Morality is Contextual: Learning Interpretable Moral Contexts from Human Data with Probabilistic Clustering and Large Language Models
作者: Geoffroy Morlat, Marceau Nahon, Augustin Chartouny, Raja Chatila, Ismael T. Freire, Mehdi Khamassi
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-12-24
备注: 11 pages, 5 figures, +24 pages of Appendix
💡 一句话要点
COMETH框架通过概率聚类和LLM学习可解释的道德上下文,提升道德判断准确性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 道德判断 上下文学习 大型语言模型 概率聚类 可解释性AI
📋 核心要点
- 现有方法在道德判断中难以有效捕捉上下文信息,导致判断结果与人类认知存在偏差。
- COMETH框架结合概率上下文学习、LLM语义抽象和人类道德评估,学习可解释的道德上下文。
- 实验表明,COMETH框架在道德判断准确性上优于端到端LLM,并能揭示关键上下文特征。
📝 摘要(中文)
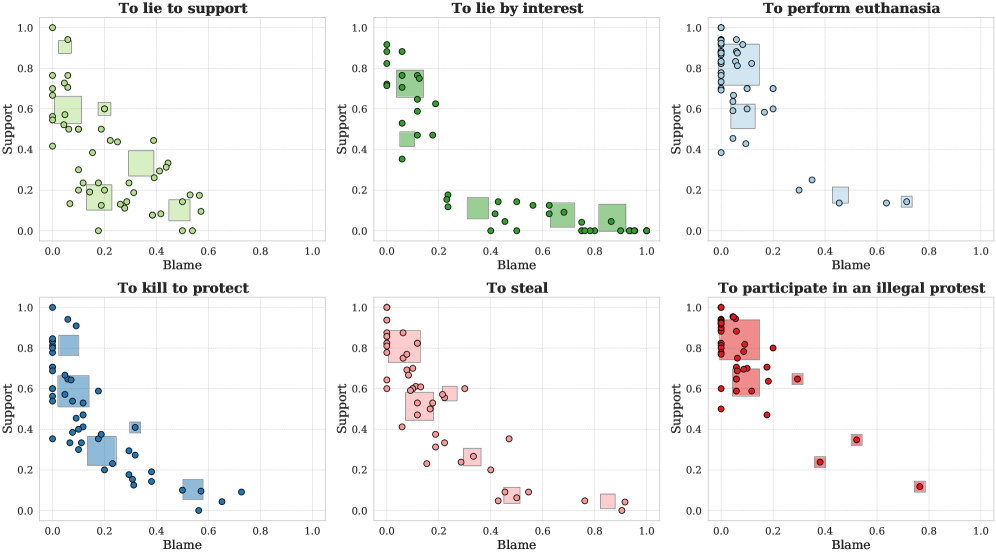
本文提出COMETH框架(Contextual Organization of Moral Evaluation from Textual Human inputs),该框架集成了概率上下文学习器、基于LLM的语义抽象和人类道德评估,以建模上下文如何影响模糊行为的可接受性。作者构建了一个基于经验的包含300个场景的数据集,涵盖六个核心行为(违反“不可杀人”、“不可欺骗”和“不可违法”)。从101名参与者收集了三元判断(责备/中立/支持)。预处理流程通过LLM过滤器和MiniLM嵌入与K-means标准化行为,产生稳健、可复现的核心行为聚类。COMETH然后通过使用原则性差异标准在线聚类来自人类判断分布的场景,学习特定于行为的道德上下文。为了泛化和解释预测,泛化模块提取简洁、非评价性的二元上下文特征,并在透明的基于似然的模型中学习特征权重。实验表明,相对于端到端LLM提示,COMETH与大多数人类判断的对齐度大致翻倍(平均约60% vs. 约30%),同时揭示了驱动其预测的上下文特征。贡献包括:(i)基于经验的道德上下文数据集,(ii)结合人类判断与基于模型的上下文学习和LLM语义的可复现的pipeline,以及(iii)用于上下文敏感的道德预测和解释的、可解释的端到端LLM替代方案。
🔬 方法详解
问题定义:现有方法,特别是直接使用大型语言模型(LLM)进行道德判断,往往忽略了上下文的重要性,导致判断结果与人类直觉不符。缺乏对道德场景中复杂上下文因素的有效建模和解释能力是主要痛点。
核心思路:COMETH的核心思路是将道德判断分解为两个阶段:首先,通过概率聚类学习不同行为的上下文;然后,利用LLM提取上下文特征,并学习这些特征对道德判断的影响。这种分解使得模型能够更好地理解和解释上下文对道德判断的影响。
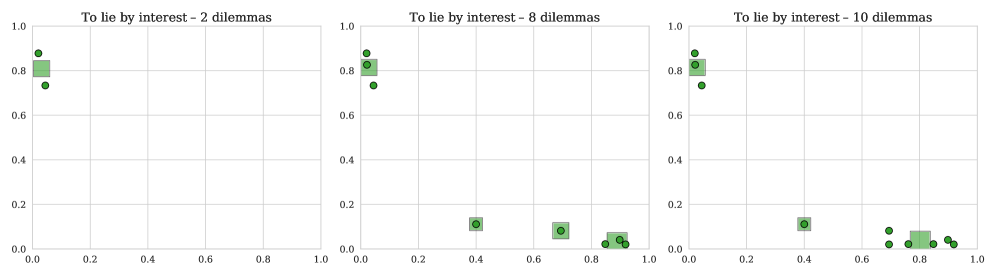
技术框架:COMETH框架包含以下主要模块:1) 数据收集与标注:构建包含道德场景的数据集,并收集人类的三元判断(责备/中立/支持)。2) 预处理:使用LLM过滤和MiniLM嵌入对行为进行标准化和聚类。3) 上下文学习:使用概率聚类方法,根据人类判断分布在线学习特定于行为的道德上下文。4) 泛化与解释:提取二元上下文特征,并学习特征权重,以解释预测结果。
关键创新:COMETH的关键创新在于结合了概率上下文学习和LLM语义抽象,以实现可解释的道德判断。与直接使用LLM进行端到端预测不同,COMETH通过显式地建模上下文,提高了判断的准确性和可解释性。
