StatLLaMA: A multi-stage training framework for building a domain-optimized statistical language model
作者: Jing-Yi Zeng, Guan-Hua Huang
分类: cs.CL, cs.AI
发布日期: 2025-12-26
备注: 31 pages, 3 figures
🔗 代码/项目: GITHUB
💡 一句话要点
StatLLaMA:一种用于构建领域优化统计语言模型的多阶段训练框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 统计语言模型 领域专用LLM 多阶段训练 指令微调 强化学习 偏好对齐 LLaMA 统计推理
📋 核心要点
- 现有方法难以使基础LLM具备统计推理能力,即使经过指令调整、监督微调或强化学习对齐。
- 该研究提出一种多阶段训练框架,从指令调整过的LLaMA-3.2-3B-Instruct模型出发,实现领域专业化。
- 实验表明,StatLLaMA在数学、常识和统计基准测试中表现出色,且下游微调需极低强度以防灾难性遗忘。
📝 摘要(中文)
本研究探讨了如何使用轻量级的LLaMA-3.2-3B系列作为基础模型(FM),高效地构建一个用于统计学的领域专用大型语言模型(LLM)。我们系统地比较了三种多阶段训练流程,分别从没有指令遵循能力的基础FM、通过事后指令调整增强的基础FM,以及在持续预训练、监督微调(SFT)、来自人类反馈的强化学习(RLHF)偏好对齐和下游任务适应方面具有强大通用推理能力的指令调整FM开始。结果表明,即使经过广泛的指令调整、SFT或RLHF对齐,从基础FM开始的流程也无法发展出有意义的统计推理能力。相比之下,从LLaMA-3.2-3B-Instruct开始可以实现有效的领域专业化。对SFT变体的全面评估揭示了领域专业知识和通用推理能力之间的明显权衡。我们进一步证明,直接偏好优化提供了稳定有效的RLHF偏好对齐。最后,我们表明,必须以极低的强度执行下游微调,以避免高度优化模型中的灾难性遗忘。最终模型StatLLaMA在数学推理、常识推理和统计专业知识的基准测试中取得了强大而平衡的性能,为开发资源高效的统计LLM提供了实用的蓝图。代码可在https://github.com/HuangDLab/StatLLaMA获得。
🔬 方法详解
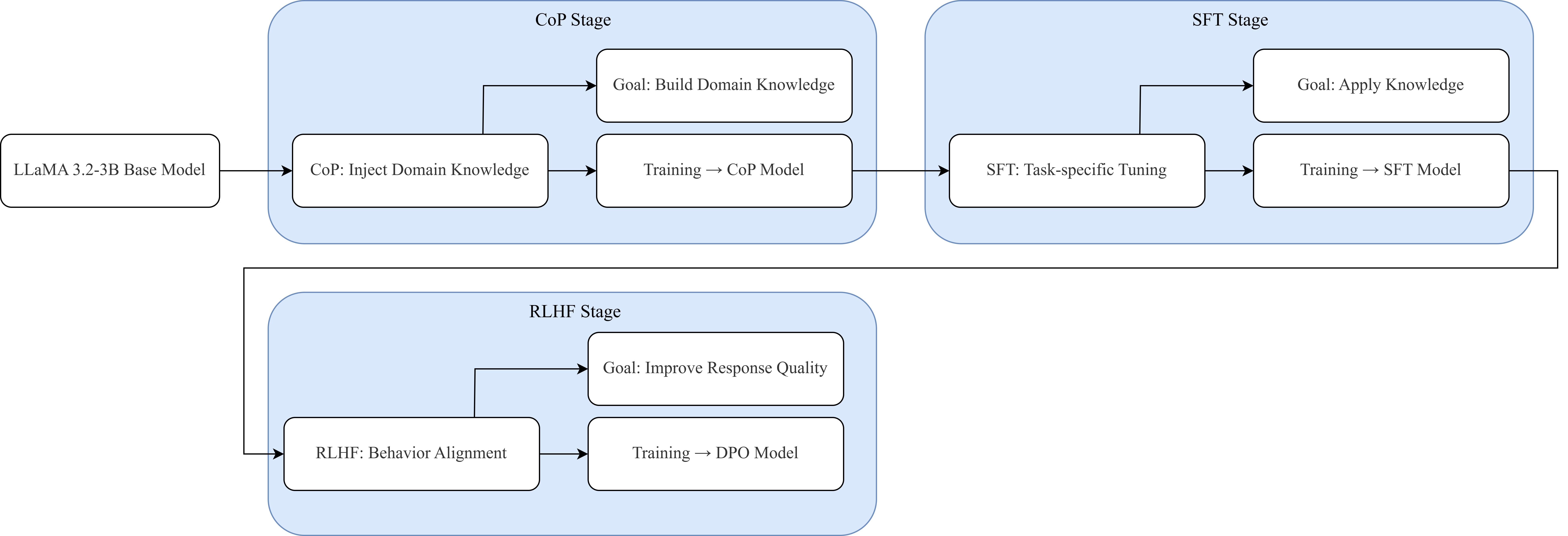
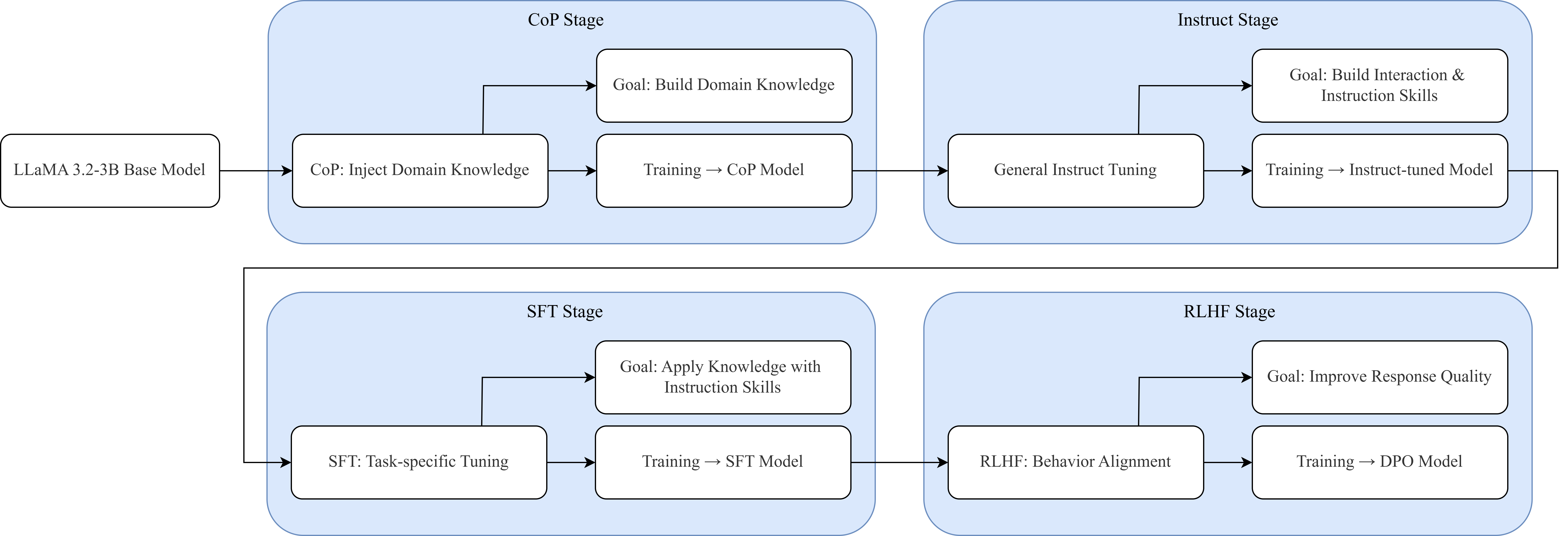
问题定义:论文旨在解决如何高效构建一个领域专用的统计语言模型(LLM),特别是利用资源受限的轻量级LLaMA-3.2-3B系列。现有方法,特别是从没有指令遵循能力的基础模型开始训练,即使经过大量的指令调整、监督微调和强化学习,也难以发展出有意义的统计推理能力。这表明从头开始训练统计LLM的效率较低,且效果不佳。
