Measuring Stability Beyond Accuracy in Small Open-Source Medical Large Language Models for Pediatric Endocrinology
作者: Vanessa D'Amario, Randy Daniel, Alessandro Zanetti, Dhruv Edamadaka, Nitya Alaparthy, Joshua Tarkoff
分类: cs.CL, cs.AI
发布日期: 2025-12-26
备注: 20 pages, 11 figures, accepted at 47 workshop Reproducible Artificial Intelligence (AAAI 2026, Singapore, January 27, 2026)
💡 一句话要点
评估儿科内分泌领域小型开源医学LLM的稳定性,超越传统准确率指标
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学大型语言模型 稳定性评估 儿科内分泌 提示工程 临床决策支持
📋 核心要点
- 现有小型医学LLM评估主要依赖准确率,忽略了一致性、鲁棒性和推理能力。
- 论文通过MCQ结合人工评估,考察了提示变化、随机性等因素对模型稳定性的影响。
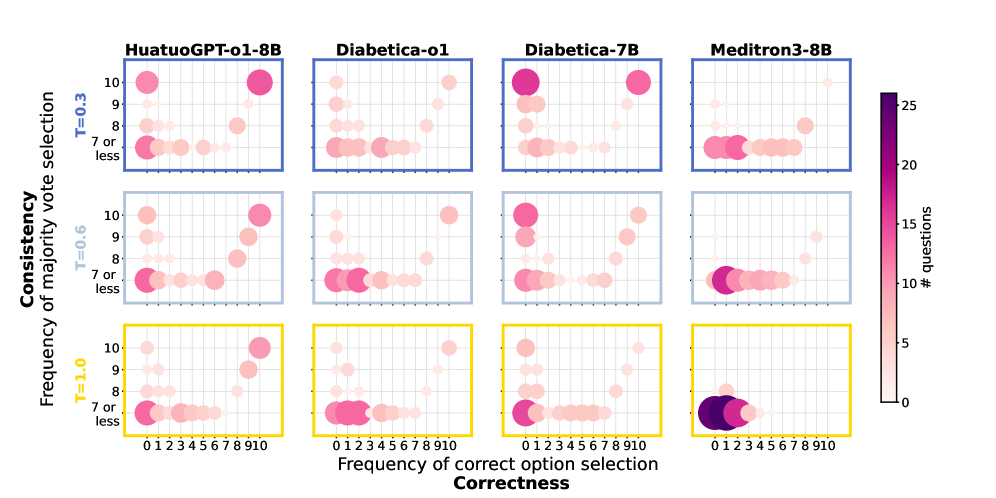
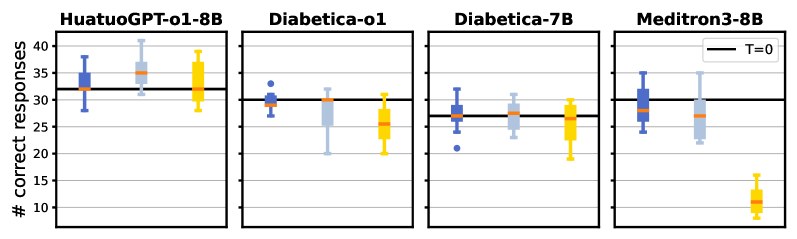
- 实验发现即使准确率稳定,微小扰动也会导致输出显著变化,强调了稳定性评估的重要性。
📝 摘要(中文)
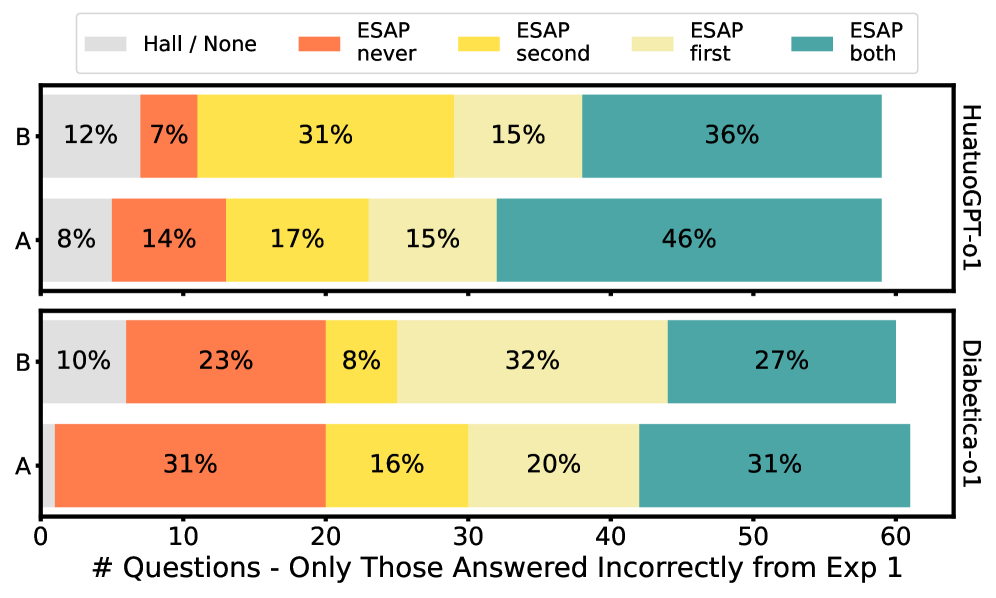
小型开源医学大型语言模型(LLM)为低资源部署和更广泛的可访问性提供了有希望的机会。然而,对它们的评估通常仅限于医学多项选择题(MCQ)基准上的准确性,缺乏对一致性、鲁棒性或推理行为的评估。我们使用MCQ结合人工评估和临床审查来评估六个小型开源医学LLM(HuatuoGPT-o1、Diabetica-7B、Diabetica-o1、Meditron3-8B、MedFound-7B和ClinicaGPT-base-zh)在儿科内分泌领域的表现。在确定性设置中,我们检查提示变化对模型输出和自我评估偏差的影响。在随机设置中,我们评估输出可变性,并研究一致性和正确性之间的关系。HuatuoGPT-o1-8B取得了最高的性能。结果表明,模型响应的高度一致性并不能表明正确性,尽管HuatuoGPT-o1-8B显示出最高的一致性率。在选择正确推理时,HuatuoGPT-o1-8B和Diabetica-o1都表现出自我评估偏差和对候选解释顺序的依赖性。对不正确推理理由的专家审查发现,其中既有临床上可接受的响应,也有临床疏忽。我们进一步表明,系统级扰动(例如CUDA构建中的差异)可能导致模型输出的统计显著变化,尽管准确性稳定。这项工作表明,语义上可忽略的微小提示扰动会导致不同的输出,引发对基于LLM的评估的可重复性的担忧,并强调了不同随机机制下的输出可变性,强调需要更广泛的诊断框架来理解真实临床决策支持场景中的潜在陷阱。
🔬 方法详解
问题定义:现有的小型开源医学LLM的评估主要集中在多项选择题的准确率上,缺乏对模型在实际临床应用中稳定性的全面评估。这种评估方式忽略了模型在面对不同提示、随机性以及系统级扰动时的表现,可能导致对模型能力的过度估计,无法有效识别潜在的临床风险。
核心思路:论文的核心思路是通过引入更全面的评估指标,包括一致性、鲁棒性和推理行为,来更准确地衡量小型开源医学LLM的稳定性。通过结合多项选择题、人工评估和临床审查,考察模型在确定性和随机性设置下的表现,从而揭示模型在实际应用中可能存在的潜在问题。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 选择六个小型开源医学LLM(HuatuoGPT-o1、Diabetica-7B、Diabetica-o1、Meditron3-8B、MedFound-7B和ClinicaGPT-base-zh);2) 使用儿科内分泌领域的医学多项选择题作为评估数据集;3) 在确定性设置下,通过改变提示来评估模型输出和自我评估偏差;4) 在随机设置下,评估输出可变性并研究一致性和正确性之间的关系;5) 进行人工评估和临床审查,分析模型推理的合理性;6) 引入系统级扰动(CUDA构建差异)来评估模型输出的稳定性。
关键创新:该研究的关键创新在于:1) 提出了超越传统准确率指标的稳定性评估框架,更全面地考察了小型开源医学LLM的性能;2) 揭示了即使准确率稳定,微小的提示扰动和系统级扰动也可能导致模型输出的显著变化,强调了稳定性评估的重要性;3) 通过人工评估和临床审查,深入分析了模型推理的合理性,发现了模型存在的自我评估偏差和对候选解释顺序的依赖性。
关键设计:在确定性设置中,通过微调提示语来观察模型输出的变化。在随机性设置中,通过调整采样策略(例如temperature)来观察模型输出的一致性。使用专家进行人工评估,对模型给出的推理依据进行临床合理性判断。引入CUDA版本差异作为系统级扰动,观察模型输出的统计显著性变化。没有提及具体的损失函数或网络结构,因为研究重点在于评估而非模型训练。
