NVIDIA Nemotron 3: Efficient and Open Intelligence
作者: NVIDIA, :, Aaron Blakeman, Aaron Grattafiori, Aarti Basant, Abhibha Gupta, Abhinav Khattar, Adi Renduchintala, Aditya Vavre, Akanksha Shukla, Akhiad Bercovich, Aleksander Ficek, Aleksandr Shaposhnikov, Alex Kondratenko, Alexander Bukharin, Alexandre Milesi, Ali Taghibakhshi, Alisa Liu, Amelia Barton, Ameya Sunil Mahabaleshwarkar, Amir Klein, Amit Zuker, Amnon Geifman, Amy Shen, Anahita Bhiwandiwalla, Andrew Tao, Anjulie Agrusa, Ankur Verma, Ann Guan, Anubhav Mandarwal, Arham Mehta, Ashwath Aithal, Ashwin Poojary, Asif Ahamed, Asit Mishra, Asma Kuriparambil Thekkumpate, Ayush Dattagupta, Banghua Zhu, Bardiya Sadeghi, Barnaby Simkin, Ben Lanir, Benedikt Schifferer, Besmira Nushi, Bilal Kartal, Bita Darvish Rouhani, Boris Ginsburg, Brandon Norick, Brandon Soubasis, Branislav Kisacanin, Brian Yu, Bryan Catanzaro, Carlo del Mundo, Chantal Hwang, Charles Wang, Cheng-Ping Hsieh, Chenghao Zhang, Chenhan Yu, Chetan Mungekar, Chintan Patel, Chris Alexiuk, Christopher Parisien, Collin Neale, Cyril Meurillon, Damon Mosk-Aoyama, Dan Su, Dane Corneil, Daniel Afrimi, Daniel Lo, Daniel Rohrer, Daniel Serebrenik, Daria Gitman, Daria Levy, Darko Stosic, David Mosallanezhad, Deepak Narayanan, Dhruv Nathawani, Dima Rekesh, Dina Yared, Divyanshu Kakwani, Dong Ahn, Duncan Riach, Dusan Stosic, Edgar Minasyan, Edward Lin, Eileen Long, Eileen Peters Long, Elad Segal, Elena Lantz, Ellie Evans, Elliott Ning, Eric Chung, Eric Harper, Eric Tramel, Erick Galinkin, Erik Pounds, Evan Briones, Evelina Bakhturina, Evgeny Tsykunov, Faisal Ladhak, Fay Wang, Fei Jia, Felipe Soares, Feng Chen, Ferenc Galko, Frank Sun, Frankie Siino, Gal Hubara Agam, Ganesh Ajjanagadde, Gantavya Bhatt, Gargi Prasad, George Armstrong, Gerald Shen, Gorkem Batmaz, Grigor Nalbandyan, Haifeng Qian, Harsh Sharma, Hayley Ross, Helen Ngo, Herbert Hum, Herman Sahota, Hexin Wang, Himanshu Soni, Hiren Upadhyay, Huizi Mao, Huy C Nguyen, Huy Q Nguyen, Iain Cunningham, Ido Galil, Ido Shahaf, Igor Gitman, Ilya Loshchilov, Itamar Schen, Itay Levy, Ivan Moshkov, Izik Golan, Izzy Putterman, Jan Kautz, Jane Polak Scowcroft, Jared Casper, Jatin Mitra, Jeffrey Glick, Jenny Chen, Jesse Oliver, Jian Zhang, Jiaqi Zeng, Jie Lou, Jimmy Zhang, Jinhang Choi, Jining Huang, Joey Conway, Joey Guman, John Kamalu, Johnny Greco, Jonathan Cohen, Joseph Jennings, Joyjit Daw, Julien Veron Vialard, Junkeun Yi, Jupinder Parmar, Kai Xu, Kan Zhu, Kari Briski, Katherine Cheung, Katherine