A Unified Definition of Hallucination: It's The World Model, Stupid!
作者: Emmy Liu, Varun Gangal, Chelsea Zou, Michael Yu, Xiaoqi Huang, Alex Chang, Zhuofu Tao, Karan Singh, Sachin Kumar, Steven Y. Feng
分类: cs.CL, cs.AI, cs.LG, stat.ML
发布日期: 2025-12-25 (更新: 2026-02-03)
备注: HalluWorld benchmark in progress. Repo at https://github.com/DegenAI-Labs/HalluWorld
💡 一句话要点
统一幻觉定义:核心在于语言模型对世界的建模能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 幻觉 语言模型 世界模型 知识库 自然语言处理
📋 核心要点
- 现有语言模型存在幻觉问题,即生成与事实或上下文不符的内容,严重影响模型的可信度。
- 论文提出将幻觉统一理解为语言模型对世界的建模不准确,并从用户可观察的角度进行定义。
- 论文计划构建一系列合成基准,利用完全指定的参考世界模型来评估和提升语言模型的世界建模能力。
📝 摘要(中文)
尽管自语言模型诞生以来,人们已经进行了无数次缓解幻觉的尝试,但即使在当今最先进的LLM中,幻觉仍然是一个持续存在的问题。本文回顾了现有的幻觉定义,并将它们整合为一个统一的定义,其中先前的定义都被包含在内。我们认为,可以通过简单地将其定义为不准确的(内部)世界建模来统一幻觉,这种形式对用户来说是可观察的。例如,陈述一个与知识库相矛盾的事实,或者产生一个与来源相矛盾的摘要。通过改变参考世界模型和冲突策略,我们的框架统一了先前的定义。我们认为,这种统一的观点是有用的,因为它迫使评估明确其假定的参考“世界”,区分了真正的幻觉与规划或奖励错误,并为跨基准的比较和缓解策略的讨论提供了一种通用语言。在此定义的基础上,我们概述了使用合成的、完全指定的参考世界模型来压力测试和改进世界建模组件的一系列基准的计划。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中普遍存在的“幻觉”问题,即模型生成不真实或与上下文不符的内容。现有方法通常针对特定类型的幻觉进行缓解,缺乏统一的理论框架,难以进行跨模型、跨任务的比较和分析。
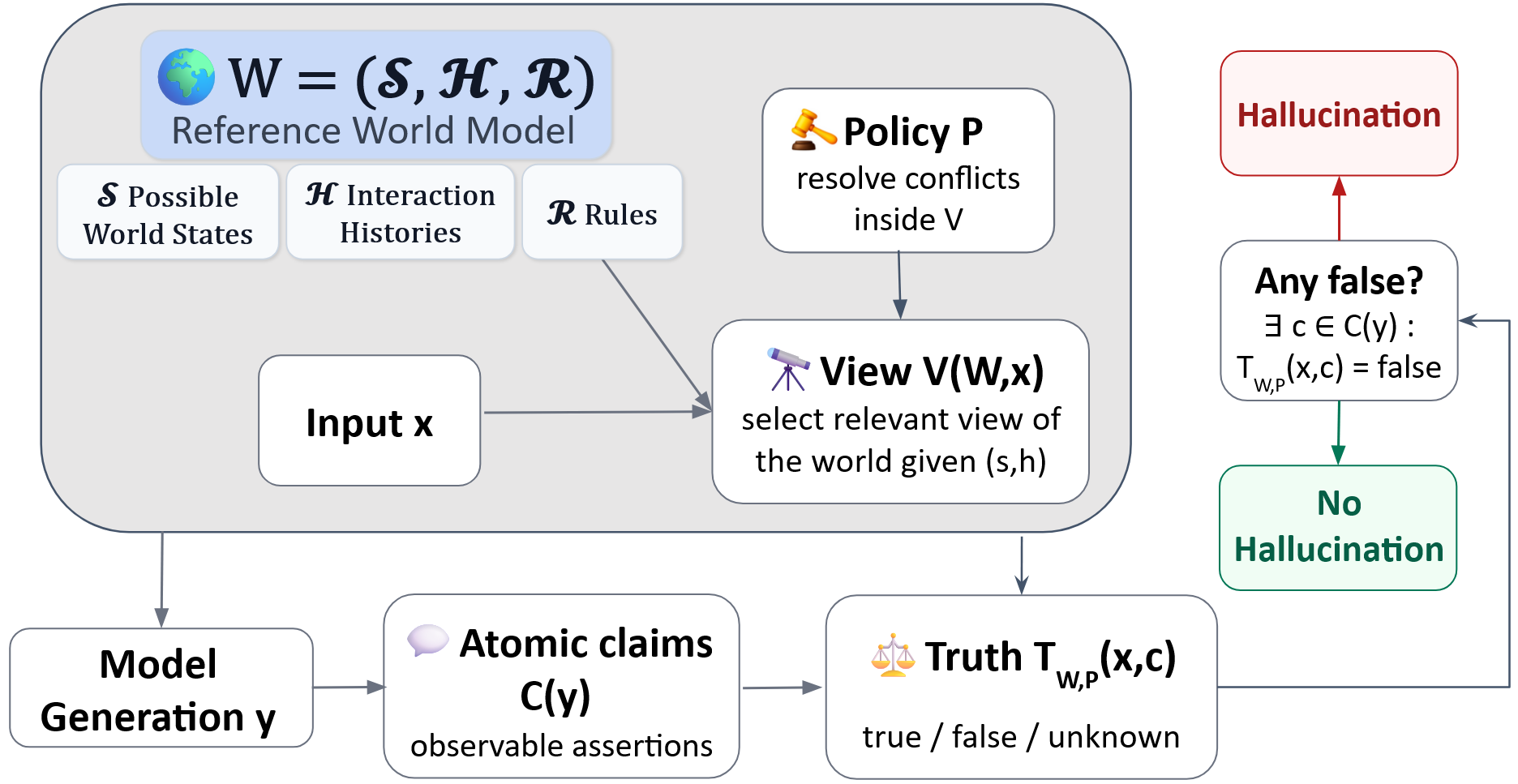
核心思路:论文的核心在于将幻觉定义为语言模型对“世界”建模的不准确。这里的“世界”可以指知识库、源文档、用户输入等。如果模型生成的输出与它所建模的“世界”相矛盾,则认为发生了幻觉。这种定义方式将各种类型的幻觉统一起来,并强调了世界模型的重要性。
技术框架:论文并没有提出具体的模型架构或训练方法,而是提出了一个概念框架。该框架包含以下几个关键要素:1) 参考世界模型:定义了模型应该遵循的“真实”世界;2) 模型输出:模型生成的文本;3) 冲突策略:定义了如何判断模型输出与参考世界模型是否矛盾。通过改变参考世界模型和冲突策略,可以定义不同类型的幻觉。
关键创新:论文最重要的创新在于提出了一个统一的幻觉定义,将各种类型的幻觉归结为世界建模的不准确。这种定义方式为幻觉的分析、评估和缓解提供了一个通用的框架。此外,论文还强调了世界模型的重要性,并提出了构建合成基准来评估和改进世界建模能力的计划。