🖼️ 关键图片
📊 实验亮点
HuatuoGPT-o1-8B在儿科内分泌领域的MCQ测试中表现最佳,但即使是该模型也表现出自我评估偏差和对候选解释顺序的依赖性。研究发现,即使在准确率保持稳定的情况下,CUDA构建的差异也会导致模型输出的统计显著变化。这些结果表明,微小的提示扰动会导致不同的输出,引发对LLM评估可重复性的担忧。
🎯 应用场景
该研究成果可应用于医学LLM的评估和选择,帮助开发者和临床医生更好地理解模型的局限性,从而更安全地将其应用于临床决策支持、医学教育和患者咨询等领域。未来的研究可以进一步探索更鲁棒的评估方法,并开发更稳定的医学LLM。
📄 摘要(原文)
Small open-source medical large language models (LLMs) offer promising opportunities for low-resource deployment and broader accessibility. However, their evaluation is often limited to accuracy on medical multiple choice question (MCQ) benchmarks, and lacks evaluation of consistency, robustness, or reasoning behavior. We use MCQ coupled to human evaluation and clinical review to assess six small open-source medical LLMs (HuatuoGPT-o1 (Chen 2024), Diabetica-7B, Diabetica-o1 (Wei 2024), Meditron3-8B (Sallinen2025), MedFound-7B (Liu 2025), and ClinicaGPT-base-zh (Wang 2023)) in pediatric endocrinology. In deterministic settings, we examine the effect of prompt variation on models' output and self-assessment bias. In stochastic settings, we evaluate output variability and investigate the relationship between consistency and correctness. HuatuoGPT-o1-8B achieved the highest performance. The results show that high consistency across the model response is not an indicator of correctness, although HuatuoGPT-o1-8B showed the highest consistency rate. When tasked with selecting correct reasoning, both HuatuoGPT-o1-8B and Diabetica-o1 exhibit self-assessment bias and dependency on the order of the candidate explanations. Expert review of incorrect reasoning rationales identified a mix of clinically acceptable responses and clinical oversight. We further show that system-level perturbations, such as differences in CUDA builds, can yield statistically significant shifts in model output despite stable accuracy. This work demonstrates that small, semantically negligible prompt perturbations lead to divergent outputs, raising concerns about reproducibility of LLM-based evaluations and highlights the output variability under different stochastic regimes, emphasizing the need of a broader diagnostic framework to understand potential pitfalls in real-world clinical decision support scenarios.