关键设计:在上下文学习阶段,COMETH使用基于差异标准的在线聚类方法,动态地学习道德上下文。在泛化与解释阶段,COMETH提取简洁的二元上下文特征,并使用基于似然的模型学习特征权重。具体参数设置和损失函数细节未在摘要中明确说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,COMETH框架在道德判断准确性上显著优于端到端LLM。COMETH与大多数人类判断的对齐度平均约为60%,而端到端LLM的对齐度仅为约30%。此外,COMETH能够揭示驱动其预测的关键上下文特征,提高了模型的可解释性。
🎯 应用场景
该研究成果可应用于机器人伦理、自动驾驶决策、法律推理等领域。通过理解和建模道德上下文,可以使AI系统在复杂情境下做出更符合人类价值观的决策,从而提高AI系统的可靠性和社会接受度。未来可用于开发更智能、更负责任的AI应用。
📄 摘要(原文)
Moral actions are judged not only by their outcomes but by the context in which they occur. We present COMETH (Contextual Organization of Moral Evaluation from Textual Human inputs), a framework that integrates a probabilistic context learner with LLM-based semantic abstraction and human moral evaluations to model how context shapes the acceptability of ambiguous actions. We curate an empirically grounded dataset of 300 scenarios across six core actions (violating Do not kill, Do not deceive, and Do not break the law) and collect ternary judgments (Blame/Neutral/Support) from N=101 participants. A preprocessing pipeline standardizes actions via an LLM filter and MiniLM embeddings with K-means, producing robust, reproducible core-action clusters. COMETH then learns action-specific moral contexts by clustering scenarios online from human judgment distributions using principled divergence criteria. To generalize and explain predictions, a Generalization module extracts concise, non-evaluative binary contextual features and learns feature weights in a transparent likelihood-based model. Empirically, COMETH roughly doubles alignment with majority human judgments relative to end-to-end LLM prompting (approx. 60% vs. approx. 30% on average), while revealing which contextual features drive its predictions. The contributions are: (i) an empirically grounded moral-context dataset, (ii) a reproducible pipeline combining human judgments with model-based context learning and LLM semantics, and (iii) an interpretable alternative to end-to-end LLMs for context-sensitive moral prediction and explanation.