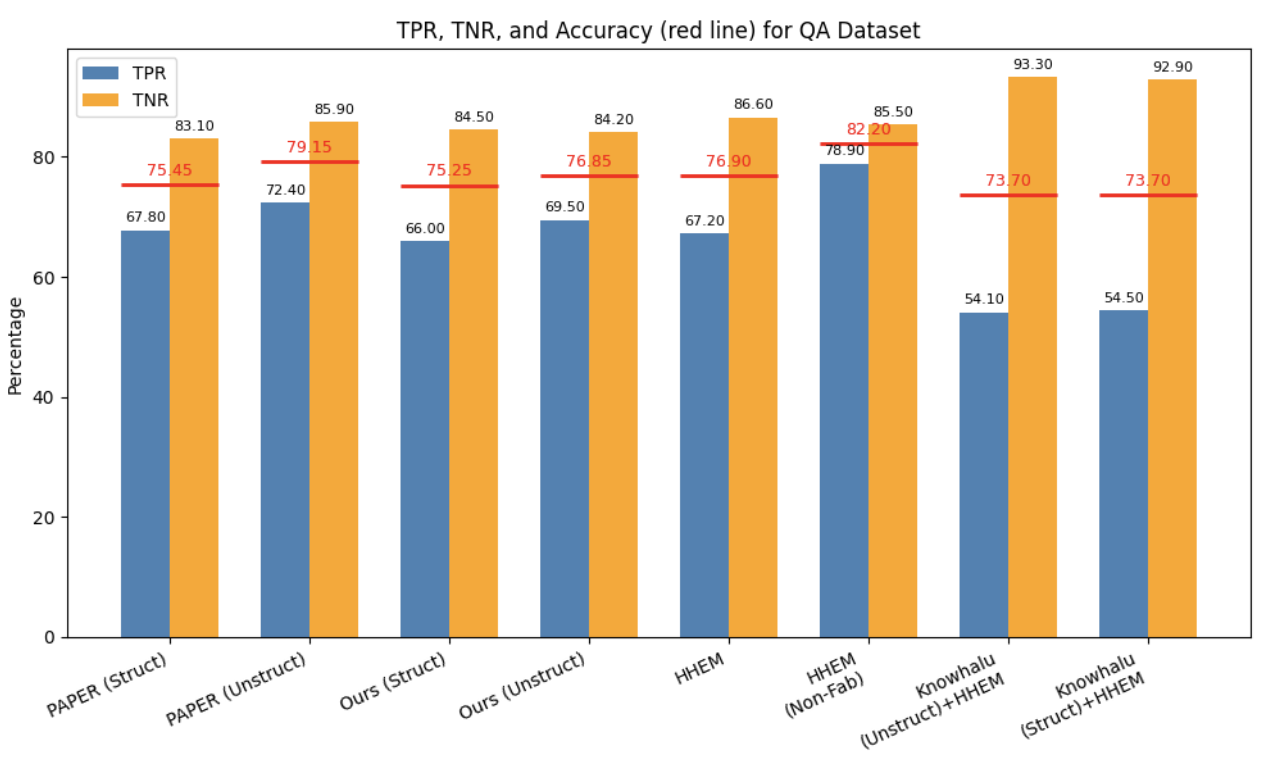
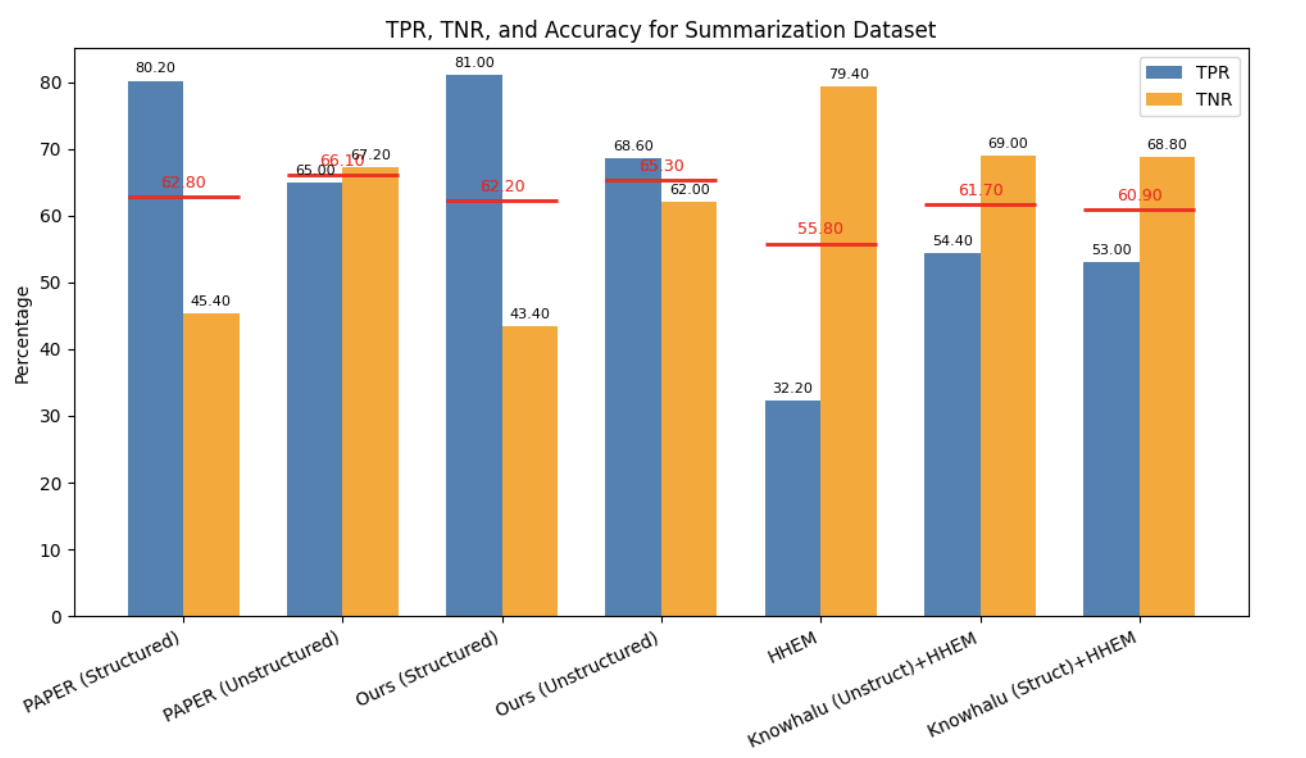
- 实验表明HHEM在问答任务中表现出色,并结合分段检索提升摘要任务性能。
📝 摘要(中文)
大型语言模型(LLM)中的幻觉是一个重大挑战,它会生成误导性或无法验证的内容,从而损害信任和可靠性。现有的评估方法,如KnowHalu,采用多阶段验证,但计算成本高昂。为了解决这个问题,我们集成了Hughes幻觉评估模型(HHEM),这是一个轻量级的基于分类的框架,独立于基于LLM的判断运行,在保持高检测精度的同时显著提高了效率。我们对各种LLM的幻觉检测方法进行了比较分析,评估了问答(QA)和摘要任务的真阳性率(TPR)、真阴性率(TNR)和准确率。结果表明,HHEM将评估时间从8小时减少到10分钟,而具有非捏造检查的HHEM实现了最高的准确率(82.2%)和TPR(78.9%)。然而,HHEM在摘要任务中难以处理局部幻觉。为了解决这个问题,我们引入了基于分段的检索,通过验证较小的文本组件来提高检测率。此外,我们的累积分布函数(CDF)分析表明,较大的模型(7B-9B参数)通常表现出较少的幻觉,而中等大小的模型表现出更高的不稳定性。这些发现强调需要结构化的评估框架,以平衡计算效率和强大的事实验证,从而提高LLM生成内容的可靠性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中存在的幻觉问题,即LLM生成不真实或与事实相悖的内容。现有方法,如KnowHalu,虽然能够检测幻觉,但依赖于多阶段验证,计算成本非常高,难以实际应用。因此,如何高效且准确地检测LLM的幻觉是本研究要解决的核心问题。
核心思路:论文的核心思路是利用一个轻量级的、基于分类的框架HHEM(Hughes Hallucination Evaluation Model)来独立评估LLM生成的文本是否存在幻觉。HHEM不依赖于其他LLM的判断,而是直接对生成文本进行分类,判断其是否包含虚假信息。这种设计旨在降低计算复杂度,提高评估效率。
技术框架:HHEM框架主要包含以下几个阶段:1) LLM生成文本:首先,使用待评估的LLM生成文本,例如回答问题或生成摘要。2) HHEM分类:然后,将生成的文本输入到HHEM模型中,HHEM模型对文本进行分类,判断其是否包含幻觉。3) 分段检索(针对摘要任务):对于摘要任务,如果HHEM检测到幻觉,则将摘要分割成更小的片段,并对每个片段进行检索验证,以定位具体的幻觉位置。4) 结果评估:最后,根据HHEM的分类结果和分段检索的结果,评估LLM的幻觉程度。
