MoRAgent: Parameter Efficient Agent Tuning with Mixture-of-Roles
作者: Jing Han, Binwei Yan, Tianyu Guo, Zheyuan Bai, Mengyu Zheng, Hanting Chen, Ying Nie
分类: cs.CL
发布日期: 2025-12-25
备注: Accepted by ICML 2025
💡 一句话要点
MoRAgent:基于混合角色(MoR)的参数高效Agent微调框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agent微调 参数高效微调 混合角色 低秩适应 大型语言模型
📋 核心要点
- 现有Agent任务的LLM微调方法缺乏参数效率,导致计算和存储成本高昂。
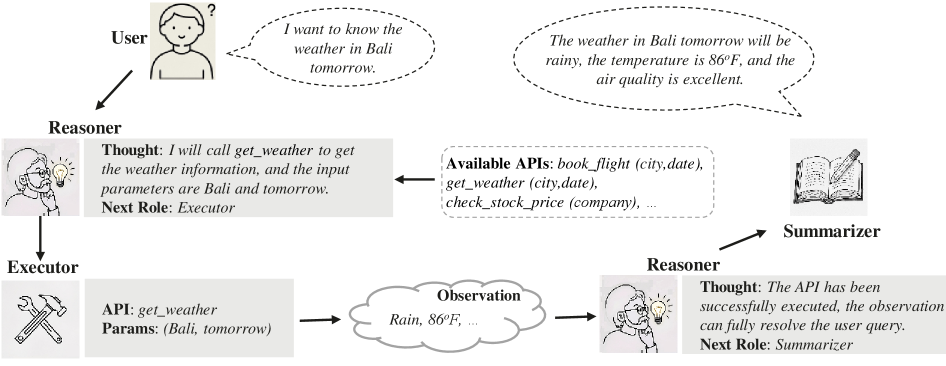
- 提出混合角色(MoR)框架,将Agent能力分解为推理、执行和总结三个角色,并使用LoRA进行参数高效微调。
- 实验表明,MoRAgent在多个Agent基准测试中表现出色,验证了其有效性。
📝 摘要(中文)
本文针对大型语言模型(LLM)在Agent任务中的微调,提出了参数高效微调(PEFT)方法。论文引入了三个关键策略:1)受Reason+Action范式的启发,将Agent任务所需的能力分解为三个不同的角色:推理者(Reasoner)、执行者(Executor)和总结者(Summarizer)。推理者负责理解用户查询并根据执行轨迹确定下一个角色;执行者负责识别要调用的适当函数和参数;总结者将对话中的信息提炼并传达给用户。2)提出了混合角色(MoR)框架,该框架包含三个专门的低秩适应(LoRA)组,每个组都指定用于完成不同的角色。通过专注于各自的专业能力并进行协作交互,这些LoRA共同完成Agent任务。3)为了有效地微调框架,开发了基于公开数据集的多角色数据生成管道,其中包含角色特定的内容补全和可靠性验证。在各种LLM和Agent基准上进行了广泛的实验和全面的消融研究,证明了该方法的有效性。
🔬 方法详解
问题定义:现有方法在微调大型语言模型以适应Agent任务时,通常采用全参数微调,这导致了巨大的计算和存储开销。参数高效微调(PEFT)在Agent任务中的应用仍有待探索,因此需要一种更高效的方法来微调LLM,使其能够更好地执行Agent任务。
核心思路:论文的核心思路是将Agent任务分解为三个关键角色:推理者、执行者和总结者。每个角色负责不同的子任务,并通过专门的LoRA模块进行微调。这种分解允许模型专注于学习每个角色的特定能力,从而提高整体性能并降低参数量。
技术框架:MoRAgent框架包含三个主要的LoRA模块,分别对应于推理者、执行者和总结者角色。推理者负责理解用户查询并决定下一步的操作;执行者负责选择合适的工具和参数来执行操作;总结者负责将执行结果总结并反馈给用户。这三个模块协同工作,共同完成Agent任务。为了训练这些模块,论文提出了一个多角色数据生成管道,用于生成角色特定的训练数据。
关键创新:MoRAgent的关键创新在于其混合角色(MoR)架构,该架构将Agent任务分解为多个角色,并为每个角色使用专门的LoRA模块进行微调。这种方法允许模型专注于学习每个角色的特定能力,从而提高整体性能并降低参数量。此外,论文还提出了一个多角色数据生成管道,用于生成高质量的训练数据。
关键设计:论文使用LoRA作为参数高效微调方法,LoRA通过引入低秩矩阵来更新预训练模型的权重,从而减少了需要训练的参数数量。论文为每个角色(推理者、执行者和总结者)都分配了一个独立的LoRA模块。此外,论文还设计了一个多角色数据生成管道,该管道包括角色特定的内容补全和可靠性验证步骤,以确保生成高质量的训练数据。具体的超参数设置和损失函数细节在论文中有详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MoRAgent在多个Agent基准测试中取得了显著的性能提升。例如,在某个基准测试中,MoRAgent的性能超过了全参数微调方法,同时参数量减少了多个数量级。消融研究也验证了每个角色的重要性以及多角色数据生成管道的有效性。具体的性能数据和提升幅度在论文中有详细描述(未知)。
🎯 应用场景
MoRAgent可应用于各种需要智能Agent的场景,例如智能客服、自动化办公、智能家居等。通过参数高效的微调,MoRAgent能够快速适应不同的任务需求,降低部署成本,并提升用户体验。该研究为构建更高效、更灵活的智能Agent系统提供了新的思路。
📄 摘要(原文)
Despite recent advancements of fine-tuning large language models (LLMs) to facilitate agent tasks, parameter-efficient fine-tuning (PEFT) methodologies for agent remain largely unexplored. In this paper, we introduce three key strategies for PEFT in agent tasks: 1) Inspired by the increasingly dominant Reason+Action paradigm, we first decompose the capabilities necessary for the agent tasks into three distinct roles: reasoner, executor, and summarizer. The reasoner is responsible for comprehending the user's query and determining the next role based on the execution trajectory. The executor is tasked with identifying the appropriate functions and parameters to invoke. The summarizer conveys the distilled information from conversations back to the user. 2) We then propose the Mixture-of-Roles (MoR) framework, which comprises three specialized Low-Rank Adaptation (LoRA) groups, each designated to fulfill a distinct role. By focusing on their respective specialized capabilities and engaging in collaborative interactions, these LoRAs collectively accomplish the agent task. 3) To effectively fine-tune the framework, we develop a multi-role data generation pipeline based on publicly available datasets, incorporating role-specific content completion and reliability verification. We conduct extensive experiments and thorough ablation studies on various LLMs and agent benchmarks, demonstrating the effectiveness of the proposed method. This project is publicly available at https://mor-agent.github.io.