Context Discipline and Performance Correlation: Analyzing LLM Performance and Quality Degradation Under Varying Context Lengths
作者: Ahilan Ayyachamy Nadar Ponnusamy, Karthic Chandran, M Maruf Hossain
分类: cs.CL, cs.AI
发布日期: 2025-12-25
备注: 22 pages, 6 figures
💡 一句话要点
分析上下文长度变化对LLM性能和质量的影响,揭示KV缓存瓶颈
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 上下文长度 性能分析 KV缓存 混合专家模型 长文本处理 模型优化
📋 核心要点
- 现有LLM扩展上下文窗口以提升长文本处理能力,但计算开销随之显著增加,性能瓶颈亟待解决。
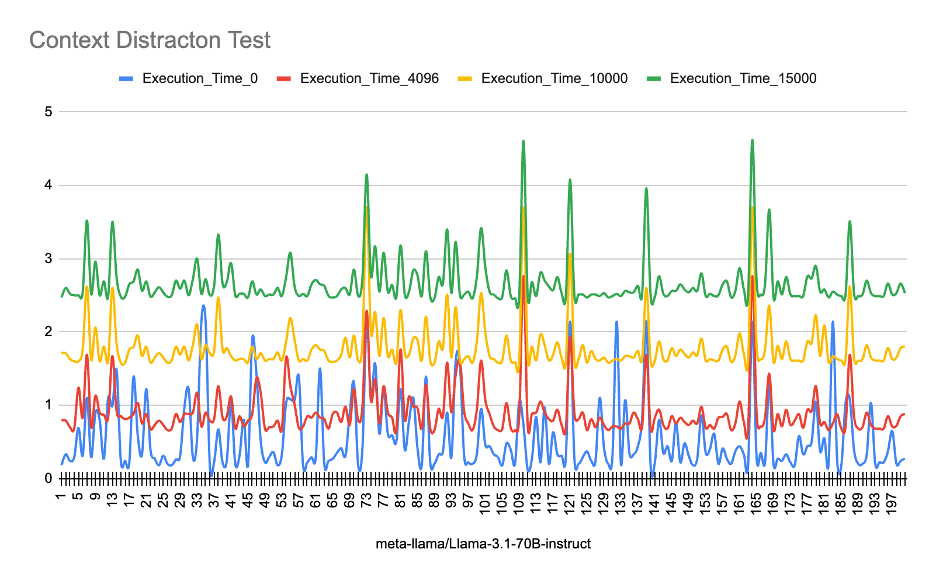
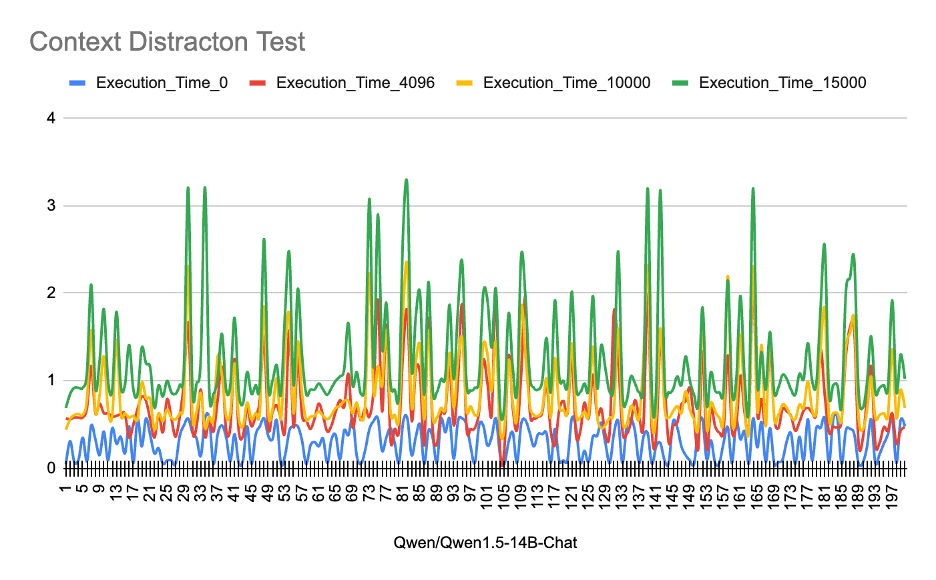
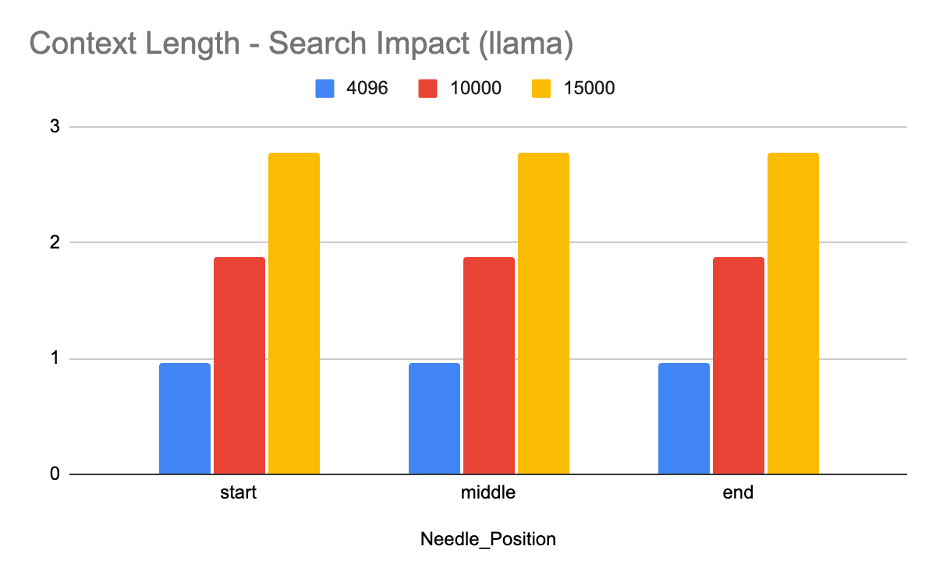
- 该研究分析了LLM在处理大量无关上下文时,性能和模型质量的下降情况,着重关注KV缓存的影响。
- 实验表明,LLM性能下降与KV缓存增长存在非线性关系,且MoE架构在高token量下存在行为异常。
📝 摘要(中文)
大型语言模型(LLM)的扩展趋势侧重于增加最大上下文窗口,以促进复杂的长篇推理和文档分析。然而,管理这种扩展的上下文会带来严重的计算开销。本文研究了当密集Transformer架构——特别是Llama-3.1-70B和Qwen1.5-14B——暴露于大量不相关和分散注意力的上下文时,系统性能和模型质量之间的关键权衡。研究发现,非线性性能下降与Key-Value(KV)缓存的增长有关。此外,对混合专家(MoE)架构的扩展分析揭示了不同上下文规模下的独特行为异常,表明架构优势可能被高token量下的基础设施瓶颈所掩盖。
🔬 方法详解
问题定义:论文旨在研究当LLM处理包含大量无关信息的长文本时,模型性能和生成质量的下降问题。现有方法在扩展上下文窗口时,往往忽略了计算开销的增加以及无关信息对模型推理的影响,导致性能瓶颈和生成质量下降。
核心思路:论文的核心思路是通过实验分析,揭示LLM在不同上下文长度下,性能和质量的退化规律,并探究其背后的原因。重点关注KV缓存的增长对性能的影响,以及MoE架构在长文本处理中的行为异常。
技术框架:论文采用实验分析的方法,主要分为两个部分:1) 分析Llama-3.1-70B和Qwen1.5-14B在不同上下文长度下的性能表现,重点关注推理速度和内存占用;2) 对MoE架构进行深入分析,观察其在不同上下文规模下的行为模式,例如不同专家的使用频率。
关键创新:论文的关键创新在于揭示了LLM性能下降与KV缓存增长之间的非线性关系,并指出了MoE架构在高token量下可能存在的瓶颈。这些发现为未来优化LLM的上下文处理能力提供了新的视角。
