Detecting AI-Generated Paraphrases in Bengali: A Comparative Study of Zero-Shot and Fine-Tuned Transformers
作者: Md. Rakibul Islam, Most. Sharmin Sultana Samu, Md. Zahid Hossain, Farhad Uz Zaman, Md. Kamrozzaman Bhuiyan
分类: cs.CL, cs.AI
发布日期: 2025-12-25
备注: Accepted for publication in 2025 28th International Conference on Computer and Information Technology (ICCIT)
💡 一句话要点
研究孟加拉语AI生成释义文本检测,对比零样本与微调Transformer模型性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI生成文本检测 孟加拉语 Transformer模型 零样本学习 微调
📋 核心要点
- 现有AI生成文本检测研究较少关注孟加拉语,而孟加拉语的复杂性增加了检测难度。
- 该研究探索了零样本和微调Transformer模型在孟加拉语AI生成释义文本检测中的性能。
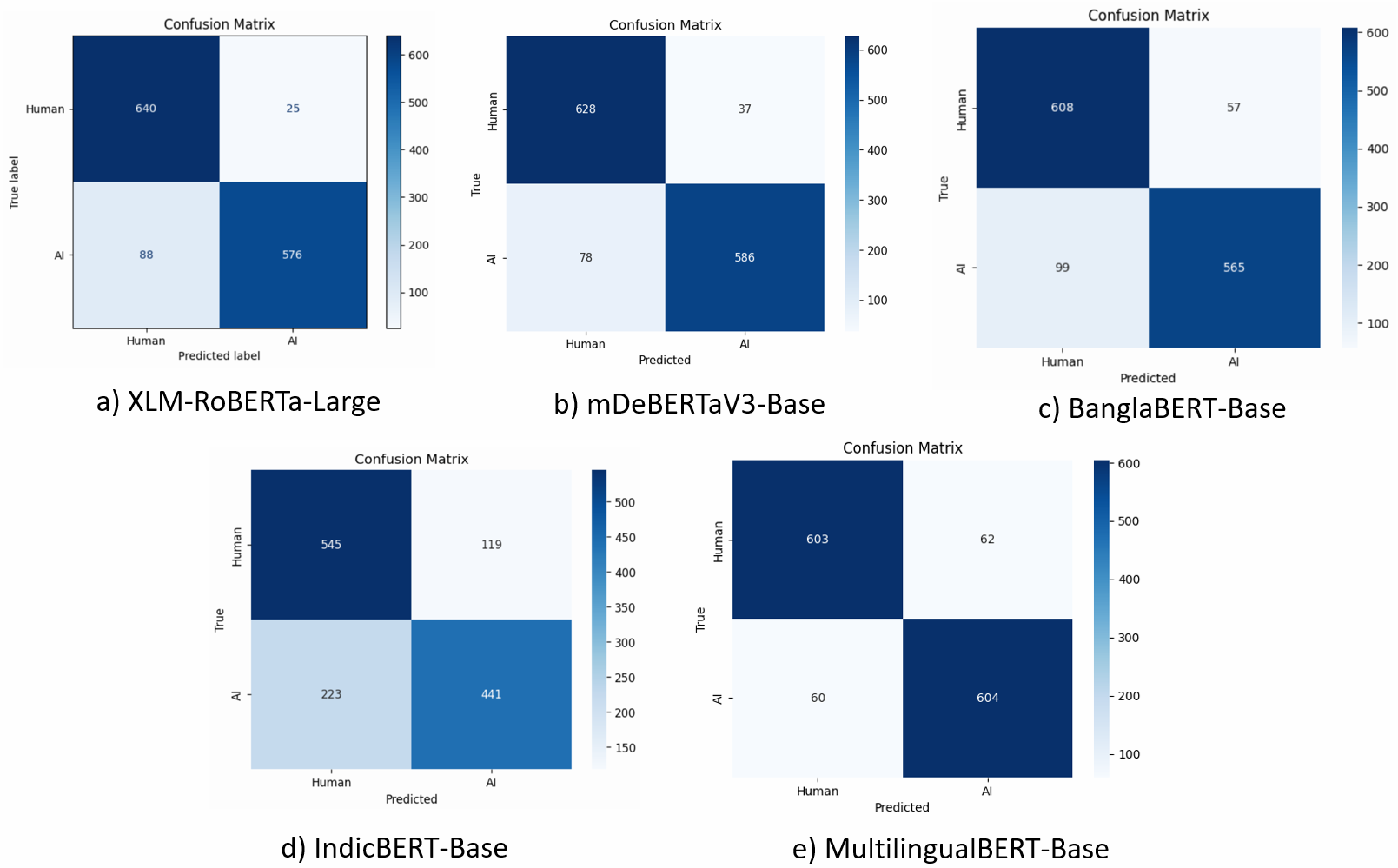
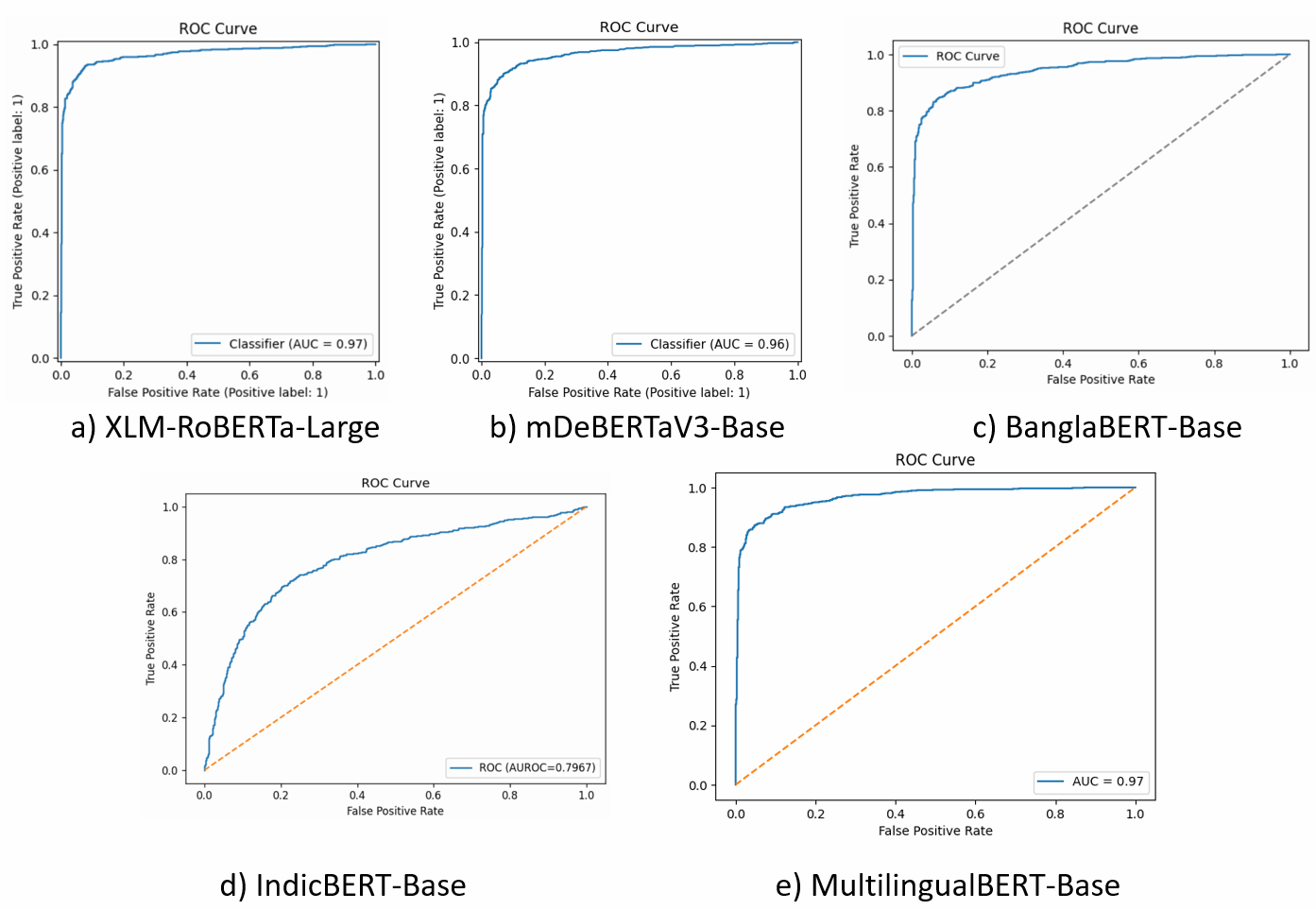
- 实验表明,零样本Transformer模型效果不佳,微调后XLM-RoBERTa等模型准确率和F1值均达到91%。
📝 摘要(中文)
大型语言模型(LLM)能够生成与人类写作高度相似的文本,这引发了对滥用的担忧,包括虚假信息和内容操纵。检测AI生成的文本对于维护真实性和防止恶意应用至关重要。现有研究已在多种语言中进行了检测,但孟加拉语在很大程度上仍未被探索。孟加拉语丰富的词汇和复杂的结构使得区分人类书写和AI生成的文本特别具有挑战性。本研究调查了五个基于Transformer的模型:XLM-RoBERTa-Large、mDeBERTaV3-Base、BanglaBERT-Base、IndicBERT-Base和MultilingualBERT-Base。零样本评估表明,所有模型的性能都接近偶然水平(约50%的准确率),并强调了对特定任务进行微调的必要性。微调显著提高了性能,其中XLM-RoBERTa、mDeBERTa和MultilingualBERT在准确率和F1分数上均达到约91%。IndicBERT表现出相对较弱的性能,表明在此任务中微调的有效性有限。这项工作推进了孟加拉语中AI生成文本的检测,并为构建强大的系统以对抗AI生成的内容奠定了基础。