Luna, Keith Wyss, Keshav Santhanam, Kevin Shih, Kezhi Kong, Khushi Bhardwaj, Kirthi Shankar, Krishna C. Puvvada, Krzysztof Pawelec, Kumar Anik, Lawrence McAfee, Laya Sleiman, Leon Derczynski, Li Ding, Lizzie Wei, Lucas Liebenwein, Luis Vega, Maanu Grover, Maarten Van Segbroeck, Maer Rodrigues de Melo, Mahdi Nazemi, Makesh Narsimhan Sreedhar, Manoj Kilaru, Maor Ashkenazi, Marc Romeijn, Marcin Chochowski, Mark Cai, Markus Kliegl, Maryam Moosaei, Matt Kulka, Matvei Novikov, Mehrzad Samadi, Melissa Corpuz, Mengru Wang, Meredith Price, Michael Andersch, Michael Boone, Michael Evans, Miguel Martinez, Mikail Khona, Mike Chrzanowski, Minseok Lee, Mohammad Dabbah, Mohammad Shoeybi, Mostofa Patwary, Nabin Mulepati, Najeeb Nabwani, Natalie Hereth, Nave Assaf, Negar Habibi, Neta Zmora, Netanel Haber, Nicola Sessions, Nidhi Bhatia, Nikhil Jukar, Nikki Pope, Nikolai Ludwig, Nima Tajbakhsh, Nir Ailon, Nirmal Juluru, Nishant Sharma, Oleksii Hrinchuk, Oleksii Kuchaiev, Olivier Delalleau, Oluwatobi Olabiyi, Omer Ullman Argov, Omri Puny, Oren Tropp, Ouye Xie, Parth Chadha, Pasha Shamis, Paul Gibbons, Pavlo Molchanov, Pawel Morkisz, Peter Dykas, Peter Jin, Pinky Xu, Piotr Januszewski, Pranav Prashant Thombre, Prasoon Varshney, Pritam Gundecha, Przemek Tredak, Qing Miao, Qiyu Wan, Rabeeh Karimi Mahabadi, Rachit Garg, Ran El-Yaniv, Ran Zilberstein, Rasoul Shafipour, Rich Harang, Rick Izzo, Rima Shahbazyan, Rishabh Garg, Ritika Borkar, Ritu Gala, Riyad Islam, Robert Hesse, Roger Waleffe, Rohit Watve, Roi Koren, Ruoxi Zhang, Russell Hewett, Russell J. Hewett, Ryan Prenger, Ryan Timbrook, Sadegh Mahdavi, Sahil Modi, Samuel Kriman, Sangkug Lim, Sanjay Kariyappa, Sanjeev Satheesh, Saori Kaji, Satish Pasumarthi, Saurav Muralidharan, Sean Narentharen, Sean Narenthiran, Seonmyeong Bak, Sergey Kashirsky, Seth Poulos, Shahar Mor, Shanmugam Ramasamy, Shantanu Acharya, Shaona Ghosh, Sharath Turuvekere Sreenivas, Shelby Thomas, Shiqing Fan, Shreya Gopal, Shrimai Prabhumoye, Shubham Pachori, Shubham Toshniwal, Shuoyang Ding, Siddharth Singh, Simeng Sun, Smita Ithape, Somshubra Majumdar, Soumye Singhal, Stas Sergienko, Stefania Alborghetti, Stephen Ge, Sugam Dipak Devare, Sumeet Kumar Barua, Suseella Panguluri, Suyog Gupta, Sweta Priyadarshi, Syeda Nahida Akter, Tan Bui, Teodor-Dumitru Ene, Terry Kong, Thanh Do, Tijmen Blankevoort, Tim Moon, Tom Balough, Tomer Asida, Tomer Bar Natan, Tomer Ronen, Tugrul Konuk, Twinkle Vashishth, Udi Karpas, Ushnish De, Vahid Noorozi, Vahid