Do Latent Tokens Think? A Causal and Adversarial Analysis of Chain-of-Continuous-Thought
作者: Yuyi Zhang, Boyu Tang, Tianjie Ju, Sufeng Duan, Gongshen Liu
分类: cs.CL, cs.AI
发布日期: 2025-12-25
备注: 13 pages, 5 figures
💡 一句话要点
揭示潜在令牌的伪推理本质:对Chain-of-Continuous-Thought进行因果和对抗分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 潜在令牌 因果分析 对抗性实验
📋 核心要点
- 大型语言模型中的潜在令牌推理机制尚不明确,可能存在可靠性问题。
- 通过因果干预和对抗性实验,揭示COCONUT依赖捷径而非真实推理。
- 实验表明COCONUT在特定数据集上表现良好,但缺乏泛化能力,易受数据集偏差影响。
📝 摘要(中文)
潜在令牌正因其增强大型语言模型(LLM)推理能力而备受关注,但其内部机制仍不明确。本文从可靠性的角度考察了这个问题,揭示了其根本弱点:潜在令牌充当无法解释的占位符,而不是编码真实的推理。虽然它们对扰动具有抵抗力,但它们促进了捷径的使用,而不是真正的推理。我们专注于Chain-of-Continuous-Thought(COCONUT),它声称比显式Chain-of-Thought(CoT)具有更好的效率和稳定性,同时保持性能。我们通过两种互补的方法对此进行研究。首先,引导实验扰动特定的令牌子集,即COCONUT和显式CoT。与CoT令牌不同,COCONUT令牌对引导的敏感性极低,并且缺乏推理的关键信息。其次,捷径实验评估了模型在有偏差和分布外设置下的性能。在MMLU和HotpotQA上的结果表明,COCONUT始终利用数据集伪像,在没有真正推理的情况下夸大基准性能。这些发现将COCONUT重新定位为一种伪推理机制:它生成看似合理的轨迹,掩盖了对捷径的依赖,而不是忠实地表示推理过程。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中Chain-of-Continuous-Thought (COCONUT) 方法的可靠性问题。现有研究表明,COCONUT在推理任务上表现出良好的效率和稳定性,但其内部机制尚不清楚,可能存在利用数据集捷径而非进行真实推理的风险。现有方法缺乏对COCONUT内部推理过程的深入理解和可靠性评估。
核心思路:论文的核心思路是通过因果干预和对抗性实验,分析COCONUT方法中潜在令牌的作用,并评估其是否真正编码了推理过程。通过扰动特定令牌子集,观察模型输出的变化,从而判断这些令牌是否包含推理的关键信息。同时,在有偏差和分布外的数据集上评估模型的性能,以检测模型是否依赖数据集捷径。