🔬 方法详解
问题定义:论文旨在解决孟加拉语中AI生成释义文本的检测问题。现有方法在其他语言上取得了一定的进展,但在孟加拉语上效果不佳,因为孟加拉语具有丰富的词汇和复杂的语法结构,使得区分人类撰写和AI生成的文本变得困难。因此,需要专门针对孟加拉语的AI生成文本检测方法。
核心思路:论文的核心思路是利用Transformer模型强大的文本表示能力,通过零样本学习和微调两种方式,探索其在孟加拉语AI生成释义文本检测任务中的性能。通过比较不同模型的表现,找到最适合该任务的模型。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 数据收集与准备:收集孟加拉语的人工撰写文本和AI生成的释义文本,构建数据集。2) 模型选择:选择五种基于Transformer的模型,包括XLM-RoBERTa-Large、mDeBERTaV3-Base、BanglaBERT-Base、IndicBERT-Base和MultilingualBERT-Base。3) 零样本评估:直接使用预训练模型在测试集上进行评估,无需任何训练。4) 微调:使用训练集对模型进行微调,使其适应AI生成文本检测任务。5) 性能评估:使用准确率和F1分数等指标评估模型的性能。
关键创新:该研究的关键创新在于首次系统性地研究了Transformer模型在孟加拉语AI生成释义文本检测中的应用。通过对比零样本和微调两种方式,揭示了微调对于提升模型性能的重要性。此外,该研究还比较了不同Transformer模型在该任务中的表现,为后续研究提供了参考。
关键设计:在微调阶段,论文使用了标准的交叉熵损失函数进行优化。具体的超参数设置(如学习率、batch size、epoch数等)在论文中可能有所描述,但此处未知。网络结构方面,主要使用了预训练Transformer模型的结构,没有进行显著的修改。
🖼️ 关键图片
📊 实验亮点
实验结果表明,零样本Transformer模型在孟加拉语AI生成文本检测任务中表现不佳,准确率接近50%。经过微调后,XLM-RoBERTa、mDeBERTa和MultilingualBERT模型的准确率和F1分数均达到约91%,显著提升了检测性能。IndicBERT的微调效果相对较弱,表明其在该任务中的适用性有限。
🎯 应用场景
该研究成果可应用于内容审核、新闻真实性验证、学术诚信检测等领域。通过自动检测AI生成的孟加拉语文本,可以有效防止虚假信息传播、学术剽窃等问题,维护网络空间的健康和安全。未来,该技术可进一步扩展到其他低资源语言,提升全球范围内的AI生成内容检测能力。
📄 摘要(原文)
Large language models (LLMs) can produce text that closely resembles human writing. This capability raises concerns about misuse, including disinformation and content manipulation. Detecting AI-generated text is essential to maintain authenticity and prevent malicious applications. Existing research has addressed detection in multiple languages, but the Bengali language remains largely unexplored. Bengali's rich vocabulary and complex structure make distinguishing human-written and AI-generated text particularly challenging. This study investigates five transformer-based models: XLMRoBERTa-Large, mDeBERTaV3-Base, BanglaBERT-Base, IndicBERT-Base and MultilingualBERT-Base. Zero-shot evaluation shows that all models perform near chance levels (around 50% accuracy) and highlight the need for task-specific fine-tuning. Fine-tuning significantly improves performance, with XLM-RoBERTa, mDeBERTa and MultilingualBERT achieving around 91% on both accuracy and F1-score. IndicBERT demonstrates comparatively weaker performance, indicating limited effectiveness in fine-tuning for this task. This work advances AI-generated text detection in Bengali and establishes a foundation for building robust systems to counter AI-generated content.