关键设计:论文没有涉及具体的参数设置或网络结构。关键在于对“世界模型”的定义,以及如何设计冲突策略来判断模型输出是否与世界模型矛盾。未来的研究可以基于此框架,设计更有效的世界建模方法和幻觉检测算法。
🖼️ 关键图片

📊 实验亮点
论文提出了一个统一的幻觉定义框架,将各种类型的幻觉归结为世界建模的不准确。虽然没有提供具体的实验结果,但论文提出了构建合成基准来评估和改进世界建模能力的计划,为未来的研究方向提供了指导。该框架的价值在于为幻觉的分析、评估和缓解提供了一个通用的理论基础。
🎯 应用场景
该研究成果可应用于提升大型语言模型的可信度和可靠性,尤其是在需要高度准确性的场景,如医疗诊断、金融分析、法律咨询等。通过构建更准确的世界模型,可以减少模型产生幻觉的可能性,提高用户对模型的信任度。此外,该研究提出的统一幻觉定义,有助于不同研究团队之间的交流和合作,共同推动幻觉缓解技术的发展。
📄 摘要(原文)
Despite numerous attempts at mitigation since the inception of language models, hallucinations remain a persistent problem even in today's frontier LLMs. Why is this? We review existing definitions of hallucination and fold them into a single, unified definition wherein prior definitions are subsumed. We argue that hallucination can be unified by defining it as simply inaccurate (internal) world modeling, in a form where it is observable to the user. For example, stating a fact which contradicts a knowledge base OR producing a summary which contradicts the source. By varying the reference world model and conflict policy, our framework unifies prior definitions. We argue that this unified view is useful because it forces evaluations to clarify their assumed reference "world", distinguishes true hallucinations from planning or reward errors, and provides a common language for comparison across benchmarks and discussion of mitigation strategies. Building on this definition, we outline plans for a family of benchmarks using synthetic, fully specified reference world models to stress-test and improve world modeling components.