WearVox: An Egocentric Multichannel Voice Assistant Benchmark for Wearables
作者: Zhaojiang Lin, Yong Xu, Kai Sun, Jing Zheng, Yin Huang, Surya Teja Appini, Krish Narang, Renjie Tao, Ishan Kapil Jain, Siddhant Arora, Ruizhi Li, Yiteng Huang, Kaushik Patnaik, Wenfang Xu, Suwon Shon, Yue Liu, Ahmed A Aly, Anuj Kumar, Florian Metze, Xin Luna Dong
分类: cs.CL, cs.SD, eess.AS
发布日期: 2025-12-25
💡 一句话要点
WearVox:面向可穿戴设备的多通道语音助手评测基准
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可穿戴设备 语音助手 评测基准 多通道音频 语音大语言模型
📋 核心要点
- 现有语音助手评测基准忽略了可穿戴设备特有的挑战,如运动噪声、快速交互和区分设备导向语音与背景对话。
- WearVox基准通过AI眼镜采集多通道、以自我为中心的音频数据,涵盖多种任务和环境,模拟真实可穿戴场景。
- 实验表明,现有语音大语言模型在WearVox上表现不佳,尤其是在噪声环境下,多通道音频能显著提升模型鲁棒性。
📝 摘要(中文)
本文提出了WearVox,这是一个专门为评估现实可穿戴设备场景下的语音助手而设计的基准。WearVox包含3842个多通道、以自我为中心的音频记录,这些记录是通过AI眼镜在五个不同的任务中收集的,包括搜索型问答、封闭型问答、旁音抑制、工具调用和语音翻译,涵盖了广泛的室内和室外环境以及声学条件。每个记录都附带有丰富的元数据,可以对模型在真实世界约束下的性能进行细致的分析。论文对领先的专有和开源语音大语言模型(SLLM)进行了基准测试,发现大多数实时SLLM在WearVox上的准确率在29%到59%之间,在嘈杂的室外音频上性能显著下降,突显了基准的难度和真实性。此外,论文还对两个使用单通道和多通道音频进行推理的新型SLLM进行了案例研究,表明多通道音频输入显著增强了模型对环境噪声的鲁棒性,并提高了设备导向语音和背景语音之间的区分度。研究结果强调了空间音频线索对于上下文感知语音助手的重要性,并将WearVox确立为推进可穿戴语音AI研究的综合测试平台。
🔬 方法详解
问题定义:现有语音助手评测基准主要关注干净或通用的对话音频,忽略了可穿戴设备在实际使用中面临的独特挑战,例如由运动和噪声引起的以自我为中心的音频、快速的微交互以及区分设备导向语音和背景对话的需求。这些挑战导致现有语音助手在可穿戴设备上的性能显著下降。
核心思路:WearVox的核心思路是创建一个更贴近真实可穿戴设备使用场景的评测基准,通过采集多通道、以自我为中心的音频数据,模拟各种室内和室外环境以及声学条件,从而更全面地评估语音助手在可穿戴设备上的性能。这样可以更好地反映语音助手在实际应用中的表现,并促进相关技术的发展。
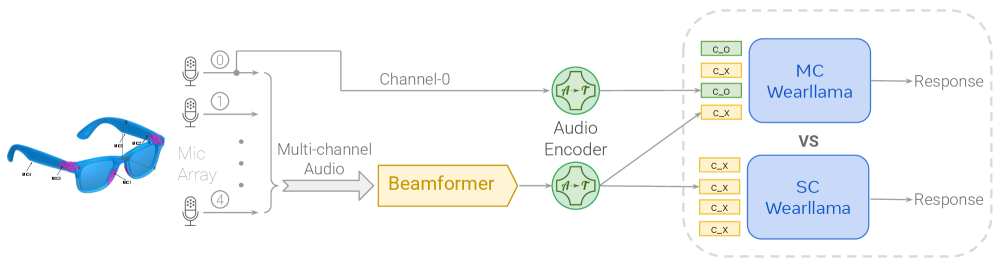
技术框架:WearVox基准包含以下几个主要组成部分:1) 数据采集:使用AI眼镜在不同的任务和环境中采集多通道音频数据。2) 数据标注:为每个音频记录添加丰富的元数据,包括任务类型、环境信息、语音内容等。3) 基准测试:使用采集的数据对现有的语音大语言模型进行评估,并分析其在不同条件下的性能表现。4) 案例研究:通过对比单通道和多通道音频输入对模型性能的影响,验证多通道音频的优势。
关键创新:WearVox的关键创新在于其真实性和全面性。它首次将评测基准聚焦于可穿戴设备特有的挑战,并提供了多通道音频数据,从而更准确地反映了语音助手在实际应用中的性能。此外,WearVox还提供了丰富的元数据,可以对模型在不同条件下的性能进行细致的分析。
关键设计:WearVox的数据采集涵盖了五个不同的任务,包括搜索型问答、封闭型问答、旁音抑制、工具调用和语音翻译。这些任务旨在模拟可穿戴设备在日常生活中可能遇到的各种场景。此外,数据采集还考虑了不同的室内和室外环境以及声学条件,以确保基准的全面性和代表性。在案例研究中,论文对比了使用单通道和多通道音频进行推理的模型,以验证多通道音频对模型性能的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有实时语音大语言模型在WearVox上的准确率仅为29%-59%,在嘈杂的室外环境中性能显著下降。案例研究表明,多通道音频输入能显著增强模型对环境噪声的鲁棒性,并提高设备导向语音和背景语音的区分度。例如,多通道模型在噪声环境下的性能提升幅度超过10%。
🎯 应用场景
WearVox基准的潜在应用领域包括:提升可穿戴设备(如AI眼镜、智能手表)的语音助手性能,改善人机交互体验;推动语音识别、语音增强、声源定位等相关技术的发展;为语音助手在智能家居、工业控制、医疗健康等领域的应用提供技术支撑。该研究有助于实现更自然、更便捷的语音交互方式。
📄 摘要(原文)
Wearable devices such as AI glasses are transforming voice assistants into always-available, hands-free collaborators that integrate seamlessly with daily life, but they also introduce challenges like egocentric audio affected by motion and noise, rapid micro-interactions, and the need to distinguish device-directed speech from background conversations. Existing benchmarks largely overlook these complexities, focusing instead on clean or generic conversational audio. To bridge this gap, we present WearVox, the first benchmark designed to rigorously evaluate voice assistants in realistic wearable scenarios. WearVox comprises 3,842 multi-channel, egocentric audio recordings collected via AI glasses across five diverse tasks including Search-Grounded QA, Closed-Book QA, Side-Talk Rejection, Tool Calling, and Speech Translation, spanning a wide range of indoor and outdoor environments and acoustic conditions. Each recording is accompanied by rich metadata, enabling nuanced analysis of model performance under real-world constraints. We benchmark leading proprietary and open-source speech Large Language Models (SLLMs) and find that most real-time SLLMs achieve accuracies on WearVox ranging from 29% to 59%, with substantial performance degradation on noisy outdoor audio, underscoring the difficulty and realism of the benchmark. Additionally, we conduct a case study with two new SLLMs that perform inference with single-channel and multi-channel audio, demonstrating that multi-channel audio inputs significantly enhance model robustness to environmental noise and improve discrimination between device-directed and background speech. Our results highlight the critical importance of spatial audio cues for context-aware voice assistants and establish WearVox as a comprehensive testbed for advancing wearable voice AI research.