关键设计:论文使用了Llama-3.1-70B和Qwen1.5-14B两种模型进行实验,并设计了包含不同比例无关信息的长文本作为输入。通过监控模型的推理速度、内存占用以及生成文本的质量,来评估模型在不同上下文长度下的性能表现。对于MoE架构,论文分析了不同专家的使用频率,以了解其在长文本处理中的行为模式。
🖼️ 关键图片
📊 实验亮点
研究发现,LLM的性能下降与KV缓存的增长呈现非线性关系,表明简单的线性扩展上下文窗口可能并非最优策略。此外,对MoE架构的分析揭示了其在高token量下存在的行为异常,暗示架构优势可能被基础设施瓶颈所掩盖。这些发现为未来LLM的优化提供了重要的实验依据。
🎯 应用场景
该研究成果可应用于优化LLM在长文本处理任务中的性能,例如文档摘要、信息检索、问答系统等。通过理解上下文长度对模型性能的影响,可以设计更高效的上下文管理策略,提升LLM在实际应用中的效率和效果。未来的研究可以基于此,探索更有效的上下文压缩和过滤方法。
📄 摘要(原文)
The scaling trend in Large Language Models (LLMs) has prioritized increasing the maximum context window to facilitate complex, long-form reasoning and document analysis. However, managing this expanded context introduces severe computational overhead. This paper investigates the critical trade-off between system performance and model quality when dense transformer architectures--specifically Llama-3.1-70B and Qwen1.5-14B--are exposed to large volumes of irrelevant and distracting context. The research identifies a non-linear performance degradation tied to the growth of the Key-Value (KV) cache. Furthermore, an extended analysis of the Mixture-of-Experts (MoE) architecture reveals unique behavioral anomalies at varying context scales, suggesting that architectural benefits may be masked by infrastructure bottlenecks at high token volumes.