Rethinking Sample Polarity in Reinforcement Learning with Verifiable Rewards
作者: Xinyu Tang, Yuliang Zhan, Zhixun Li, Wayne Xin Zhao, Zhenduo Zhang, Zujie Wen, Zhiqiang Zhang, Jun Zhou
分类: cs.CL
发布日期: 2025-12-25
💡 一句话要点
提出A3PO:一种自适应非对称token级优势塑造策略优化方法,提升基于可验证奖励的强化学习推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 大型推理模型 可验证奖励 策略优化 优势塑造
📋 核心要点
- 现有RLVR方法在训练大型推理模型时,对正负样本极性的影响缺乏深入理解,可能导致训练效率低下。
- 论文提出A3PO方法,通过自适应和非对称地调整token级别的优势值,更精确地引导模型学习。
- 实验结果表明,A3PO在多个推理基准上显著提升了模型的性能,验证了其有效性。
📝 摘要(中文)
大型推理模型(LRM)通常使用基于可验证奖励的强化学习(RLVR)进行训练,以增强其推理能力。在这种范式中,策略使用正向和负向的自生成rollout进行更新,这对应于不同的样本极性。本文系统地研究了这些样本极性如何影响RLVR的训练动态和行为。我们发现,正样本可以加强现有的正确推理模式,而负样本则鼓励探索新的推理路径。我们进一步探讨了在样本级别和token级别调整正样本和负样本的优势值如何影响RLVR训练。基于这些见解,我们提出了一种自适应和非对称的token级优势塑造策略优化方法,即A3PO,它更精确地将优势信号分配给不同极性的关键token。在五个推理基准上的实验证明了我们方法的有效性。
🔬 方法详解
问题定义:论文旨在解决在基于可验证奖励的强化学习(RLVR)中,如何更有效地利用正负样本来训练大型推理模型(LRM)的问题。现有方法对正负样本的极性影响理解不足,未能充分利用其各自的优势,导致训练效率和模型性能受限。
核心思路:论文的核心思路是区分正负样本在RLVR训练中的作用:正样本用于强化已有的正确推理路径,而负样本则用于鼓励探索新的推理路径。基于此,论文提出自适应地、非对称地调整正负样本在token级别的优势值,从而更精确地引导模型学习。
技术框架:A3PO方法的核心在于对策略梯度进行改进,使其能够根据token的重要性以及样本的极性,自适应地调整优势值。整体流程包括:1) 使用LRM生成正负样本的rollout;2) 使用可验证奖励函数对rollout进行评估;3) 计算每个token的优势值,并根据样本极性和token重要性进行调整;4) 使用调整后的优势值更新策略网络。
关键创新:A3PO的关键创新在于:1) 提出了正负样本极性对RLVR训练的不同影响的观点;2) 提出了自适应和非对称的token级别优势塑造方法,能够更精确地分配优势信号;3) 将优势塑造从样本级别细化到token级别,从而更精细地控制模型的学习过程。与现有方法相比,A3PO能够更有效地利用正负样本,提升模型的推理能力。
关键设计:A3PO的关键设计包括:1) 使用注意力机制来衡量token的重要性;2) 设计了自适应调整函数,根据token重要性和样本极性动态调整优势值;3) 使用非对称的学习率,对正负样本的梯度进行差异化处理。具体的损失函数是标准的策略梯度损失函数,但优势值经过了A3PO的调整。