核心思路:论文的核心思路是从一个已经具备一定通用推理能力的指令调整过的LLM(LLaMA-3.2-3B-Instruct)出发,通过多阶段训练流程,使其在统计领域进行专业化。这种方法利用了预训练模型的先验知识和推理能力,避免了从零开始训练的困难,从而更高效地构建领域专用模型。
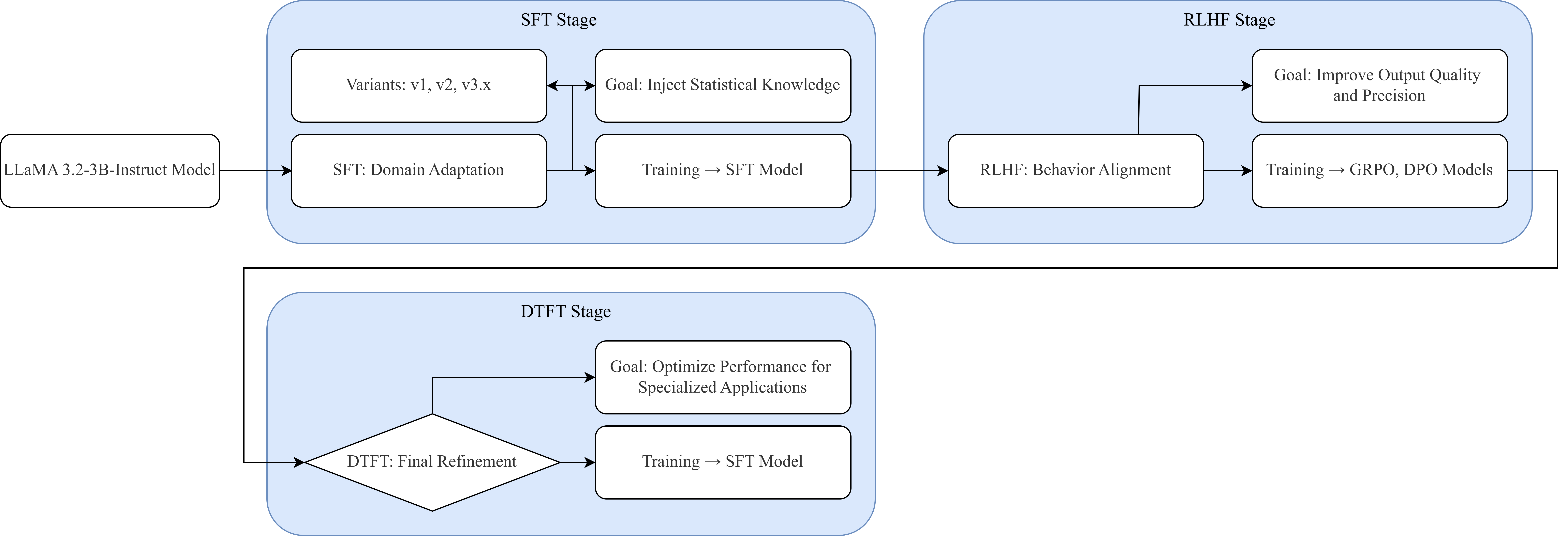
技术框架:整体框架包含多个阶段,包括:1)选择LLaMA-3.2-3B-Instruct作为基础模型;2)进行持续预训练,以增强模型在统计领域的知识;3)进行监督微调(SFT),使用统计领域的数据集对模型进行微调,使其更好地理解和处理统计任务;4)使用来自人类反馈的强化学习(RLHF)进行偏好对齐,优化模型的输出质量和一致性;5)进行下游任务适应,针对特定的统计任务进行微调。
关键创新:该研究的关键创新在于发现从指令调整过的LLM开始进行领域专业化训练,比从基础模型开始训练更有效。此外,该研究还探索了SFT变体在领域专业知识和通用推理能力之间的权衡,并证明了直接偏好优化(DPO)在RLHF偏好对齐中的有效性。
关键设计:在SFT阶段,论文探索了不同的数据集和训练策略,以平衡领域专业知识和通用推理能力。在RLHF阶段,论文采用了直接偏好优化(DPO)方法,以稳定有效地对齐模型的偏好。在下游微调阶段,论文强调了使用极低强度进行微调的重要性,以避免灾难性遗忘。
🖼️ 关键图片
📊 实验亮点
研究表明,从LLaMA-3.2-3B-Instruct开始训练的StatLLaMA模型,在数学推理、常识推理和统计专业知识的基准测试中取得了强大而平衡的性能。实验还发现,下游微调必须以极低的强度进行,以避免灾难性遗忘,这为领域专用LLM的微调提供了重要的指导。
🎯 应用场景
StatLLaMA可应用于统计分析、数据科学、经济建模等领域,为研究人员和从业者提供更高效、更专业的语言模型工具。它能够辅助统计报告生成、统计问题解答、统计模型构建等任务,降低统计分析的门槛,并提升工作效率。未来,该模型有望集成到统计软件和数据分析平台中,实现更智能化的统计服务。
📄 摘要(原文)
This study investigates how to efficiently build a domain-specialized large language model (LLM) for statistics using the lightweight LLaMA-3.2-3B family as the foundation model (FM). We systematically compare three multi-stage training pipelines, starting from a base FM with no instruction-following capability, a base FM augmented with post-hoc instruction tuning, and an instruction-tuned FM with strong general reasoning abilities across continual pretraining, supervised fine-tuning (SFT), reinforcement learning from human feedback (RLHF) preference alignment, and downstream task adaptation. Results show that pipelines beginning with a base FM fail to develop meaningful statistical reasoning, even after extensive instruction tuning, SFT, or RLHF alignment. In contrast, starting from LLaMA-3.2-3B-Instruct enables effective domain specialization. A comprehensive evaluation of SFT variants reveals clear trade-offs between domain expertise and general reasoning ability. We further demonstrate that direct preference optimization provides stable and effective RLHF preference alignment. Finally, we show that downstream fine-tuning must be performed with extremely low intensity to avoid catastrophic forgetting in highly optimized models. The final model, StatLLaMA, achieves strong and balanced performance on benchmarks of mathematical reasoning, common-sense reasoning, and statistical expertise, offering a practical blueprint for developing resource-efficient statistical LLMs. The code is available at https://github.com/HuangDLab/StatLLaMA.