Distilling the Essence: Efficient Reasoning Distillation via Sequence Truncation
作者: Wei-Rui Chen, Vignesh Kothapalli, Ata Fatahibaarzi, Hejian Sang, Shao Tang, Qingquan Song, Zhipeng Wang, Muhammad Abdul-Mageed
分类: cs.CL, cs.AI
发布日期: 2025-12-24 (更新: 2026-01-08)
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于序列截断的推理蒸馏方法,提升小模型推理效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 推理模型 序列截断 计算效率 思维链
📋 核心要点
- 现有知识蒸馏方法在长推理序列上计算成本高昂,效率低下。
- 通过分析不同部分的重要性,提出序列截断策略,减少计算量。
- 实验表明,截断序列能显著降低计算成本,同时保持较高的性能。
📝 摘要(中文)
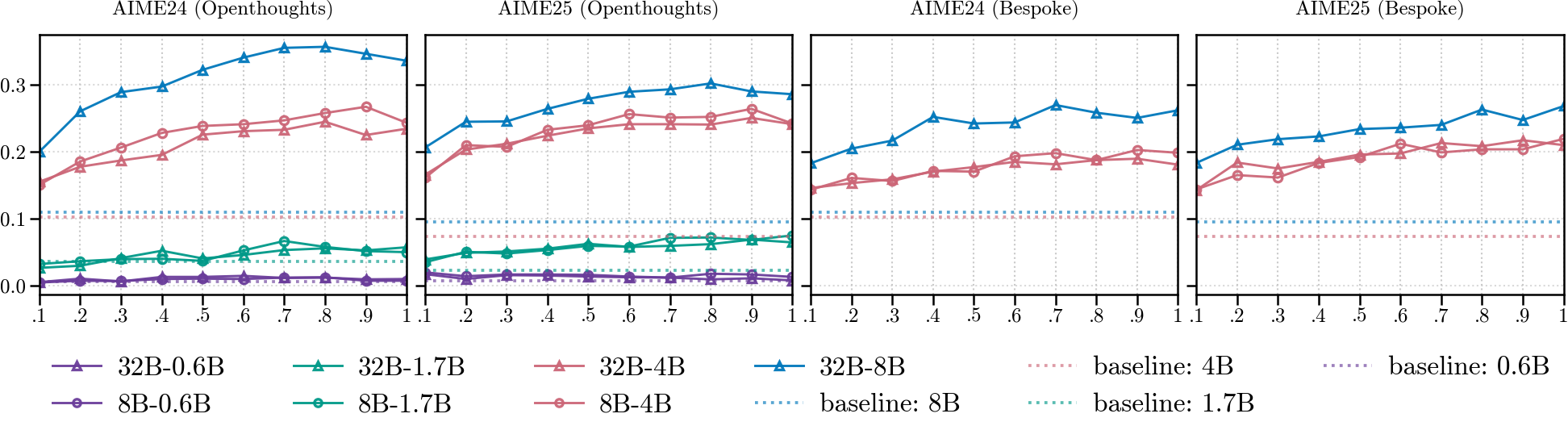
将大型推理模型(LRM)的能力蒸馏到较小的学生模型通常需要在大量的推理数据上进行训练。然而,在包含提示(P)、思维链(CoT)和答案(A)部分的长序列上进行知识蒸馏(KD)使得计算成本非常高昂。本文研究了在不同部分(P, CoT, A)上分配监督信号如何影响学生模型的性能。分析表明,当提示和答案信息包含在CoT中时,仅对CoT token进行选择性KD是有效的。基于此,本文建立了一个截断协议,以量化计算量-质量之间的权衡关系,作为序列长度的函数。观察到,超过特定长度后,更长的训练序列对下游性能的收益递减,但需要更高的内存和FLOPs。因此,仅在每个训练序列的前50%的token上进行训练,平均可以保留数学基准上完整序列性能的约91%,同时将训练时间、内存使用和FLOPs减少约50%。
🔬 方法详解
问题定义:论文旨在解决将大型推理模型(LRM)的知识高效地迁移到小型学生模型的问题。现有知识蒸馏方法在处理包含提示(Prompt)、思维链(Chain-of-Thought)和答案(Answer)的长序列时,计算成本非常高,限制了其在资源受限环境中的应用。现有方法没有充分考虑序列中不同部分对学生模型学习的重要性,导致计算资源的浪费。
核心思路:论文的核心思路是,通过分析推理序列中不同部分(Prompt、CoT、Answer)对学生模型性能的影响,发现CoT部分包含了关键的推理信息。因此,可以通过截断序列,仅保留CoT部分或者CoT的前半部分进行知识蒸馏,从而在保证性能的同时,显著降低计算成本。这种方法的核心在于,减少不必要的计算,专注于对学生模型学习最有价值的信息。
技术框架:论文提出的技术框架主要包含以下几个步骤:1) 分析不同部分(P、CoT、A)对学生模型性能的影响;2) 建立序列截断协议,通过调整截断长度,量化计算量和模型性能之间的权衡关系;3) 在截断后的序列上进行知识蒸馏,训练学生模型。整体流程简单有效,易于实现。
关键创新:论文的关键创新在于提出了基于序列截断的知识蒸馏方法,该方法能够显著降低计算成本,同时保持较高的模型性能。与传统的知识蒸馏方法相比,该方法更加高效,适用于资源受限的环境。通过分析不同部分的重要性,有针对性地进行知识蒸馏,避免了对不重要信息的过度计算。
关键设计:论文的关键设计在于截断比例的选择。实验表明,截断序列的前50%能够保留约91%的完整序列性能,同时将计算成本降低约50%。具体的截断比例可以根据实际应用场景进行调整,以达到最佳的计算量-性能权衡。论文没有详细描述损失函数和网络结构的具体设置,但强调了CoT部分的重要性,暗示可以使用针对CoT部分的特殊损失函数或网络结构。
🖼️ 关键图片


📊 实验亮点
实验结果表明,仅使用训练序列的前50%进行训练,可以在数学基准上保留完整序列性能的约91%,同时将训练时间、内存使用和FLOPs降低约50%。这表明该方法能够在显著降低计算成本的同时,保持较高的模型性能。
🎯 应用场景
该研究成果可应用于各种需要将大型推理模型知识迁移到小型模型的场景,例如移动设备上的智能助手、边缘计算设备上的自然语言处理应用等。通过降低计算成本,使得在资源受限的环境中部署复杂的推理模型成为可能,具有广泛的应用前景。
📄 摘要(原文)
Distilling the capabilities from a large reasoning model (LRM) to a smaller student model often involves training on substantial amounts of reasoning data. However, knowledge distillation (KD) over lengthy sequences with prompt (P), chain-of-thought (CoT), and answer (A) sections makes the process computationally expensive. In this work, we investigate how the allocation of supervision across different sections (P, CoT, A) affects student performance. Our analysis shows that selective KD over only the CoT tokens can be effective when the prompt and answer information is encompassed by it. Building on this insight, we establish a truncation protocol to quantify computation-quality tradeoffs as a function of sequence length. We observe that beyond a specific length, longer training sequences provide marginal returns for downstream performance but require substantially higher memory and FLOPs. To this end, training on only the first $50\%$ of tokens of every training sequence can retain, on average, $\approx91\%$ of full-sequence performance on math benchmarks while reducing training time, memory usage, and FLOPs by about $50\%$ each. Codes are available at https://github.com/weiruichen01/distilling-the-essence.