🖼️ 关键图片
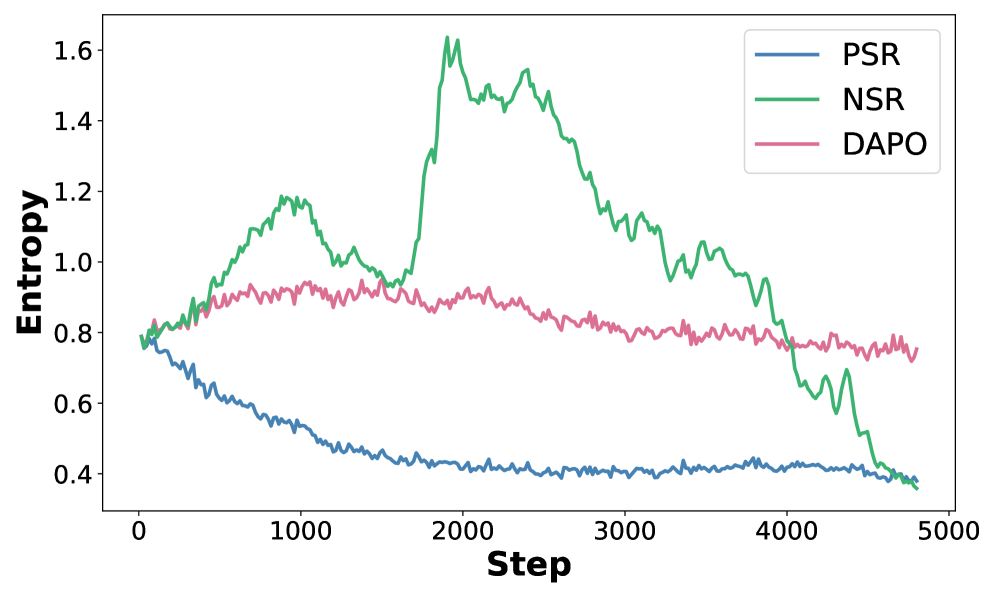
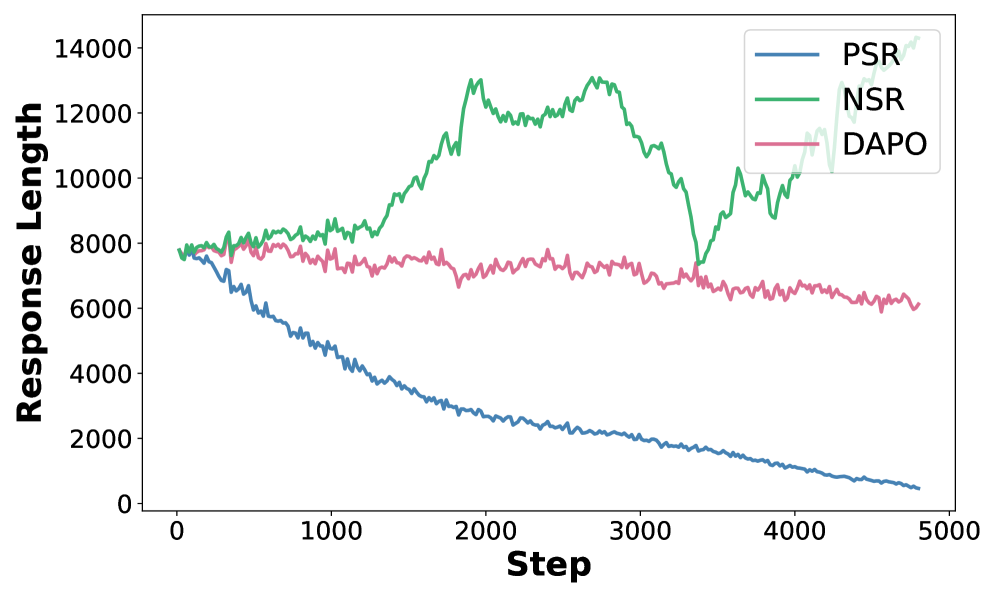
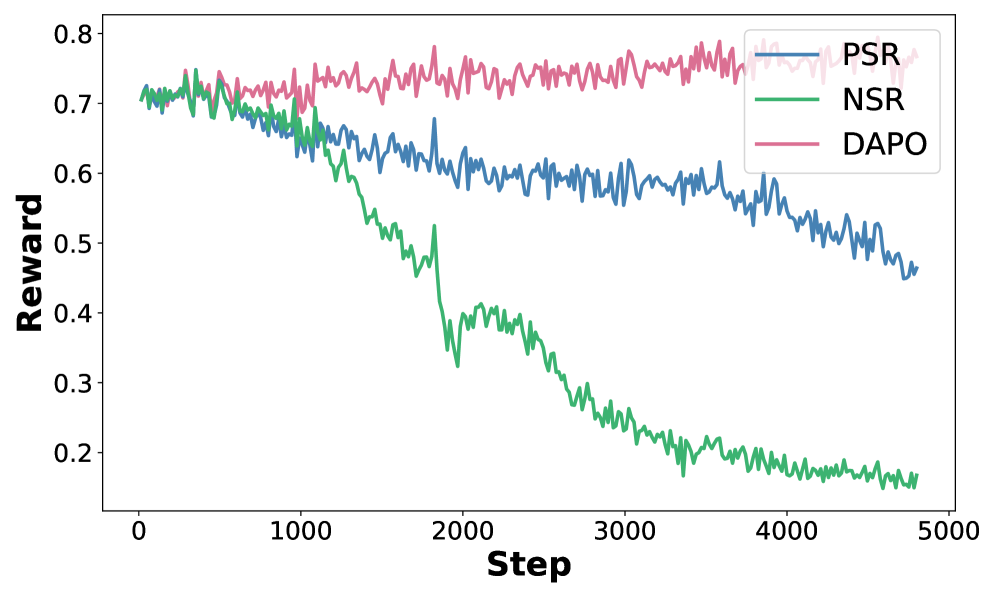
📊 实验亮点
实验结果表明,A3PO在五个推理基准上均取得了显著的性能提升。例如,在GSM8K数据集上,A3PO相比基线方法提升了超过5个百分点。此外,消融实验验证了自适应和非对称优势塑造策略的有效性。
🎯 应用场景
该研究成果可应用于各种需要复杂推理能力的场景,例如问答系统、代码生成、数学问题求解等。通过更有效地训练大型推理模型,可以提升这些应用在准确性、可靠性和效率方面的表现,从而在教育、科研、金融等领域发挥重要作用。
📄 摘要(原文)
Large reasoning models (LRMs) are typically trained using reinforcement learning with verifiable reward (RLVR) to enhance their reasoning abilities. In this paradigm, policies are updated using both positive and negative self-generated rollouts, which correspond to distinct sample polarities. In this paper, we provide a systematic investigation into how these sample polarities affect RLVR training dynamics and behaviors. We find that positive samples sharpen existing correct reasoning patterns, while negative samples encourage exploration of new reasoning paths. We further explore how adjusting the advantage values of positive and negative samples at both the sample level and the token level affects RLVR training. Based on these insights, we propose an Adaptive and Asymmetric token-level Advantage shaping method for Policy Optimization, namely A3PO, that more precisely allocates advantage signals to key tokens across different polarities. Experiments across five reasoning benchmarks demonstrate the effectiveness of our approach.