Noroozi, Venkat Srinivasan, Venmugil Elango, Victor Cui, Vijay Korthikanti, Vinay Rao, Vitaly Kurin, Vitaly Lavrukhin, Vladimir Anisimov, Wanli Jiang, Wasi Uddin Ahmad, Wei Du, Wei Ping, Wenfei Zhou, Will Jennings, William Zhang, Wojciech Prazuch, Xiaowei Ren, Yashaswi Karnati, Yejin Choi, Yev Meyer, Yi-Fu Wu, Yian Zhang, Yigong Qin, Ying Lin, Yonatan Geifman, Yonggan Fu, Yoshi Subara, Yoshi Suhara, Yubo Gao, Zach Moshe, Zhen Dong, Zhongbo Zhu, Zihan Liu, Zijia Chen, Zijie Yan
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-12-24
💡 一句话要点
NVIDIA Nemotron 3:高效开放的智能模型家族,支持百万token上下文
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 大型语言模型 混合专家模型 Mamba架构 Transformer架构 强化学习 长上下文 工具使用
📋 核心要点
- 现有大型语言模型在长上下文推理和工具使用方面存在挑战,难以有效支持复杂任务。
- Nemotron 3模型家族采用混合专家Mamba-Transformer架构,并结合LatentMoE和多环境强化学习,提升模型性能。
- 实验表明,Nemotron 3模型在准确性、推理能力和吞吐量方面均表现出色,尤其是在长上下文任务中。
📝 摘要(中文)
本文介绍了Nemotron 3模型家族——Nano、Super和Ultra。这些模型具有强大的代理、推理和对话能力。Nemotron 3家族采用混合专家(Mixture-of-Experts)的Mamba-Transformer架构,提供一流的吞吐量和高达100万token的上下文长度。Super和Ultra模型采用NVFP4训练,并结合了LatentMoE,这是一种提高模型质量的新方法。两个较大的模型还包括MTP层,以加快文本生成速度。所有Nemotron 3模型都经过多环境强化学习的后训练,从而实现推理、多步骤工具使用和支持细粒度的推理预算控制。最小的模型Nano在保持极具成本效益的推理的同时,在准确性方面优于同类模型。Super针对协作代理和大量工作负载(如IT服务单自动化)进行了优化。最大的模型Ultra提供最先进的准确性和推理性能。Nano及其技术报告和本白皮书一同发布,Super和Ultra将在未来几个月内发布。我们将公开模型权重、预训练和后训练软件、配方以及我们拥有重新分发权的所有数据。
🔬 方法详解
问题定义:现有的大型语言模型在处理长上下文信息时面临挑战,例如推理能力下降、计算成本增加等。此外,如何使模型更好地进行工具使用和多步骤推理也是一个重要问题。现有方法在这些方面存在不足,难以满足实际应用需求。
核心思路:Nemotron 3模型家族的核心思路是结合Mamba和Transformer架构的优势,利用混合专家模型提高模型容量和效率,并通过多环境强化学习提升模型的推理和工具使用能力。LatentMoE的引入进一步提升了模型质量。
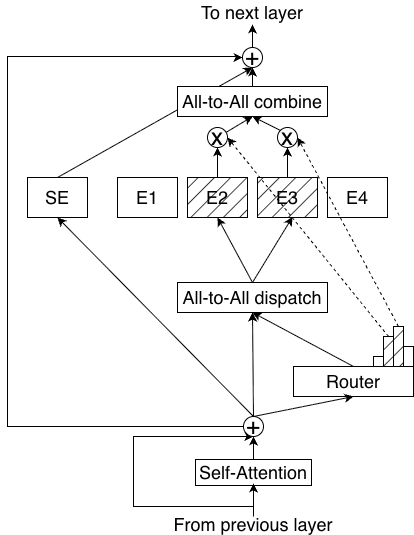
技术框架:Nemotron 3模型家族包含Nano、Super和Ultra三个模型。它们都基于混合专家Mamba-Transformer架构。Super和Ultra模型采用NVFP4训练,并包含LatentMoE和MTP层。所有模型都经过多环境强化学习的后训练。整体流程包括预训练、LatentMoE训练、MTP层添加(Super和Ultra)、多环境强化学习后训练等阶段。
关键创新:Nemotron 3的关键创新点在于混合专家Mamba-Transformer架构、LatentMoE以及多环境强化学习的结合。Mamba架构擅长处理长序列,Transformer架构擅长建模全局关系,混合使用可以兼顾两者的优点。LatentMoE通过学习潜在的专家选择,提高了模型质量。多环境强化学习则使模型能够更好地适应不同的任务和环境。
关键设计:Nemotron 3模型家族的关键设计包括:1) 混合专家Mamba-Transformer架构的具体实现细节,例如Mamba和Transformer层的比例、连接方式等;2) LatentMoE的训练方法和损失函数;3) 多环境强化学习的奖励函数设计和环境选择策略;4) NVFP4的使用细节;5) MTP层的具体结构和训练方法。
🖼️ 关键图片


📊 实验亮点
Nemotron 3 Nano模型在准确性方面优于同类模型,同时保持了极高的推理效率。Super模型针对协作代理和高吞吐量工作负载进行了优化。Ultra模型在准确性和推理性能方面达到了最先进水平,尤其是在长上下文任务中表现出色。具体性能数据将在后续发布的报告中提供。
🎯 应用场景
Nemotron 3模型家族可广泛应用于智能代理、对话系统、IT服务单自动化、代码生成、内容创作等领域。其强大的推理能力和长上下文处理能力使其能够胜任复杂的任务,例如多步骤工具使用、知识图谱推理等。该研究有望推动人工智能在各行业的应用,提高生产效率和用户体验。
📄 摘要(原文)
We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.