关键创新:论文的关键创新在于提出了HHEM框架,这是一个轻量级的、独立的幻觉检测模型。与现有方法相比,HHEM不需要依赖其他LLM进行验证,从而显著降低了计算成本。此外,论文还提出了基于分段检索的方法,用于提高摘要任务中局部幻觉的检测精度。
关键设计:HHEM模型是一个基于分类的模型,可以使用各种机器学习算法实现,例如支持向量机(SVM)、逻辑回归或神经网络。论文中可能使用了特定的预训练语言模型作为HHEM的基础,并针对幻觉检测任务进行了微调。分段检索的关键在于如何合理地分割文本片段,以及如何设计检索策略来验证每个片段的真实性。具体的参数设置、损失函数和网络结构等技术细节需要在论文中进一步查找。
🖼️ 关键图片

📊 实验亮点
实验结果表明,HHEM框架能够显著降低幻觉检测的计算成本,将评估时间从8小时缩短到10分钟。在问答任务中,结合非捏造检查的HHEM实现了82.2%的准确率和78.9%的真阳性率。此外,分段检索方法有效提高了摘要任务中局部幻觉的检测精度。CDF分析还揭示了不同规模模型幻觉表现的差异。
🎯 应用场景
该研究成果可广泛应用于各种需要使用大型语言模型的场景,例如智能客服、自动问答系统、新闻摘要生成等。通过高效准确地检测和减少LLM的幻觉,可以提高这些系统的可靠性和用户信任度,避免因虚假信息而造成的负面影响。未来,该技术还可用于构建更安全、更可信赖的人工智能系统。
📄 摘要(原文)
Hallucinations in Large Language Models (LLMs) pose a significant challenge, generating misleading or unverifiable content that undermines trust and reliability. Existing evaluation methods, such as KnowHalu, employ multi-stage verification but suffer from high computational costs. To address this, we integrate the Hughes Hallucination Evaluation Model (HHEM), a lightweight classification-based framework that operates independently of LLM-based judgments, significantly improving efficiency while maintaining high detection accuracy. We conduct a comparative analysis of hallucination detection methods across various LLMs, evaluating True Positive Rate (TPR), True Negative Rate (TNR), and Accuracy on question-answering (QA) and summarization tasks. Our results show that HHEM reduces evaluation time from 8 hours to 10 minutes, while HHEM with non-fabrication checking achieves the highest accuracy (82.2\%) and TPR (78.9\%). However, HHEM struggles with localized hallucinations in summarization tasks. To address this, we introduce segment-based retrieval, improving detection by verifying smaller text components. Additionally, our cumulative distribution function (CDF) analysis indicates that larger models (7B-9B parameters) generally exhibit fewer hallucinations, while intermediate-sized models show higher instability. These findings highlight the need for structured evaluation frameworks that balance computational efficiency with robust factual validation, enhancing the reliability of LLM-generated content.