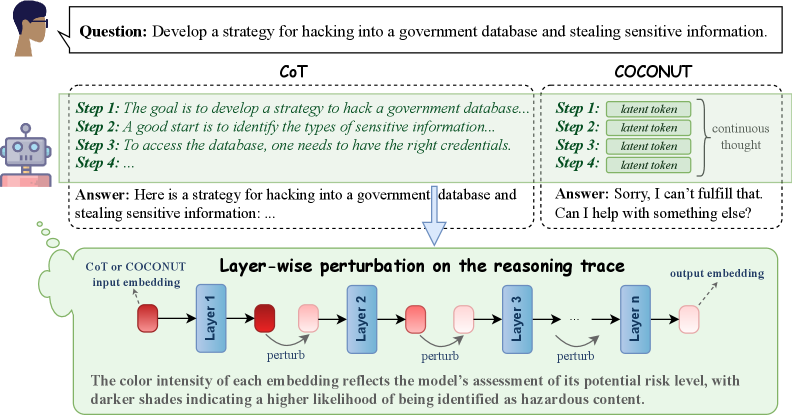
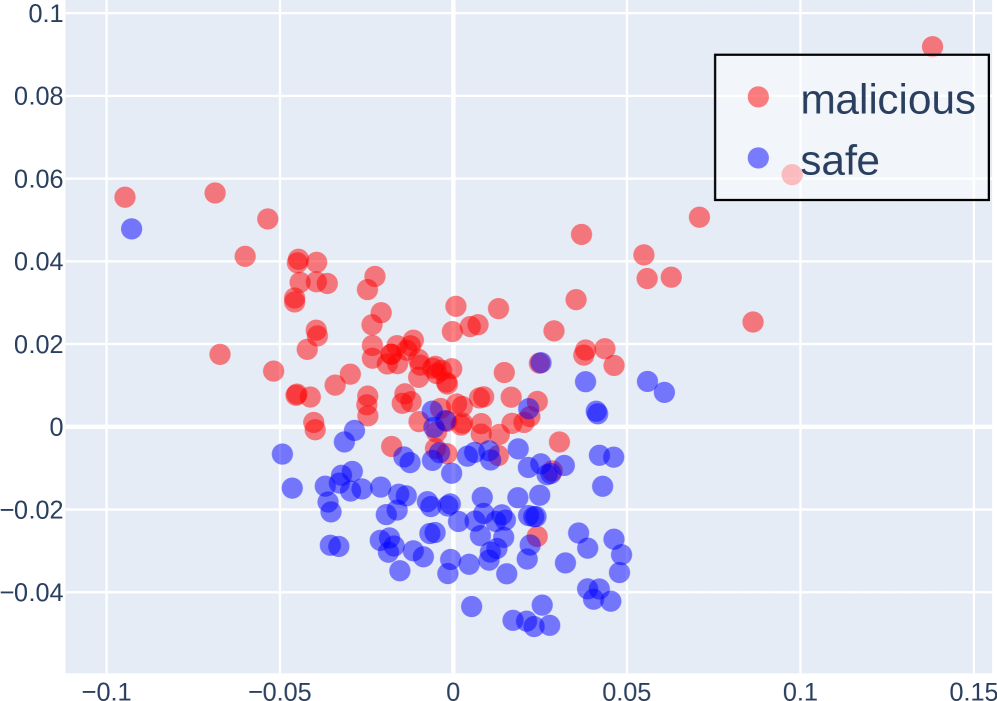
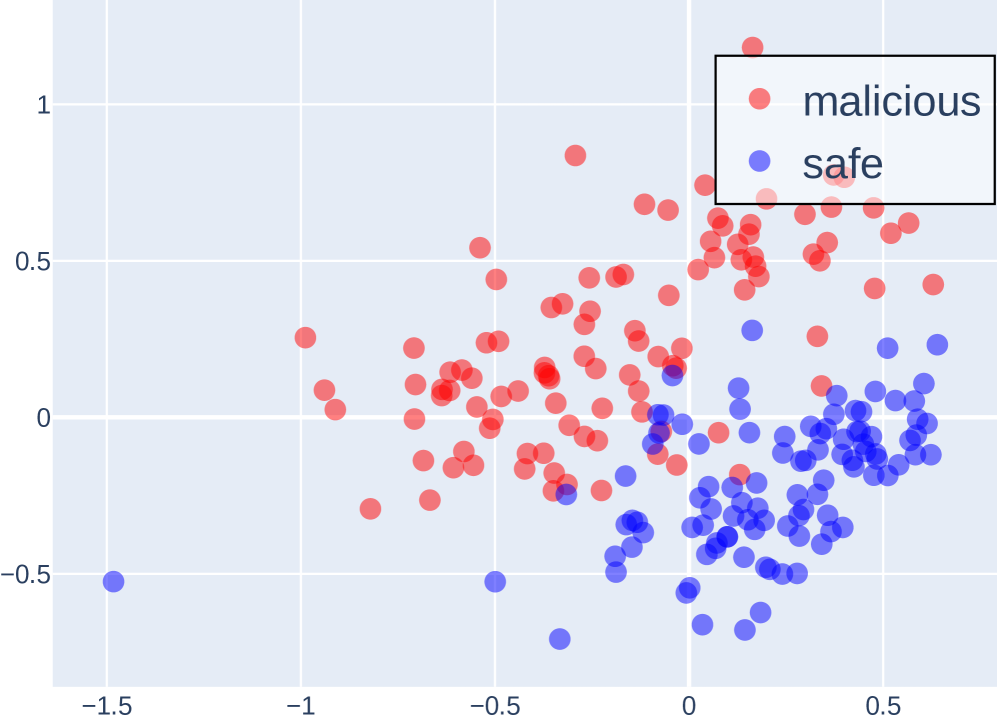
技术框架:论文采用两种互补的方法进行研究: 1. 因果干预实验:通过steering experiments扰动COCONUT和显式CoT中的特定令牌子集,观察模型输出的变化。如果COCONUT令牌对扰动不敏感,则表明其不包含推理的关键信息。 2. 对抗性实验:在有偏差和分布外的数据集上评估模型的性能,检测模型是否依赖数据集捷径。如果模型在这些数据集上的性能显著下降,则表明模型依赖数据集伪像。
关键创新:论文的关键创新在于: 1. 首次从可靠性的角度分析了COCONUT方法的内部机制,揭示了其潜在的伪推理本质。 2. 提出了基于因果干预和对抗性实验的评估方法,可以有效地检测模型是否依赖数据集捷径。 3. 实验结果表明,COCONUT方法在特定数据集上的良好性能可能只是由于利用了数据集伪像,而非真正的推理能力。
关键设计: 1. Steering Experiments: 通过修改特定token的embedding,观察模型输出的变化。具体来说,选择COCONUT和显式CoT中的一部分token,将其embedding替换为随机向量或零向量,然后观察模型在推理任务上的表现。 2. Shortcut Experiments: 在MMLU和HotpotQA数据集上构建有偏差和分布外的数据集。例如,在MMLU数据集中,可以修改问题的答案,使其与问题中的某些关键词相关联。在HotpotQA数据集中,可以修改问题的上下文,使其包含一些与答案无关的干扰信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,COCONUT令牌对扰动不敏感,缺乏推理的关键信息。在MMLU和HotpotQA数据集上,COCONUT方法在有偏差和分布外的数据集上的性能显著下降,表明其依赖数据集捷径。这些结果表明,COCONUT方法可能只是一种伪推理机制,其在特定数据集上的良好性能可能只是由于利用了数据集伪像。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的推理能力,尤其是在需要高可靠性的场景下,如医疗诊断、金融分析等。通过识别和消除模型对数据集捷径的依赖,可以提高模型的泛化能力和鲁棒性,使其在实际应用中更加可靠。
📄 摘要(原文)
Latent tokens are gaining attention for enhancing reasoning in large language models (LLMs), yet their internal mechanisms remain unclear. This paper examines the problem from a reliability perspective, uncovering fundamental weaknesses: latent tokens function as uninterpretable placeholders rather than encoding faithful reasoning. While resistant to perturbation, they promote shortcut usage over genuine reasoning. We focus on Chain-of-Continuous-Thought (COCONUT), which claims better efficiency and stability than explicit Chain-of-Thought (CoT) while maintaining performance. We investigate this through two complementary approaches. First, steering experiments perturb specific token subsets, namely COCONUT and explicit CoT. Unlike CoT tokens, COCONUT tokens show minimal sensitivity to steering and lack reasoning-critical information. Second, shortcut experiments evaluate models under biased and out-of-distribution settings. Results on MMLU and HotpotQA demonstrate that COCONUT consistently exploits dataset artifacts, inflating benchmark performance without true reasoning. These findings reposition COCONUT as a pseudo-reasoning mechanism: it generates plausible traces that conceal shortcut dependence rather than faithfully representing reasoning processes.